概述
Batch是AWS托管的一个批量计算服务,用户可以通过它运行任意规模的容器化工作负载,目前已经广泛应用于药物研发、基因分析、建模仿真、金融模拟等高性能计算(HPC)的场景。在HPC的场景,一个计算作业可能会用到几千核甚至上万核CPU的算力,那我们如何通过Batch来调用海量的云端算力呢?主要分两种情况,松耦合应用和紧耦合应用。
对于松耦合应用,我们可以通过Batch的数组作业来完成,数组作业是共享通用参数 (如任务定义、vCPU 和内存) 的作业,它以一系列相关但独立的基本作业的形式运行,这些作业可以跨多个主机分布并且同时运行。数组作业通过每台主机的环境变量AWS_BATCH_JOB_ARRAY_INDEX为每个作业从通用参数获取不同的参数值来运行独立的作业,比如在蛋白质药物研发的结构预测场景中,输入文件是一个文本文件,每一行包含一个蛋白质序列, 数组作业的每个子作业处理同一个输入文件的不同行,通过这种方式在云端启动大量的计算实例来达到同时调用成千上万千核来进行蛋白质序列分析的目的。数组作业的具体使用方式,在官方Batch文档中有一个示例可供参考,本篇就不再赘述。
对于紧耦合应用,我们可以通过Batch的多节点并行作业来完成。多节点并行作业能够跨多个EC2实例运行单个作业,Batch 的多节点并行作业与支持基于 IP 的节点间通信的任何框架均可兼容,例如 Apache MXNet、TensorFlow、Caffe2 或消息传递接口 (MPI)。本篇接下来通过一个简单的基于openmpi的程序来演示如何使用Batch的多节点并行作业来调用海量计算资源。
先决条件
您需要一个AWS帐户来完成本演练,其它条件包括(本篇不再描述其具体使用方式):
- 开发环境中完成AWS CLI v2安装和配置,本篇使用us-east-1区域
- 完成VPC的设置,包括私有子网和NAT的配置
- 创建一个EFS用作共享文件系统,用于存放程序脚本和计算的中间数据
- 熟悉Batch计算环境、作业队列、任务定义的配置
- 开发环境中需要安装openmpi用于后续测试代码的编译
- 熟悉进程管理程序supervisor的使用
应用部署
容器化
在 AWS Batch 上运行多节点并行作业,应用程序代码必须包含进行分布式通信所需的框架和库,并且完成容器化镜像的制作。为多节点并行作业构建容器镜像的几个关键点是:
- 设置容器之间可以通过无密码ssh连接
- 下载并编译安装openmpi
- 设置supervisor在Docker容器启动时运行ssh服务,并运行run-mpi.sh
在开发环境中构建容器镜像,Dockerfile如下:
From centos:7
ENV SSHDIR /root/.ssh
RUN \
#install openssh/supervisor and other dependencies
yum install openssh-server openssh-clients wget python3-pip make gcc-c++ perl iproute -y && \
yum clean all && \
pip3 install supervisor && \
#set passwordless ssh keygen
mkdir -p /var/run/sshd && \
cd /etc/ssh && \
sed -i 's/#PermitRootLogin/PermitRootLogin/g' sshd_config && \
sed -i 's/#PubkeyAuthentication/PubkeyAuthentication/g' sshd_config && \
sed -i 's/PasswordAuthentication yes/PasswordAuthentication no/g' sshd_config && \
echo "Host *" >> ssh_config && echo " StrictHostKeyChecking no" >> ssh_config && \
mkdir -p ${SSHDIR} && \
cd ${SSHDIR} && \
touch sshd_config && \
ssh-keygen -t rsa -f id_rsa -N '' && \
mv id_rsa.pub authorized_keys && \
echo " IdentityFile ${SSHDIR}/id_rsa" >> /etc/ssh/ssh_config && \
#install openmpi
cd /tmp && \
wget --quiet https://download.open-mpi.org/release/open-mpi/v4.1/openmpi-4.1.1.tar.gz && \
tar -xvf openmpi-4.1.1.tar.gz && \
cd openmpi-4.1.1 && \
./configure --prefix=/opt/openmpi --enable-mpirun-prefix-by-default && \
make -j $(nproc) && \
make install && \
cd .. && \
rm -rf openmpi-4.1.1
ENV PATH=$PATH:/opt/openmpi/bin:/data
ENV LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/opt/openmpi/lib
WORKDIR /data
在ECR中创建镜像仓库mpi-demo,构建镜像后推送到该仓库(123456789012替换成您自己的AWS账号ID),确保开发测试机具有推送ECR镜像的权限。
# 构建镜像
docker build -t 123456789012.dkr.ecr.us-east-1.amazonaws.com/mpi-demo:latest .
