亚马逊AWS官方博客
释放创造力:生成式人工智能和 Amazon SageMaker 如何帮助企业借助 AWS 为营销活动制作广告素材
解决方案概览
想象这样一个场景:一家全球汽车公司需要为其即将发布的新车型制作新的营销材料,为此聘请了一家广告公司,该公司以向拥有强大品牌资产的客户提供广告解决方案而闻名。这家汽车制造商在寻找低成本的广告素材,以便在保持汽车制造商品牌形象的同时,使用不同的位置、颜色和视角来展示该车型。凭借先进技术的强大功能,广告公司可以在其安全的 AWS 环境中,使用生成式人工智能模型为客户提供支持。
该解决方案是使用生成式人工智能以及 Amazon SageMaker 中的文字转图像模型开发的。SageMaker 是一项完全托管式机器学习(ML)服务,可针对任何使用场景,使用完全托管的基础设施、工具和工作流,轻松地构建、训练和部署机器学习模型。Stable Diffusion 是 Stability AI 推出的文本到图像基础模型,用于支持图像生成流程。Diffusers 是预先训练的模型,通过 Stable Diffusion 使用现有图像,根据提示生成新图像。将 Stable Diffusion 与 ControlNet 等 Diffusers 结合使用,可以利用现有的品牌特定内容开发出炫目的版本。在 AWS 中使用 Amazon SageMaker 开发解决方案的主要好处是:
- 私密性 – 将数据存储在 Amazon Simple Storage Service(Amazon S3)中并使用 SageMaker 托管模型,这样您就可以遵循 AWS 账户中的安全最佳实践,同时不对外公开资产。
- 可扩展性 – 将 Stable Diffusion 模型部署作为 SageMaker 端点时,允许您配置实例大小和实例数量,从而实现可扩展性。SageMaker 端点还具备自动扩缩功能和高可用性。
- 灵活性 – 在创建和部署端点时,可以通过 SageMaker 灵活选择 GPU 实例类型。此外,在业务需求发生变化时,可以毫不费力地更改 SageMaker 端点后面的实例。AWS 还开发了硬件和芯片,为生成式人工智能使用 AWS Inferentia2,以最低的成本实现高性能的推理。
- 快速创新 – 生成式人工智能是一个快速发展的领域,采用全新方法,而且还在不断开发和发布新模型。Amazon SageMaker JumpStart 定期推出新模型和基础模型。
- 端到端集成 – 利用 AWS,您能够将创作流程与任何 AWS 服务集成,并开发端到端的流程,通过 AWS Identity and Access Management(IAM)进行精细的访问控制,通过 Amazon Simple Notification Service(Amazon SNS)发送通知,以及使用事件驱动型计算服务 AWS Lambda 进行后处理。
- 分发 – 生成新素材后,使用 AWS 的 Amazon CloudFront,可以通过多个区域中的全球渠道分发内容。
在这篇博文中,我们使用以下 GitHub 示例,该示例使用 Amazon SageMaker Studio 和基础模型(Stable Diffusion)、提示、计算机视觉技术和 SageMaker 端点,从现有图像生成新图像。下图展示了该解决方案的架构。
