AWS Compute Blog

Author: James Beswick
James Beswick leads the Serverless Developer Advocacy team at AWS. He works with AWS's developer customers to understand how serverless technologies can drastically change the way they think about building and running applications at massive scale with minimal administration overhead. Visit https://serverlessland.com for more serverless content.

Creating a single-table design with Amazon DynamoDB
This post looks at implementing common relational database patterns using DynamoDB. Instead of using multiple tables, the single-table design pattern can use adjacency lists to provide many-to-many relational functionality.
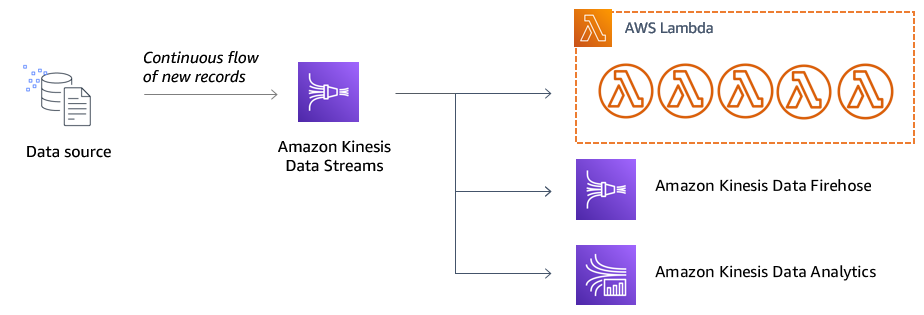
Understanding data streaming concepts for serverless applications
In this post, I introduce some of the core streaming concepts for serverless applications. I explain some of the benefits of streaming architectures and how Kinesis works with producers and consumers. I compare different ways to ingest data, how streams are composed of shards, and how partition keys determine which shard is used. Finally, I explain the payload formats at the different stages of a streaming workload, how message ordering works with shards, and why idempotency is important to handle.

Developing evolutionary architecture with AWS Lambda
This post shows how you can evolve a workload using hexagonal architecture. It explains how to add new functionality, change underlying infrastructure, or port the code base between different compute solutions. The main characteristics enabling this are loose coupling and strong encapsulation.

Translating content dynamically by using Amazon S3 Object Lambda
This blog post shows how you can use S3 Object Lambda with Amazon Translate to simplify dynamic content translation by using a data driven approach. With user-provided data as arguments, you can dynamically transform content in S3 and generate a new object.

ICYMI: Serverless Q2 2021
A review of everything that happened in AWS Serverless in Q2 2021.

Monitoring and troubleshooting serverless data analytics applications
In this post, I show how the existing settings in the Alleycat application are not sufficient for handling the expected amount of traffic. I walk through the metrics visualizations for Kinesis Data Streams, Lambda, and DynamoDB to find which quotas should be increased.

Building leaderboard functionality with serverless data analytics
In this post, I explain the all-time leaderboard logic in the Alleycat application. This is an asynchronous, eventually consistent process that checks batching of incoming records for new personal records. This uses Kinesis Data Firehose to provide a zero-administration way to deliver and process large batches of records continuously.

Building serverless applications with streaming data: Part 3
In this post, I explain the all-time leaderboard logic in the Alleycat application. This is an asynchronous, eventually consistent process that checks batching of incoming records for new personal records. This uses Kinesis Data Firehose to provide a zero-administration way to deliver and process large batches of records continuously.

Announcing migration of the Java 8 runtime in AWS Lambda to Amazon Corretto
Beginning July 19, 2021, the Java 8 managed runtime in AWS Lambda will migrate from the current Open Java Development Kit (OpenJDK) implementation to the latest Amazon Corretto implementation.

Building serverless applications with streaming data: Part 2
This post focuses on ingesting data into Kinesis Data Streams. I explain the two approaches used by the Alleycat frontend and the simulator application and highlight other approaches that you can use. I show how messages are routed to shards using partition keys. Finally, I explore additional factors to consider when ingesting data, to improve efficiency and reduce cost.