# 登录ECR
aws ecr get-login-password --region us-east-1 | docker login --username AWS \
--password-stdin 123456789012.dkr.ecr.us-east-1.amazonaws.com
# 推送镜像至EC
docker push 123456789012.dkr.ecr.us-east-1.amazonaws.com/mpi-demo:latest
任务脚本
AWS Batch多节点并行作业跨节点的容器之间使用 Amazon ECS awsvpc 网络模式进行通信,在作业运行时,ECS容器从后端接收环境变量,这些变量可用于确定哪个运行容器是主容器,哪个是子容器,以下是使用的4个环境变量:
- AWS_BATCH_JOB_MAIN_NODE_INDEX -此变量为作业的主节点的索引号,应用程序代码可以将 AWS_BATCH_JOB_MAIN_NODE_INDEX 与单个节点上的 AWS_BATCH_JOB_NODE_INDEX 进行比较,以确定它是否为主节点
- AWS_BATCH_JOB_MAIN_NODE_PRIVATE_IPV4_ADDRESS -此变量为作业的主节点的私有 IPv4 地址,仅在子节点中存在,子节点的应用程序代码可以使用此地址与主节点进行通信
- AWS_BATCH_JOB_NODE_INDEX -此变量为节点的唯一索引号,从 0 开始
- AWS_BATCH_JOB_NUM_NODES -此变量为多节点并行作业请求的节点数
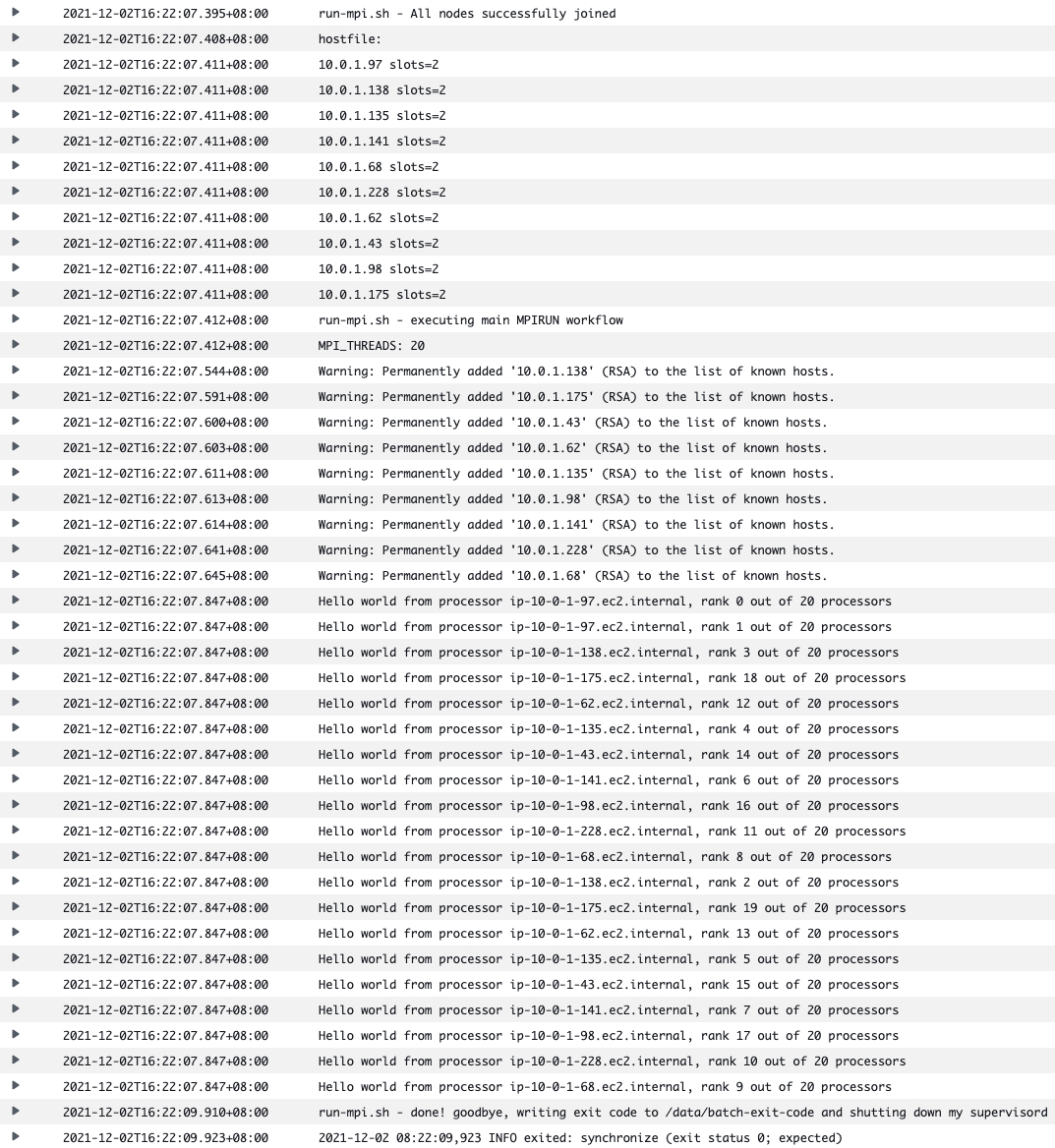
以下代码是一个MPI同步脚本run-mpi.sh,容器启动后执行该脚本,子节点上的容器会调用report_to_master()函数把自身的ip和CPU核数报告给主节点,主节点在所有子节点初始化完成之后通过mpirun来调用计算程序mpi_hello_world
#!/bin/bash
