亚马逊AWS官方博客
使用 Kafka Connect 将您现有的 Kafka 集群与 Kinesis 集成
一、背景介绍
随着流式数据的广泛使用,越来越多的客户希望通过Amazon Kinesis来进行流式数据的收集、处理和分析,并根据实时分析结果及时作出及时的业务响应。Amazon Kinesis 提供多种核心功能,可以经济高效地处理任意规模的流数据,同时具有很高的灵活性。
如果您希望通过Amazon Kinesis来进行数据收集和分析,但是应用开发已经完成或上线,且应用中使用了Kafka集群,那么本篇博客将带领您通过Kafka Connect轻松的将现有Kafka集群中的数据传输到Kinesis中。
Kafka Connect是一种用于在Kafka和其他系统之间可扩展的、可靠的流式传输数据的工具。它使得大量数据集移入和移出Kafka变得简单,且Kafka Connect Kinesis使得数据在开源工具和AWS托管服务之间的流转更加顺畅。通过Kafka Connect Kinesis您可以轻松的构建您云上的数据湖(S3)和数据分析应用(Amazon Elasticsearch Service),并进一步深入使用其他的AWS的托管服务。
二、Kafka Connect Kinesis使用指南
本文讲述如何通过使用Kafka Connect Kinesis将您的MSK-Amazon Managed Streaming for Apache Kafka集群(或Kafka集群)中的数据,通过Kafka Connect Kinesis传输到Kinesis Firehose中。并通过Firehose对数据进行格式转换和聚合,并且最终加密存储在S3上。

三、详细步骤
本文中的实验环境在Tokyo区域,需要用的服务是MSK, Kinesis,Glue, S3, EC2。
先决条件
- 一个 MSK集群。
- 一个用于存储数据的S3桶,本例中我们命名为my-poc-connector-bucket
详细步骤
1. 创建一个EC2,并为当前EC2添加role。
1.1通过Console创建一个EC2作为您的Kafka Connect Kinesis的运行服务器。EC2的配置需要注意以下几点:
- 您的EC2需要和MSK处于同一个VPC中。
- EC2的安全组需要与您的MSK集群的安全组互通。
1.2 为该EC2创建一个IAM role,这个role需要有对MSK、Kinesis和S3的访问权限,并且把这个角色添加给EC2。
1.3 更为详尽的Kafka client配置方法请参考:https://docs.thinkwithwp.com/msk/latest/developerguide/create-client-machine.html
2. 在EC2上下载Kafka安装包
您可以通过http://kafka.apache.org/downloads来下载相应的Kafka安装包,本例中我们选择的版本是kafka_2.12-2.2.1。安装后请将Kafka解压,在本例中,我们的目录结构如下:

3. 下载并解压Kafka Connect Kinesis
在您的EC2下载并解压Kafka Connect Kinesis,并放置在Kafka的同级目录下。本例中Kafka Connect Kinesis放置于/home/ec2-user/confluentinc-kafka-connect-kinesis-1.1.4 目录下。
4. 创建Glue Table
4.1 选择手动增加Glue table
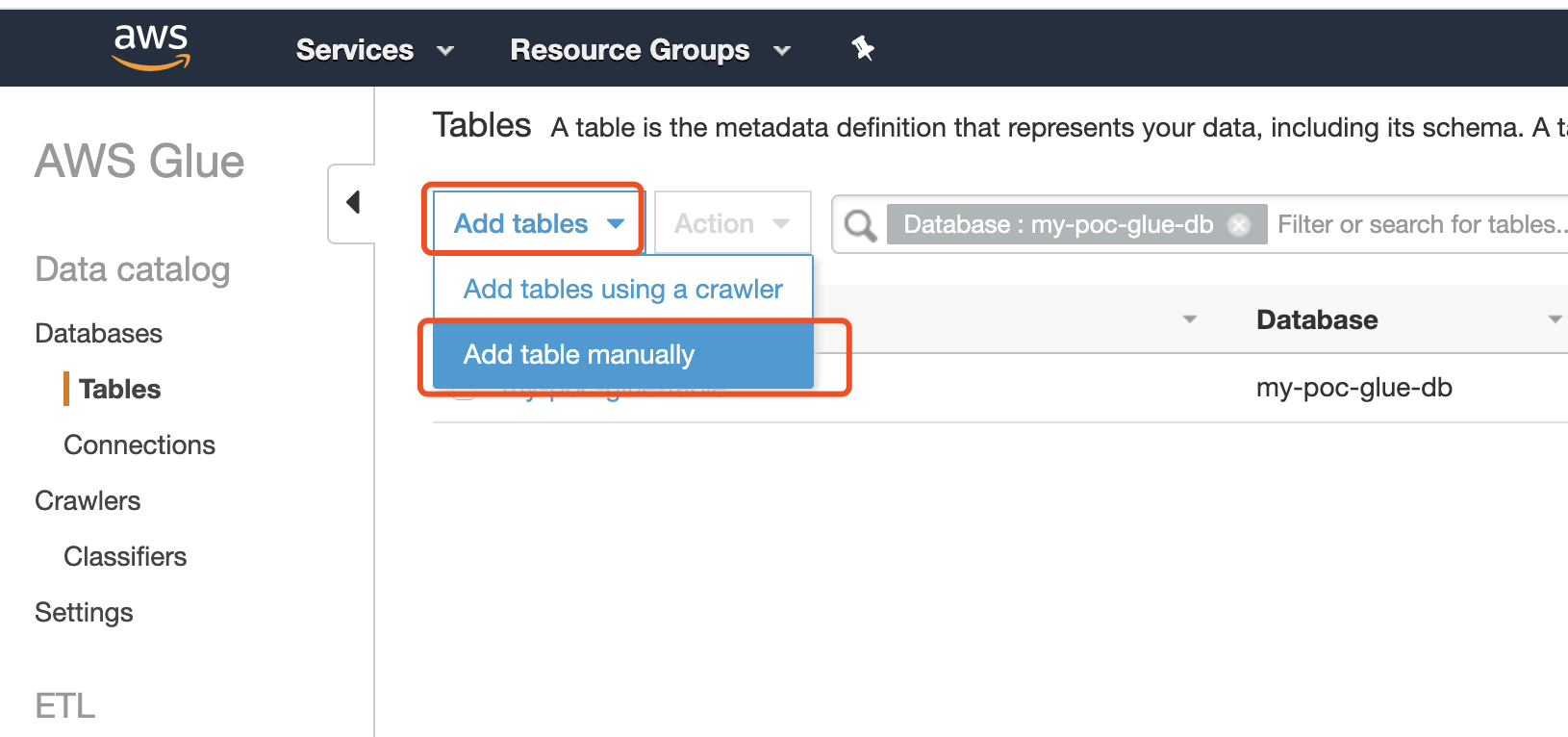
4.2 选择我们已经创建好的用于存储数据的S3桶

