亚马逊AWS官方博客
使用Amazon Step Functions Data Science SDK构建从AWS Glue Crawler到Glue Job的工作流程
对于数据科学家来讲,每天花费的大量时间主要在解决实际业务问题上,需要分析和收集支持信息,得出问题的结论。很多情况下,特定的任务和目标可能都需要一个人来完成,
而开发ETL又是必不可少的工作,什么样的平台可以满足他们的需求?
轻量化,免运维,交互式展现,自动化的工作流,可视化的监控,这些只需要在Jupyter Notebook中操作,就可以轻松地准备和加载数据以供分析。
在本文中,我们将利用无服务器架构工作流,用于表结构的爬取和执行ETL作业,从而实现上述步骤的自动化和可视化。
用产品的方式来解决,他们习惯用python代码在Jupyter Notebook中开发,图形化展示各种数据。创建可视化的端到端的工作流程,以最终输出结果为导向。跟业务无关的工作,其实是可以用产品的方式解决的
那么减少人工重复工作,监控每个任务的运行状态和日志记录,实现整个流程的自动化。
方案概述
本文将以一个常见的使用场景,通过
Amazon Step Functions Data Science SDK创建基于无服务器架构的工作流,过程如下:
- 创建Lambda调用Amazon Glue进行Crawler工作,识别数据格式和Schema
- 创建Lambda检查Amazon Glue Crawler工作状态,如果返回值为null,即认为Crawler执行完成
- 使用Amazon Glue进行ETL工作,生成样本数据集
下图演示了上述Amazon Step Functions无服务器架构工作流:
后续操作使用了下列亚马逊云科技服务:
Amazon Step Functions ,是由多个离散步骤组成的状态机,其中每个步骤都可以执行任务、作出选择、启动并行执行或管理超时。其中一个步骤的输出作为下一个步骤的输入,并支持将错误处理嵌入到工作流中。
Step Functions Data Science SDK,相比较Amazon Step Functions ,使用Python代码轻松创建、执行和可视化Step Function工作流,而不是只能使用基于JSON语言定义Step Function。
本文以Step Functions Data Science SDK为主线,讨论如何创建Step Function步骤、使用参数、集成服务特定的功能,将这些步骤关联在一起,创建和可视化工作流。
Amazon Glue是一项完全托管的提取、转换和加载(ETL)服务,在分布式Apache Spark环境中运行,能够充分利用Spark而无需管理基础设施。
1. 创建Glue Crawler和Glue Job
在控制面板中创建Glue Crawler,请参考手册
https://docs.thinkwithwp.com/zh_cn/glue/latest/dg/console-crawlers.html
在控制面板中创建Glue Job,请参考手册
https://docs.thinkwithwp.com/zh_cn/glue/latest/dg/add-job.html
2. 创建两个Lambda Functions
2.1 首先,创建一个启动Crawler作业的Lambda Functions,命名为Crawler_initial,本环境使用Python 3.8 Runtime

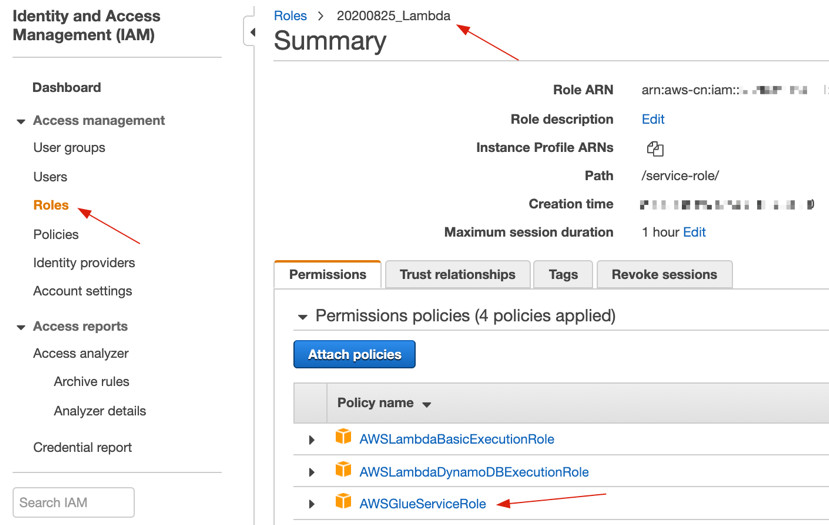
2.2 创建一个新的Role,或者使用已有的Role,这个Role必须有访问AWS Glue的权限