BASENAME="${0##*/}"
log () {
echo "${BASENAME} - ${1}"
}
HOST_FILE_PATH="/data/hostfile"
AWS_BATCH_EXIT_CODE_FILE="/data/batch-exit-code"
usage () {
if [ "${#@}" -ne 0 ]; then
log "* ${*}"
log
fi
cat <<ENDUSAGE
Usage:
export AWS_BATCH_JOB_NODE_INDEX=0
export AWS_BATCH_JOB_NUM_NODES=10
export AWS_BATCH_JOB_MAIN_NODE_INDEX=0
export AWS_BATCH_JOB_ID=string
./run-mpi.sh
ENDUSAGE
error_exit
}
# Standard function to print an error and exit with a failing return code
error_exit () {
log "${BASENAME} - ${1}" >&2
log "${2:-1}" > $AWS_BATCH_EXIT_CODE_FILE
kill $(cat /tmp/supervisord.pid)
}
# Check what environment variables are set
if [ -z "${AWS_BATCH_JOB_NODE_INDEX}" ]; then
usage "AWS_BATCH_JOB_NODE_INDEX not set, unable to determine rank"
fi
if [ -z "${AWS_BATCH_JOB_NUM_NODES}" ]; then
usage "AWS_BATCH_JOB_NUM_NODES not set. Don't know how many nodes in this job."