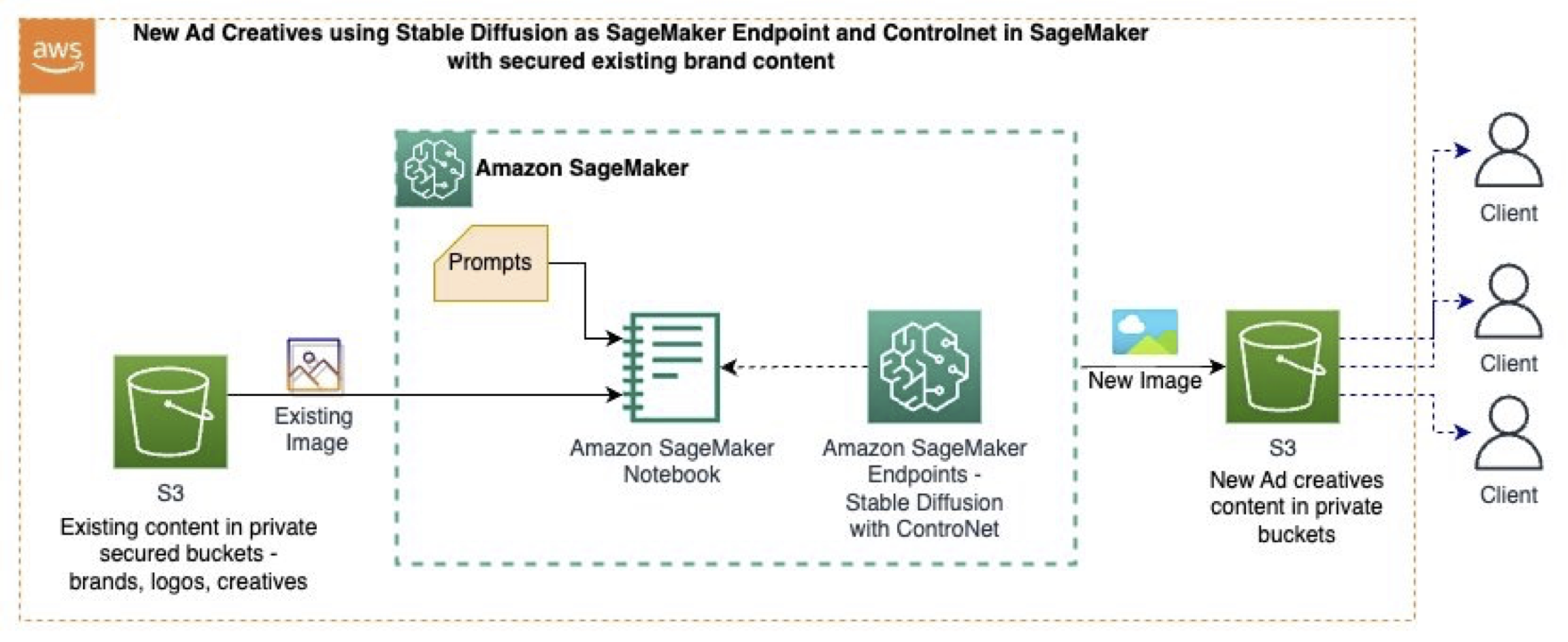
该工作流包含以下步骤:
- 我们将现有内容(图片、品牌风格等)安全地存储在 S3 存储桶中。
- 在 SageMaker Studio 笔记本中,使用计算机视觉技术,将原始图像数据转换为图像,这将保留产品(汽车模型)的形状,去除颜色和背景,并生成单色的中间图像。
- 中间图像用作 Stable Diffusion 与 ControlNet 的控制图像。
- 我们在基于 GPU 的适宜实例大小上,从 SageMaker Jumpstart 部署 SageMaker 端点和 Stable Diffusion 文本转图像基础模型,并部署 ControlNet。
- 使用描述新背景和汽车颜色的提示以及单色中间图像来调用 SageMaker 端点,从而生成新图像。
- 新图像在生成后存储在 S3 存储桶中。
在 SageMaker 端点上部署 ControlNet
要将模型部署到 SageMaker 端点,我们必须为每个单独的技术模型构件创建一个压缩文件,并创建 Stable Diffusion 权重、推理脚本和 NVIDIA Triton 配置文件。
在以下代码中,我们以 tar.gz 文件格式,将不同 ControlNet 技术的模型权重和 Stable Diffusion 1.5 下载到本地目录:
为了创建模型管道,我们定义一个 inference.py 脚本,SageMaker 实时端点将使用该脚本,来加载和托管 Stable Diffusion 与 ControlNet tar.gz 文件。以下是 inference.py 中的代码片段,其中显示了如何加载模型以及如何调用 Canny 技术:
我们从模型 URI,使用所需的实例大小(GPU 类型)部署 SageMaker 端点:
生成新图像
现在,端点已部署在 SageMaker 端点上,我们可以传入提示和要用作基准的原始图像。
为了定义提示,我们创建了正向提示 p_p,这是我们希望在新图像中出现的内容;还创建了负向提示 n_p,这是希望在新图像中避免出现的内容:
最后,我们使用提示和源图像调用端点,以此来生成新图像:
不同的 ControlNet 技术
在本节中,我们将比较不同的 ControlNet 技术及其在所生成图像上的效果。我们通过以下原始图像,使用 Amazon SageMaker 中的 Stable Diffusion 和 ControlNet 生成新内容。

下表显示了技术输出如何描述在原始图像中需要强调的内容。
| 技术名称 | 技术类型 | 技术输出 | 提示 | Stable Diffusion 与 ControlNet |
| canny | 单色图像,黑色背景上带有白色边缘。 |  |
金属橙色汽车,整车,彩色照片,宜人的户外风景,逼真,高品质 |  |
| depth | 灰度图像,黑色代表深层区域,白色代表浅层区域。 |  |
金属红色汽车,整车,彩色照片,宜人的户外海滩风景,逼真,高品质 |  |
| hed | 单色图像,黑色背景上带有白色柔化边缘。 |  |
金属白色汽车,整车,彩色照片,城市中,夜晚,逼真,高品质 |  |
| scribble | 手绘单色图像,黑色背景上带有白色轮廓。 |  |
金属蓝色汽车,类似于原车,整车,彩色照片,户外,壮观的景色,逼真,高品质,不同的视角 |  |