2.3 在IAM下查看Role所关联的策略,关联“AWSGlueServiceRole”
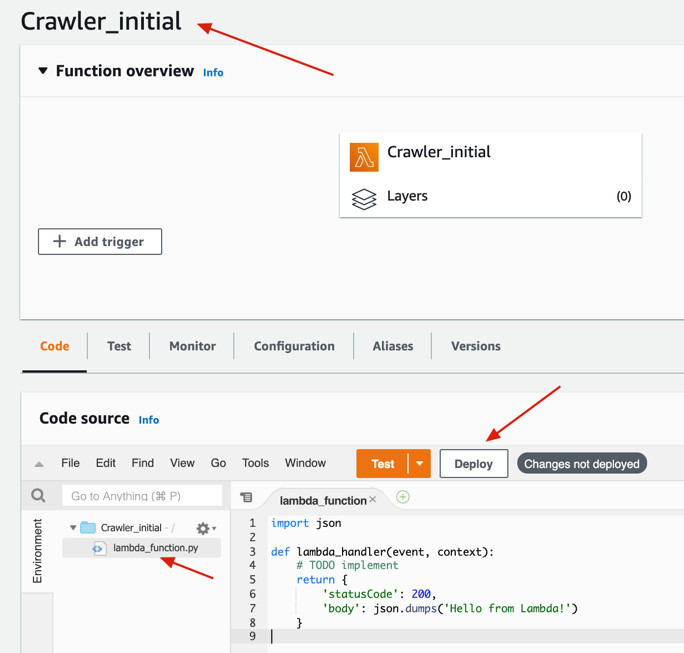
2.4 在已有的lambda_function.py中可以直接编写代码,并点击“Deploy”部署
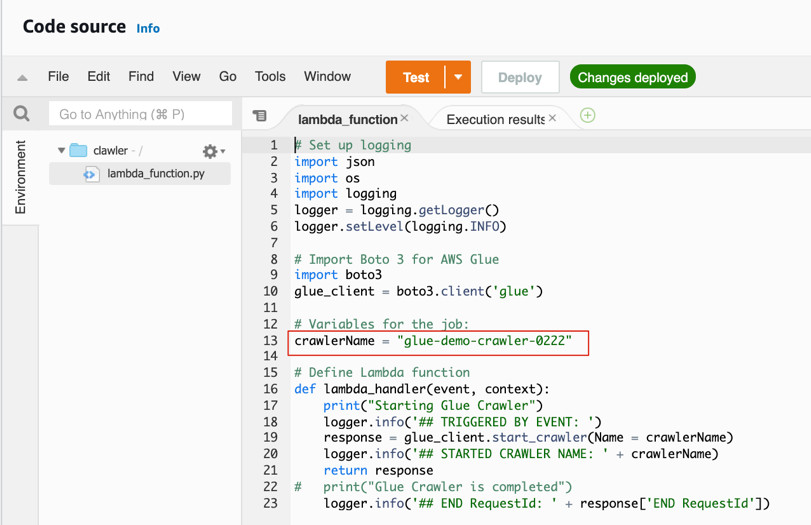
2.5 下边为执行Crawler的代码,要指定crawlername,点击“Test”,可以在“Execution results”中看到相关的日志
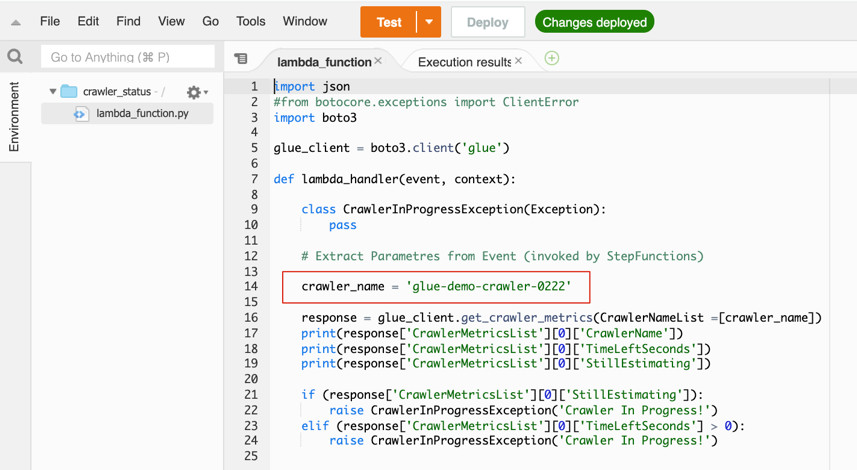
2.6 其次,创建一个检查Crawler作业状态的Lambda Functions,创建过程不再赘述,代码如下
3. 创建Jupyter Notebook
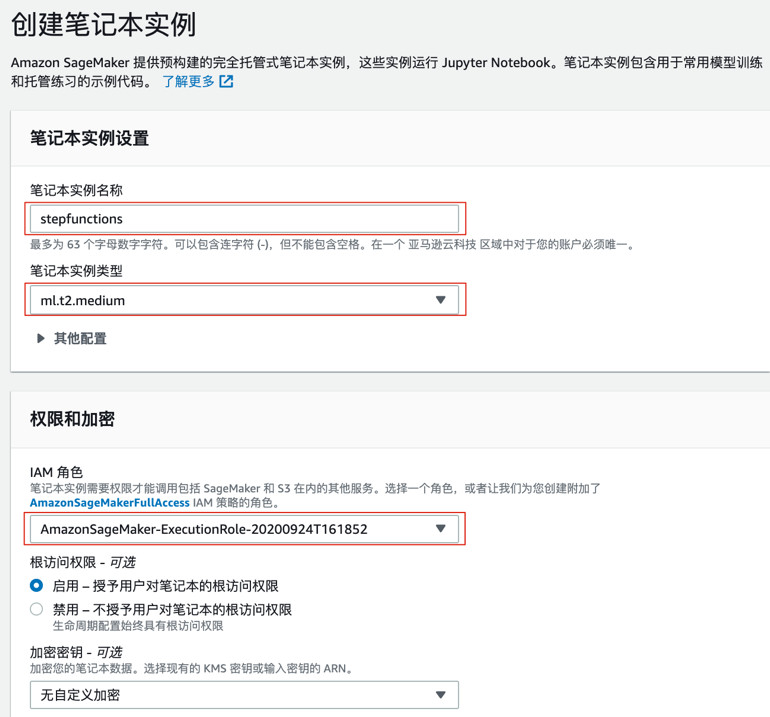
3.1 创建Amazon SageMaker 笔记本实例