fi
if [ -z "${AWS_BATCH_JOB_MAIN_NODE_INDEX}" ]; then
usage "AWS_BATCH_MULTI_MAIN_NODE_RANK must be set to determine the master node rank"
fi
NODE_TYPE="child"
if [ "${AWS_BATCH_JOB_MAIN_NODE_INDEX}" == "${AWS_BATCH_JOB_NODE_INDEX}" ]; then
log "Running synchronize as the main node"
NODE_TYPE="main"
fi
# wait for all nodes to report
wait_for_nodes () {
log "Running as master node"
touch $HOST_FILE_PATH
ip=$(/sbin/ip -o -4 addr list eth0 | awk '{print $4}' | cut -d/ -f1)
availablecores=$(nproc)
log "master details -> $ip:$availablecores"
echo "$ip slots=$availablecores" >> $HOST_FILE_PATH
lines=$(uniq $HOST_FILE_PATH|wc -l)
while [ "$AWS_BATCH_JOB_NUM_NODES" -gt "$lines" ]
do
log "$lines out of $AWS_BATCH_JOB_NUM_NODES nodes joined, will check again in 5 second"
sleep 5
lines=$(uniq $HOST_FILE_PATH|wc -l)
done
# Make the temporary file executable and run it with any given arguments
log "All nodes successfully joined"
# remove duplicates if there are any.
cur_timestamp=$((`date '+%s'`*1000+10#`date '+%N'`/1000000))
awk '!a[$0]++' $HOST_FILE_PATH > ${HOST_FILE_PATH}-$cur_timestamp
echo "hostfile: "
cat $HOST_FILE_PATH-$cur_timestamp
log "executing main MPIRUN workflow"
echo "MPI_THREADS: "$MPI_THREADS
cd $DATA_DIR
mpirun --allow-run-as-root -n $MPI_THREADS --hostfile ${HOST_FILE_PATH}-$cur_timestamp mpi_hello_world
sleep 2
rm ${HOST_FILE_PATH}
log "done! goodbye, writing exit code to $AWS_BATCH_EXIT_CODE_FILE and shutting down my supervisord"
echo "0" > $AWS_BATCH_EXIT_CODE_FILE
kill $(cat /tmp/supervisord.pid)
exit 0
}
report_to_master () {
# looking for masters nodes ip address calling the batch API TODO
# get own ip and num cpus
availablecores=$(nproc)
ip=$(/sbin/ip -o -4 addr list eth0 | awk '{print $4}' | cut -d/ -f1)
log "I am a child node -> $ip:$availablecores, reporting to the master node -> ${AWS_BATCH_JOB_MAIN_NODE_PRIVATE_IPV4_ADDRESS}"
until echo "$ip slots=$availablecores" | ssh ${AWS_BATCH_JOB_MAIN_NODE_PRIVATE_IPV4_ADDRESS} "cat >> /$HOST_FILE_PATH"
do
echo "Sleeping 5 seconds and trying again"
done
log "done! goodbye"
exit 0
}
# Main - dispatch user request to appropriate function
log $NODE_TYPE
