前言
对于CDC(change data capture)进行近实时的消费和计算的需求,是越来越多企业在大数据领域日益迫切的需求。比如,互联网券商在如下场景需要对数据做实时的计算:
- 股票价格的实时变化进行账户持仓分析
- 盘中对成交价格的实时计算和分析
因为大多数的企业在现有的大数据平台上,已经搭建了T+1的大数据平台,我们希望在步改变现有的数据分析路径和逻辑的前提下:
- 使用RDS read replica进行CDC数据变更的捕捉
- 使用MSK托管Connector进行数据CDC的发布和订阅
- 使用基于EMR的Flink进行MSK订阅数据的计算
- 进行Secret Manager, IAM 和MSK的集成
架构设计
整体架构图如下所示:

设计要点:
- 开启RDS binlog使用RDS/Aurora read replica进行数据抽取,避免影响生产系统
- 托管MSK Connector,无需维护Connector实例
- 托管EMR,免运维运行Flink
- 集成AWS Secret Manager,无需明文在托管MSK Connector中暴露数据库用户名和密码
EMR版本为6.4,Flink版本为1.13
整体过程
AWS RDS
1. 开启RDS二进制日志,以及二进制日志的留存时间
call mysql.rds_set_configuration('binlog retention hours', 168);

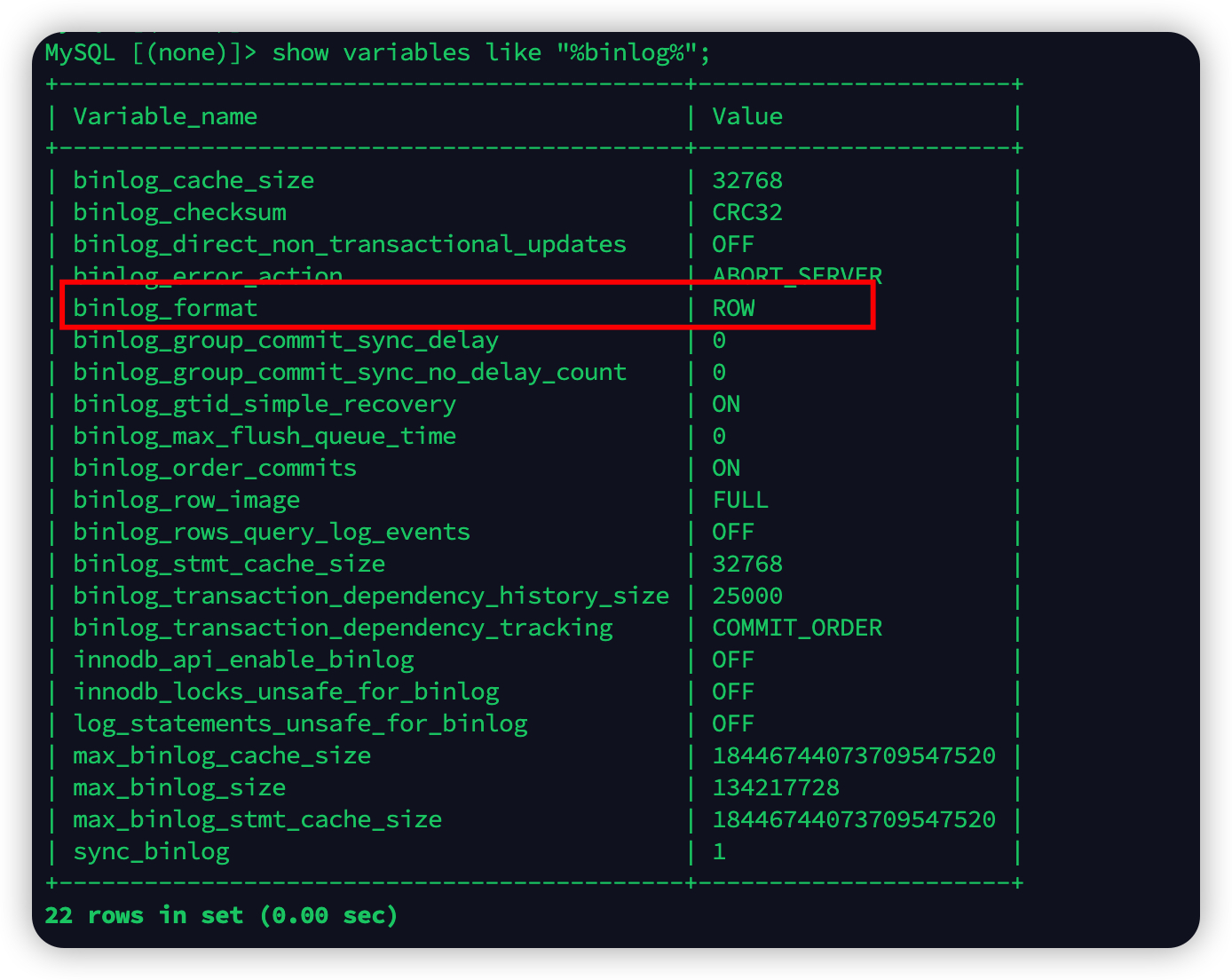