4.3 随后选择数据格式,本例中我们选择Parquet。

4.4 根据自己的需求定义表结构,并完成库表的创建。

5.在Console中创建Firehose资源
5.1 在创建Firehose时可以指定数据的转换格式,并选取相应的Glue table。
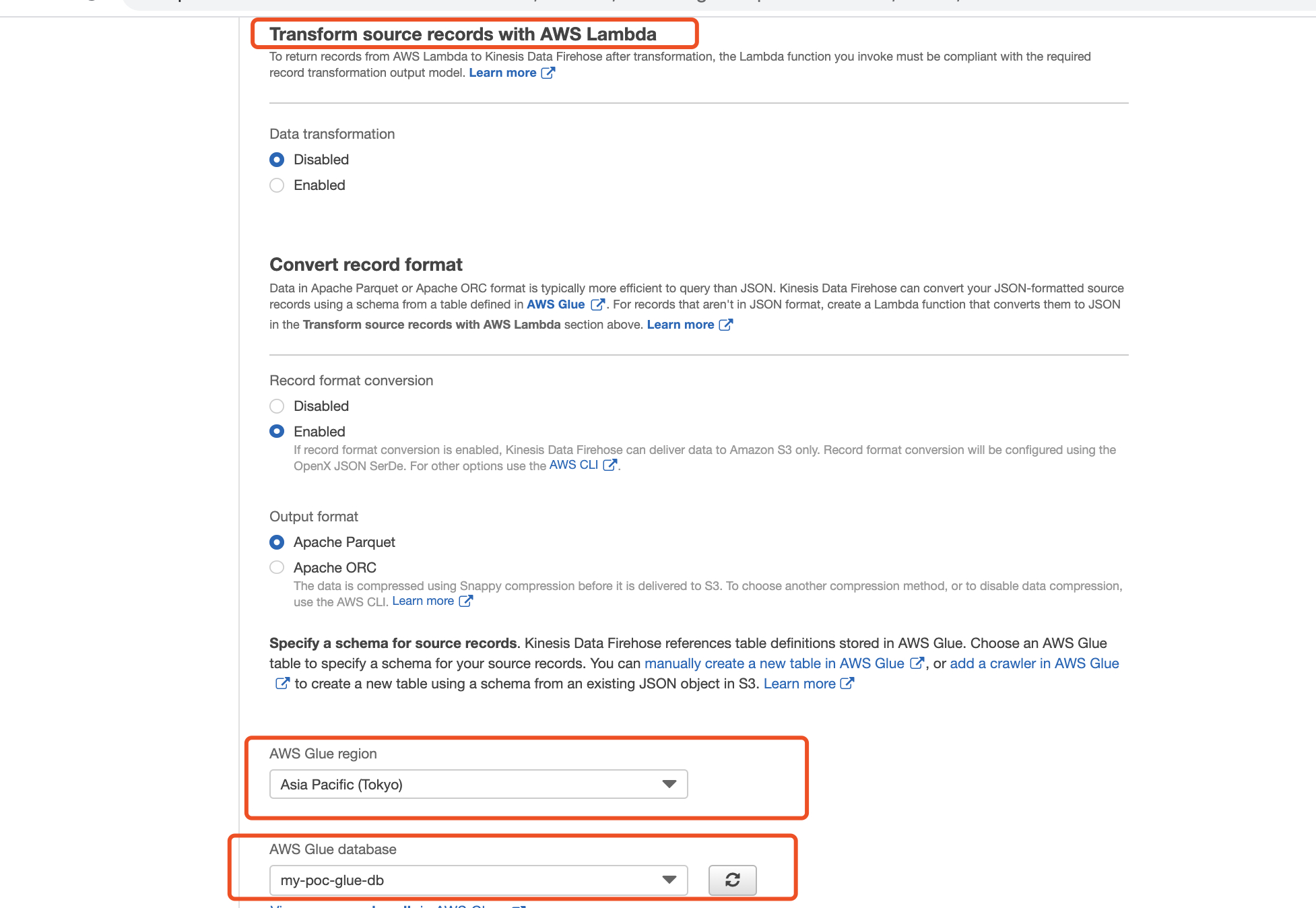
5.2 选择数据的输出位置

5.3 选择数据输出的时间间隔或者缓存大小

5.4 给Firehose赋予相应的权限,您可以直接点击创建或者选择角色,如果您是在Console中创建,那么Console会自动帮您生成相应的角色名称以及策略。完成IAM角色的创建,并根据引导完成Firehose的创建。

6. 下载kinesis-kafka-connector,并修改相应的配置文件
您可以在GitHub上找到开源项目kinesis-kafka-connector,这个项目包含两部分主要内容:

- 启动Kafka Connect Kinesis所需的配置文件,路径:https://github.com/awslabs/kinesis-kafka-connector/tree/master/config
- kinesis-kafka-connector的源码https://github.com/awslabs/kinesis-kafka-connector/tree/master/src
6.1 修改kinesis-firehose-kafka-connector.properties配置文件,根据实际情况填写app名称, firehose名称,region等内容。