case $NODE_TYPE in
main)
wait_for_nodes "${@}"
;;
child)
report_to_master "${@}"
;;
*)
log $NODE_TYPE
usage "Could not determine node type. Expected (main/child)"
;;
esac
supervisor是基于Python开发的一套通用的进程管理程序,能将一个普通的命令行进程以Daemon方式后台运行,并监控进程状态,异常退出时能自动重启,创建以下配置文件supervisord.conf:
[supervisord]
logfile = /tmp/supervisord.log
logfile_maxbytes = 50MB
logfile_backups=10
loglevel = info
pidfile = /tmp/supervisord.pid
nodaemon = false
minfds = 1024
minprocs = 200
umask = 022
user = root
identifier = supervisor
directory = /tmp
nocleanup = true
childlogdir = /tmp
strip_ansi = false
[program:sshd]
user=root
command=/usr/sbin/sshd -D -f /root/.ssh/sshd_config -h /root/.ssh/id_rsa
stdout_logfile=/dev/fd/1
stdout_logfile_maxbytes=0
redirect_stderr=true
autorestart=true
stopsignal=INT
[program:synchronize]
user=root
command=/data/run-mpi.sh
stdout_logfile=/dev/fd/1
stdout_logfile_maxbytes=0
redirect_stderr=true
autorestart=false
startsecs=0
stopsignal=INT
exitcodes=0,2
容器启动时运行脚本entry-point.sh,该脚本会通过supervisor在容器启动时运行ssh服务,并运行run-mpi.sh
#!/bin/bash
BASENAME="${0##*/}"
log () {
echo "${BASENAME} - ${1}"
}
AWS_BATCH_EXIT_CODE_FILE="/data/batch-exit-code"
# launch supervisor
supervisord -n -c "/data/supervisord.conf"
# if supervisor dies then read exit code from file we don't want to return the supervisors exit code
log "Reading exit code from batch script stored at $AWS_BATCH_EXIT_CODE_FILE"
if [ ! -f $AWS_BATCH_EXIT_CODE_FILE ]; then
echo "Exit code file not found , returning with exit code 1!" >&2
exit 1
fi
exit $(cat $AWS_BATCH_EXIT_CODE_FILE)
openmpi 测试程序
在开发环境创建如下程序mpi_hello_world.c(详细可参考此教程)
#include <mpi.h>
#include <stdio.h>
int main(int argc, char** argv) {
// Initialize the MPI environment
MPI_Init(NULL, NULL);
// Get the number of processes
int world_size;
MPI_Comm_size(MPI_COMM_WORLD, &world_size);
// Get the rank of the process
int world_rank;
MPI_Comm_rank(MPI_COMM_WORLD, &world_rank);
// Get the name of the processor
char processor_name[MPI_MAX_PROCESSOR_NAME];
int name_len;
MPI_Get_processor_name(processor_name, &name_len);
// Print off a hello world message