3.2 创建一个笔记本实例,类型选择t2.medium。选择或者创建一个IAM角色(IAM Role),其他部分选择默认选项,点击创建(Create)
3.3 笔记本创建完成后,打开Jupyter,选择New,新建一个ipynb,选择内核为conda_python3

4. 使用Step Functions Data Science SDK创建和定义工作流
4.1 安装和加载必需的模块

4.2 在Console创建一个Role附加到Step Functions

4.3 定义Step,指定Execute Crawler的Lambda名字

4.4 定义Step,指定Check Crawler Status的Lambda名字

此处采用retry的方式来检查Crawler是否完成,建议先手工执行Crawler评估需要的时间,再定义间隔时间
4.5 定义Step,指定执行Glue Job的名字

5. 运行上述Workflow,指定Workflow Name
5.1 新建名为My-ETL-workflow01的工作流

5.2 生成图示

5.3 执行Work flow,可以看到不同的颜色代表不同的状态,完整执行过程的图示如下
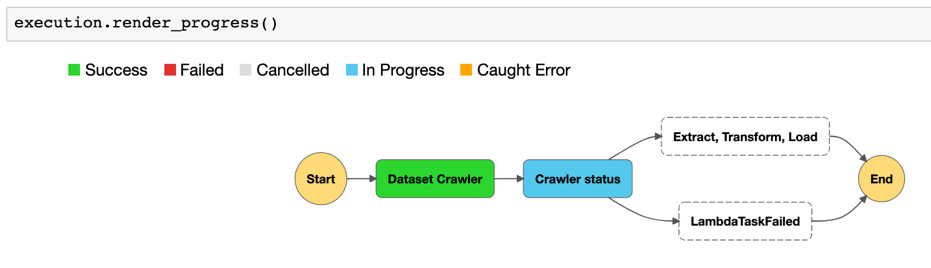


5.4 如果执行失败,可以查看events

6. 总结
本文讨论的是使用Amazon Step Functions Data Science SDK,创建一个基于无服务器架构的数据ETL工作流。对于数据科学团队来讲,这些步骤都可以在Notebook中完成,而且可以通过Step Functions监控每个任务的运行状态和日志记录,最终实现整个流程的自动化,减少数据科学家的人工重复工作,提高生产开发效率。
关于ETL流程的自动化,Glue也自带了Workflows方式来实现,和Step Functions相比较,Glue Workflows是编排内部作业和爬网程序,如果调用Glue之外的其他AWS服务,需要使用Step Functions。
| AWS Step Functions | AWS Glue Workflows | |
| 应用场景 |
在AWS各种服务之间定义工作流, 处理和移动数据 |
在多个AWS Glue作业、爬网程序和触发器之间定义工作流 |
| 数据治理 |
管理重试逻辑 正确或错误处理 可做循环 |
无 |
| 可视化内容 |
工作流程 每个流程状态 |
工作流程 每个流程状态 |
| 构建方式 |
AWS Glue Console API AWS CLI
|
AWS Step functions Console API AWS CLI AWS SDK |
Glue Workflow和事件驱动的方式来实现ETL流程的自动化,可参考下边的链接:
如何使用AWS Glue工作流在爬网程序运行完成时自动启动作业?
如何使用Lambda函数在爬网程序运行完成时自动启动AWS Glue作业?
7. 参考资料
[1] aws-step-functions-data-science-sdk-python
[2] AWS Step Functions Data Science SDK – Compute