6.2 修改worker.properties配置文件,根据实际情况bootstrap.servers。
- 您可以通过在EC2 client上运行 aws kafka get-bootstrap-brokers –region your-region-code –cluster-arn “your-cluster-arn” 来获取您的servers
- 修改path参数,本例中plugin.path即为Kafka Connect Kinesis的解压路径:/home/ec2-user/confluentinc-kafka-connect-kinesis-1.1.4
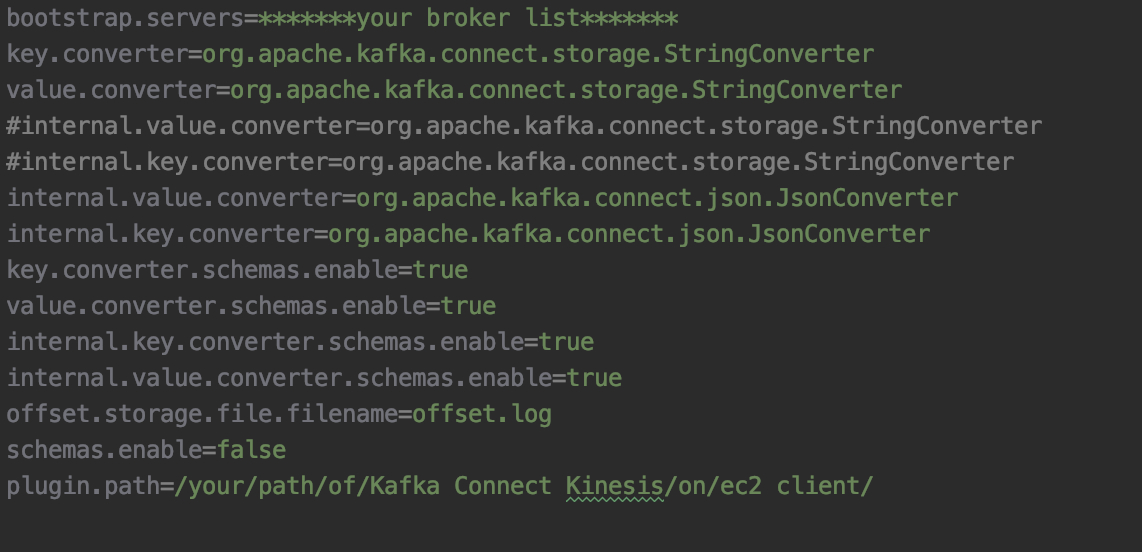
6.3 将修改好的两个配置文件上传至您的EC2 client, 放在kafka的config目录下。
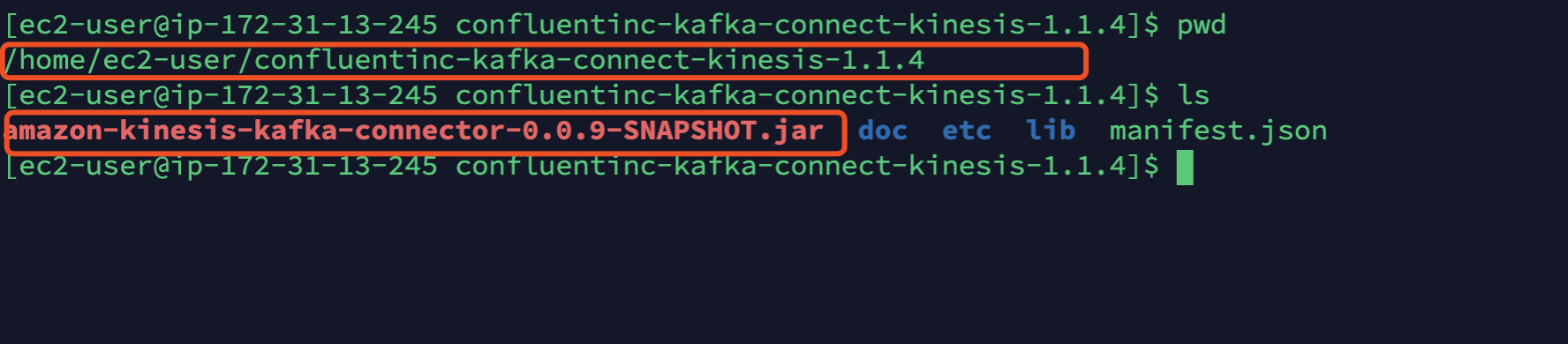
7. 对kinesis-kafka-connector源码进行编译和打包。
kinesis-kafka-connector是用JAVA语言开发的开源项目,您可以通过运行“maven package”来构建项目,它将构建amazon-kinesis-kafka-connector-X.X.X.jar。把这个jar包放置于Kafka Connect Kinesis的目录下,本例中即为
8. 启动您的Kafka Connect Kinesis。
截止到目前,我们的配置工作已经完成,您可以开始使用Kafka Connect Kinesis。生产环境建议您使用分布式模式,本例中我们使用standalone模式来启动。
9. 尝试向您的MSK集群中提交数据,Firehose会将转换并聚合后数据输出到您的S3存储桶中。

四、总结
通过本文的示例,您可以轻松的将现有的MSK集群或Kafka集群与Kinesis集成。通过Kinesis,流数据被可靠地加载到数据湖、数据存储和分析工具中,并最大化的提供商业价值。您可以轻松的捕获、转换流数据并将其加载到 Amazon S3、Amazon Redshift、Amazon Elasticsearch Service等完全托管的服务,可以自动扩展以匹配数据吞吐量,并且无需持续管理。
五、参考资料
https://docs.confluent.io/current/connect/userguide.html#installing-plugins
https://github.com/awslabs/kinesis-kafka-connector