printf("Hello world from processor %s, rank %d out of %d processors\n",
processor_name, world_rank, world_size);
// Finalize the MPI environment.
MPI_Finalize();
}
通过以下命令编译,生成可执行文件mpi_hello_world
mpicc -o mpi_hello_world mpi_hello_world.c
EFS
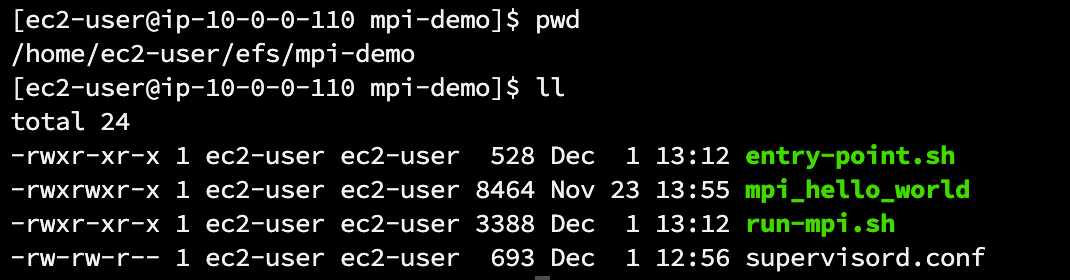
开发环境挂载EFS文件系统,在文件系统中创建mpi-demo目录,保存entry-point.sh,run-mpi.sh,mpi_hello_world和supervisord.conf 到该目录下,并且把entry-point.sh和run-mpi.sh修改为可执行权限(这些文件也可以通过Dockerfile打包进容器镜像,放在容器外面主要是为了调试及后期修改方便,不用每次都重新构建镜像)

置放群组(可选)
对于多节点并行作业,为了提高节点间通信的网络性能,可考虑在单个可用区中创建集群 置放群组,并与计算资源进行关联。在EC2控制台创建一个策略为集群的置放群组:

Batch设置
可通过Batch控制台或者命令行工具来进行Batch环境的配置,以下均通过命令行工具来演示如何进行Batch计算环境、作业队列、任务定义的设置(123456789012替换成您自己的AWS账号id)
计算环境
创建配置文件env-mpi.json:
subnets:配置了NAT网关路由的私有子网
securityGroupIds:默认安全组id
placementGroup:置放群组名称
instanceTypes:使用的实例类型
tags:EC2标签
{
"computeEnvironmentName": "env-mpi",
"type": "MANAGED",
"state": "ENABLED",
"computeResources": {
"type": "EC2",
"allocationStrategy": "BEST_FIT",
"minvCpus": 0,
"maxvCpus": 2560,
"desiredvCpus": 0,
"instanceTypes": [
"c5.large"
],
"subnets": [
"subnet-06e79c7b3404a4d57"
],
"securityGroupIds": [
"sg-03c9b3efa166d2fe6"
],
"instanceRole": "arn:aws:iam::123456789012:instance-profile/ecsInstanceRole",
"tags": {
"Name": "batch-mpi-node"
},
"placementGroup": "batch",
"ec2Configuration": [
{
"imageType": "ECS_AL2"
}
]
},
"serviceRole": "arn:aws:iam::123456789012:role/aws-service-role/batch.amazonaws.com/AWSServiceRoleForBatch"
}
创建计算环境
aws batch create-compute-environment --cli-input-json file://env-mpi.json
{
"computeEnvironmentName": "env-mpi",
"computeEnvironmentArn": "arn:aws:batch:us-east-1:123456789012:compute-environment/env-mpi"
}

作业队列
配置文件q-mpi.json:
computeEnvironment:上一步创建的计算环境的arn
{
"jobQueueName": "q-mpi",
"state": "ENABLED",
"priority": 1,
"computeEnvironmentOrder": [
{
"order": 1,
"computeEnvironment": "arn:aws:batch:us-east-1:123456789012:compute-environment/env-mpi"
}
],
"tags": {}
}
创建作业队列
aws batch create-job-queue --cli-input-json file://q-mpi.json
{
"jobQueueName": "q-mpi",
"jobQueueArn": "arn:aws:batch:us-east-1:123456789012:job-queue/q-mpi"
}

任务定义
配置文件jd-mpi.json
numNodes:节点数量,本次演示使用10个节点
mainNode:主节点索引