2. 编辑RDS参数组二进制日志设置为, format为ROW


创建MSK
这里使用同时支持IAM和明文认证的MSK集群。
如下为MSK的配置,其中replication factor为3,auto create topic 为true。
auto.create.topics.enable=true
default.replication.factor=3
min.insync.replicas=2
num.io.threads=8
num.network.threads=5
num.partitions=24
num.replica.fetchers=4
replica.lag.time.max.ms=30000
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
socket.send.buffer.bytes=102400
unclean.leader.election.enable=true
zookeeper.session.timeout.ms=18000
log.retention.hours=6
replica.selector.class=org.apache.kafka.common.replica.RackAwareReplicaSelector
max.incremental.fetch.session.cache.slots=10000
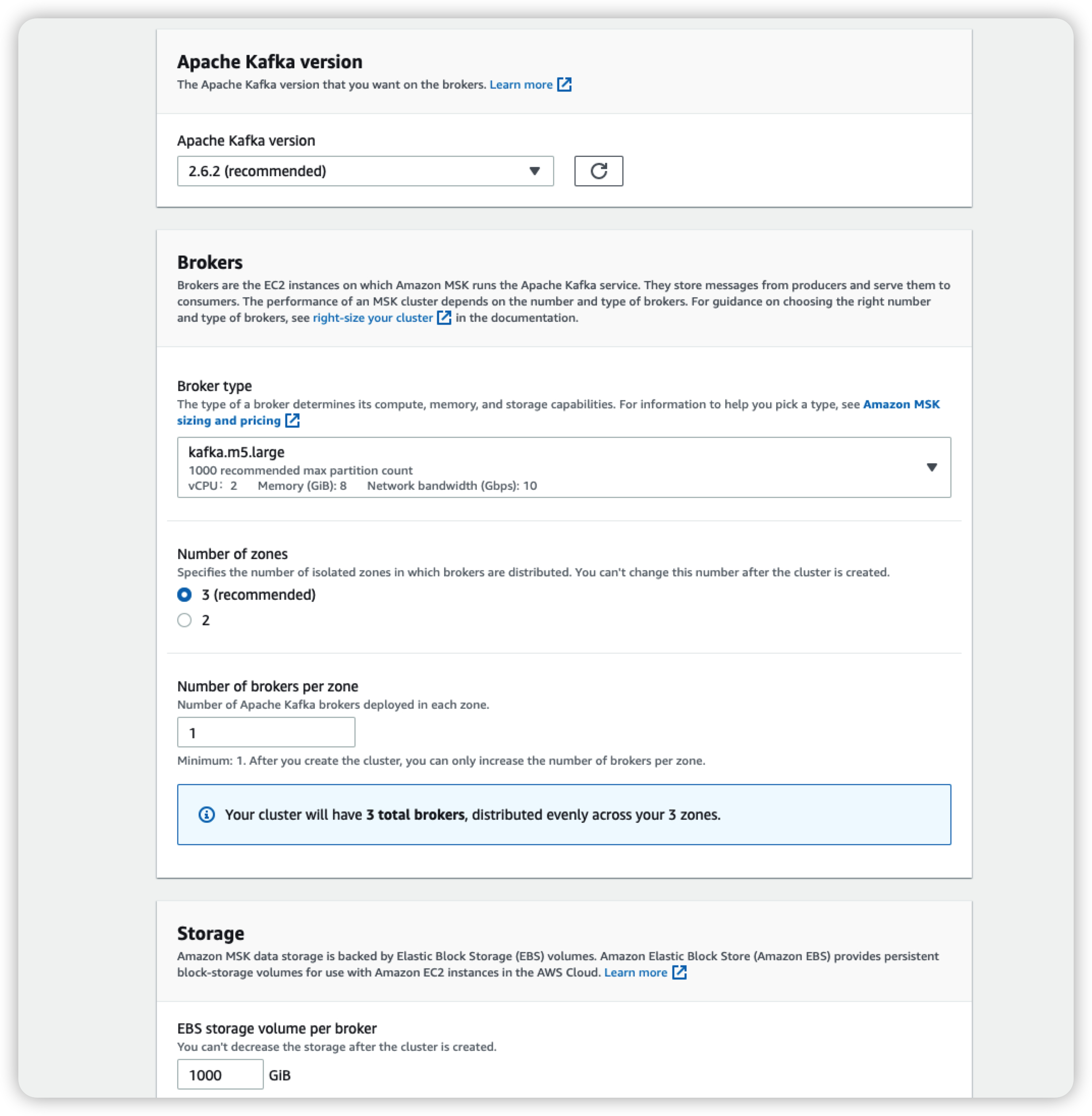
如下为MSK broker配置,采用3 az,每az 1 broker:

选择上一步创建好的MSK配置:

认证方式同时选择
- Unauthenticated access (后续Flink端在测试过程中使用plaintext方式连接)
- IAM role-based authentication

查看集群连接字符串:

测试MSK;
创建客户端配置文件client-config.properties
# Sets up TLS for encryption and SASL for authN.
security.protocol = SASL_SSL
# Identifies the SASL mechanism to use.
sasl.mechanism = AWS_MSK_IAM
# Binds SASL client implementation.
sasl.jaas.config = software.amazon.msk.auth.iam.IAMLoginModule required;
# Encapsulates constructing a SigV4 signature based on extracted credentials.
# The SASL client bound by "sasl.jaas.config" invokes this class.
sasl.client.callback.handler.class = software.amazon.msk.auth.iam.IAMClientCallbackHandler
1. 使用console producer生产数据:
kafka-console-consumer.sh --bootstrap-server b-2.xxxxx-msk-flink.xxxxxx.c4.kafka.ap-southeast-1.amazonaws.com:9098,b-4.xxxxxx-msk-flink.xxxxxx.c4.kafka.ap-southeast-1.amazonaws.com:9098,b-3.xxxxx-msk-flink.xxxxxx.c4.kafka.ap-southeast-1.amazonaws.com:9098 --topic junjie-xxxxxx-topic --from-beginning --consumer.config client-config.properties

2. 使用相同客户端配置,在另一终端消费数据

至此,MSK集群创建完毕,并能够成功进行数据的生产和消费。
创建托管MSK Connector
1. 创建MSK Connector worker configuration
MSK worker configuration是影响 Kafka Connect 集群中的配置存储、工作分配以及偏移量和任务状态存储的设置和参数, 比如对JSON数据的格式转换,这里我们会忽略元数据的转换,只集中在数据库表数据的转换。MSK connector worker configuration的配置如下:
key.converter.schemas.enable=false
value.converter.schemas.enable=false
key.converter=org.apache.kafka.connect.storage.StringConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
config.providers.secretManager.class=com.github.jcustenborder.kafka.config.aws.SecretsManagerConfigProvider
config.providers=secretManager
config.providers.secretManager.param.aws.region=ap-southeast-1
其中针对schema的转换我们设置为false,对key使用StringConverter,对value的转换使用JsonConveter。
因为在MSK 连接器连接数据库需要使用到用户名和密码,在本文中我们使用AWS Secret Manager来保存对应数据库的用户名和密码。
config.providers.secretManager.class=com.github.jcustenborder.kafka.config.aws.SecretsManagerConfigProvider
创建完成的MSK Connector如下:

2. 在Secret Manager中创建保存数据库用户名和密码的Secret

3. 创建MSK Debezium Connector plugin
从https://repo1.maven.org/maven2/io/debezium/debezium-connector-mysql/1.6.1.Final/debezium-connector-mysql-1.6.1.Final-plugin.tar.gz下载debezioum mysql plugin
解压缩之后把下载之后的plugin压缩成zip包上传到S3

使用该上传的zip包制作custom plugin

4. 创建MSK Connector
创建MSK Connector过程中

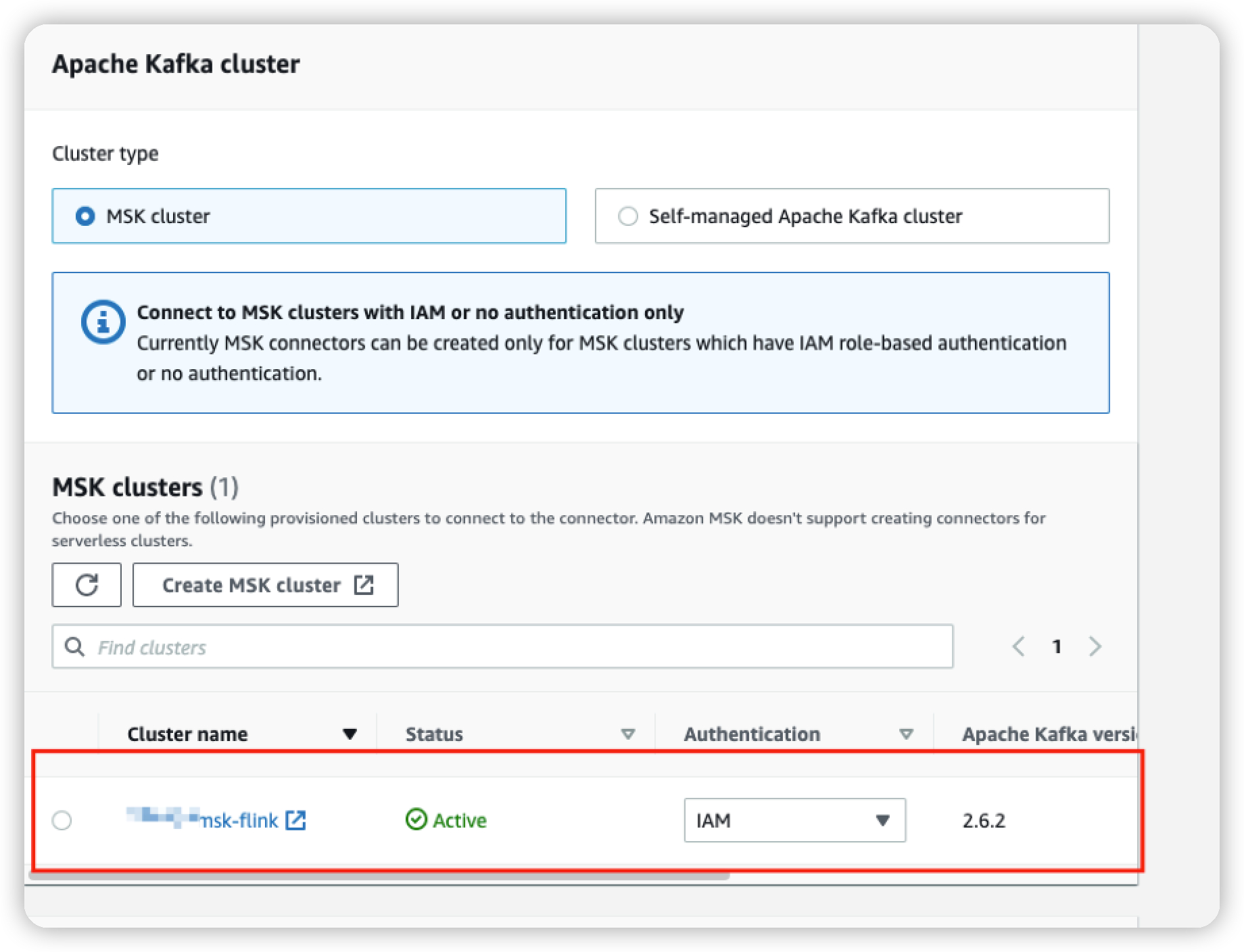
- 使用创建MSK过程中创建的MSK,并选择认证方式为IAM

- 完善Connector Configuration

完整配置如下:
connector.class=io.debezium.connector.mysql.MySqlConnector
database.history.producer.sasl.mechanism=AWS_MSK_IAM
database.history.producer.sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;
database.user=${secretManager:xxxxxx-database-secret:dbusername}
database.server.id=2234
tasks.max=1
database.history.consumer.sasl.jaas.config=software.amazon.msk.auth.iam.IAMLoginModule required;
database.history.producer.security.protocol=SASL_SSL
database.history.kafka.topic=xxxxxx.quotation
database.history.kafka.bootstrap.servers=b-2.xxxxx-msk-flink.xxxxxx.c4.kafka.ap-southeast-1.amazonaws.com:9098,b-1.xxxx-msk-flink.xxxxxx.c4.kafka.ap-southeast-1.amazonaws.com:9098
database.server.name=junjie-sgp-xxxxx
database.history.producer.sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler
database.history.consumer.sasl.client.callback.handler.class=software.amazon.msk.auth.iam.IAMClientCallbackHandler
database.history.consumer.security.protocol=SASL_SSL
database.port=3306
include.schema.changes=true
database.hostname=junjie-sgp-xxxx.xxxxxxx.ap-southeast-1.rds.amazonaws.com
database.password=${secretManager:xxxxx-database-secret:dbpassword}
database.history.consumer.sasl.mechanism=AWS_MSK_IAM
database.include.list=xxx
注意这里使用AWS secret manager中的secret来连接到数据库:
database.user=${secretManager:xxxxx-database-secret:dbusername}
database.password=${secretManager:xxxxx-database-secret:dbpassword}
配置MSK的连接参数为IAM连接字符串