targetNodes:节点索引范围
volumes和mountPoints:将efs的mpi-demo目录挂载到容器内的/data目录下
environment:环境变量
{
"jobDefinitionName": "jd-mpi",
"type": "multinode",
"parameters": {},
"nodeProperties": {
"numNodes": 10,
"mainNode": 0,
"nodeRangeProperties": [
{
"targetNodes": "0:9",
"container": {
"image": "123456789012.dkr.ecr.us-east-1.amazonaws.com/mpi-demo:latest",
"command": [
"sh",
"entry-point.sh"
],
"volumes": [
{
"name": "efs",
"efsVolumeConfiguration": {
"fileSystemId": "fs-7dfcd4c9",
"rootDirectory": "mpi-demo"
}
}
],
"environment": [
{
"name": "DATA_DIR",
"value": "/data"
},
{
"name": "MPI_THREADS",
"value": "20"
}
],
"mountPoints": [
{
"containerPath": "/data",
"sourceVolume": "efs"
}
],
"privileged": true,
"ulimits": [],
"user": "root",
"resourceRequirements": [
{
"value": "2",
"type": "VCPU"
},
{
"value": "2048",
"type": "MEMORY"
}
]
}
}
]
},
"propagateTags": false,
"platformCapabilities": [
"EC2"
]
}
注册任务定义
aws batch register-job-definition --cli-input-json file://jd-mpi.json
{
"jobDefinitionName": "jd-mpi",
"jobDefinitionArn": "arn:aws:batch:us-east-1:123456789012:job-definition/jd-mpi:1",
"revision": 1
}

测试
提交任务
aws batch submit-job \
--job-name j-mpi-test \
--job-queue q-mpi \
--job-definition jd-mpi:1
{
"jobArn": "arn:aws:batch:us-east-1:123456789012:job/7f1f7d36-8c5d-40d5-9013-3eb626aaba51",
"jobName": "j-mpi-test",
"jobId": "7f1f7d36-8c5d-40d5-9013-3eb626aaba51"
}
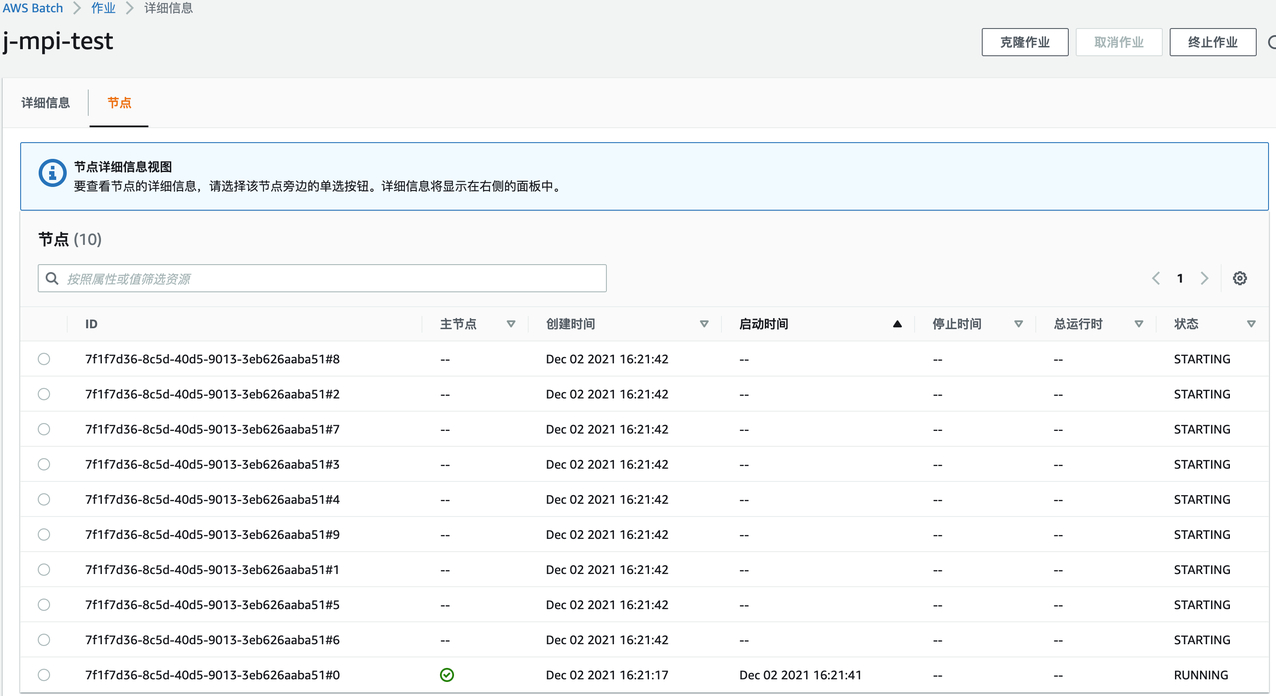
可以看到任务提交后启动了一个具有10个节点的并行任务


在EC2控制台也能看到启动了10台EC实例

作业执行完成之后,最终的作业状态(SUCCEEDED 或 FAILED)由主节点的最终作业状态决定

在CloudWatch查看主节点的日志

结论
在这篇文章中,我们演示了在仅有一次任务提交的情况下,如何通过AWS Batch的多节点并行作业为紧耦合的mpi工作负载调用大量的CPU计算资源。在实际的场景中,您可以将mpi_hello_world改为自己的程序或者与其它分析软件结合使用。除了CPU之外,您也可以使用各种类型的GPU资源,无需担心算力问题,在AWS上尽情运行您的HPC工作负载吧!
参考文档
AWS Batch用户指南:https://docs.thinkwithwp.com/zh_cn/batch/latest/userguide/what-is-batch.html
aws-mnpbatch-template:https://github.com/aws-samples/aws-mnpbatch-template
MPI教程:https://github.com/aws-samples/aws-mnpbatch-template
在AWS Batch中构建具有多节点并行作业的紧耦合分子动力学工作流:https://thinkwithwp.com/cn/blogs/compute/building-a-tightly-coupled-molecular-dynamics-workflow-with-multi-node-parallel-jobs-in-aws-batch/
本篇作者