database.history.kafka.bootstrap.servers=b-2.xxxxx-msk-flink.xxxxx.c4.kafka.ap-southeast-1.amazonaws.com:9098,b-1.xxxx-msk-flink.xxxxx.c4.kafka.ap-southeast-1.amazonaws.com:9098
选择上述过程中的worker configuration,并配置所需的MSK connector所需的角色(参考:https://docs.thinkwithwp.com/msk/latest/developerguide/msk-connect-service-execution-role.html)

选择日志组,让connector的日志打到cloudwatch日志组:

创建完成后,观察对应日志组输出:

验证MSK Connector是否可以成功从RDS里消费CDC数据:
查看自动创建的topics:
kafka-topics.sh --bootstrap-server b-2.xxxx-msk-flink.xxxxxx.c4.kafka.ap-southeast-1.amazonaws.com:9098,b-4.xxxx-msk-flink.xxxxxx.c4.kafka.ap-southeast-1.amazonaws.com:9098,b-3.xxxx-msk-flink.xxxxxx.c4.kafka.ap-southeast-1.amazonaws.com:9098 --list --command-config client-config.properties

消费其中一个表的CDC,其中topic的格式为<connector里的database.server.name>.<databas ename>.<table name>, 如junjie-sgp-hstong.hst.flink
kafka-console-consumer.sh --bootstrap-server b-2.xxxxxx-msk-flink.xxxxxx.c4.kafka.ap-southeast-1.amazonaws.com:9098,b-4.xxxxxx-msk-flink.xxxxxx.c4.kafka.ap-southeast-1.amazonaws.com:9098,b-3.xxxxxx-msk-flink.xxxxxx.c4.kafka.ap-southeast-1.amazonaws.com:9098 --topic junjie-sgp-xxxxxx.xxx.flink --from-beginning --consumer.config client-config.properties
于对应数据库插入测试数据,观测消费端输出:


至此,MSK Connector可以成功从数据库消费数据.
创建Flink on EMR
Flink on EMR集群配置如下:
EMR 版本: 6.4.0
Flink 版本: 1.13.1
本文采用单master节点的EMR。

创建完成后使用master DNS登陆EMR集群:

准备flink的Flink table connector,下载Source connector到/lib/flink/lib:
curl -O https://repo1.maven.org/maven2/org/apache/flink/flink-connector-kafka_2.11/1.13.1/flink-connector-kafka_2.11-1.13.1.jar

测试验证
使用flink SQL Client进行验证
登陆EMR master节点,并运行如下命令进入flink sql终端:
cd /lib/flink && ./bin/yarn-session.sh –detached
./bin/sql-client.sh
SET execution.checkpointing.interval = 1min;

进入Flink SQL交互客户端

创建flink table,这里对应数据库里的table<flink>:
CREATE TABLE Flink (
`event_time` TIMESTAMP(3) METADATA FROM 'value.source.timestamp' VIRTUAL, -- from Debezium format
`origin_table` STRING METADATA FROM 'value.source.table' VIRTUAL, -- from Debezium format
`record_time` TIMESTAMP(3) METADATA FROM 'value.ingestion-timestamp' VIRTUAL,
`id` BIGINT,
`name` STRING,
`addr` STRING,
WATERMARK FOR event_time AS event_time
) WITH (
'connector' = 'kafka',
'topic' = 'junjie-sgp-xxxx.xxx.flink', -- created by debezium connector, corresponds to CUSTOMER table in Amazon Aurora database.
'properties.bootstrap.servers' = 'b-5.xxxxxx-msk-flink.xxxxxx.c4.kafka.ap-southeast-1.amazonaws.com:9092,b-1.xxxxx-msk-flink.xxxxxx.c4.kafka.ap-southeast-1.amazonaws.com:9092,b-2.xxxxx-msk-flink.xxxxxx.c4.kafka.ap-southeast-1.amazonaws.com:9092',
'properties.group.id' = 'xxxxx-table-group',
'scan.startup.mode' = 'earliest-offset',
'value.format' = 'debezium-json'
);

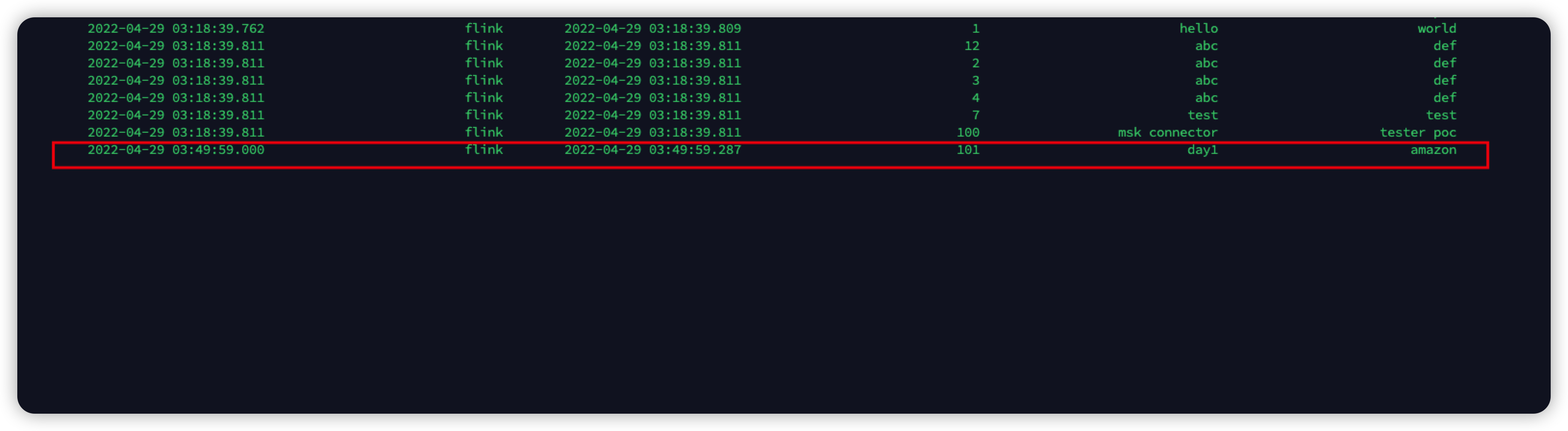
执行Flink 表的查询

在数据库进行数据插入和更新
数据插入


数据更新


总结
- 使用托管的MSK和MSK连接器,对RDBMS的CDC数据进行近实时的提取,减少了维护MSK和MSK连接器的运维负担。
- 使用托管的EMR+Flink,能够近实时地消费在MSK发布的CDC数据。
- 客户可以基于这一架构进行CDC数据的计算,进行流式架构的推进。
参考:
- https://docs.thinkwithwp.com/AmazonRDS/latest/UserGuide/mysql_rds_set_configuration.html
- https://catalog.us-east-1.prod.workshops.aws/workshops/c2b72b6f-666b-4596-b8bc-bafa5dcca741/en-US/mskconnect/source-connector-setup
- https://thinkwithwp.com/blogs/aws/introducing-amazon-msk-connect-stream-data-to-and-from-your-apache-kafka-clusters-using-managed-connectors/
本篇作者