清理
使用生成式人工智能生成新的广告素材后,清理所有不再使用的资源。删除 Amazon S3 中的数据并停止任何 SageMaker Studio 笔记本实例,以免继续产生任何费用。如果您使用 SageMaker JumpStart 将 Stable Diffusion 部署为 SageMaker 实时端点,请通过 SageMaker 控制台或 SageMaker Studio 删除该端点。
总结
在这篇博文中,我们使用 SageMaker 上的基础模型,从存储在 Amazon S3 中的现有图像创建新的内容图像。借助这些技术,营销、广告和其他创意机构都能够使用生成式人工智能工具,增强其广告创意流程。要更深入地了解本演示中展示的解决方案和代码,请查看 GitHub 存储库。
另外,有关生成式人工智能、基础模型和文本转图像模型的使用场景,请参阅 Amazon Bedrock。
*前述特定亚马逊云科技生成式人工智能相关的服务仅在亚马逊云科技海外区域可用,亚马逊云科技中国仅为帮助您了解行业前沿技术和发展海外业务选择推介该服务。
关于作者
 Sovik Kumar Nath 是 AWS 的人工智能/机器学习解决方案架构师。在财务、运营、营销、医疗保健、供应链管理和物联网等领域中,他拥有丰富的设计端到端机器学习和业务分析解决方案经验。Sovik 发表过多篇关于机器学习模型监控方面的文章,并在此领域拥有一项专利。他拥有南佛罗里达大学和瑞士弗里堡大学的双硕士学位,以及哈拉格布尔印度理工学院的学士学位。工作之余,Sovik 喜欢旅行、坐船和看电影。
Sovik Kumar Nath 是 AWS 的人工智能/机器学习解决方案架构师。在财务、运营、营销、医疗保健、供应链管理和物联网等领域中,他拥有丰富的设计端到端机器学习和业务分析解决方案经验。Sovik 发表过多篇关于机器学习模型监控方面的文章,并在此领域拥有一项专利。他拥有南佛罗里达大学和瑞士弗里堡大学的双硕士学位,以及哈拉格布尔印度理工学院的学士学位。工作之余,Sovik 喜欢旅行、坐船和看电影。
 Sandeep Verma 是AWS 的高级原型设计架构师。他喜欢深入研究客户面临的挑战,为客户构建原型以加速创新。他拥有人工智能/机器学习的专业背景,是 New Knowledge 的创始人,对科技充满热情。业余时间,他喜欢和家人一起旅行和滑雪。
Sandeep Verma 是AWS 的高级原型设计架构师。他喜欢深入研究客户面临的挑战,为客户构建原型以加速创新。他拥有人工智能/机器学习的专业背景,是 New Knowledge 的创始人,对科技充满热情。业余时间,他喜欢和家人一起旅行和滑雪。
 Uchenna Egbe 是 AWS 的助理级解决方案架构师。在空闲时间,他喜欢研究草药、茶、超能食物以及如何将它们融入日常饮食中。
Uchenna Egbe 是 AWS 的助理级解决方案架构师。在空闲时间,他喜欢研究草药、茶、超能食物以及如何将它们融入日常饮食中。
 Mani Khanuja 是 Amazon Web Services(AWS)的人工智能和机器学习专家 SA。她帮助客户使用机器学习来解决他们在应用 AWS 方面的业务挑战。她将大部分时间花在深入研究和指导客户实施与计算机视觉、自然语言处理、预测、边缘机器学习等相关的人工智能/机器学习项目上。她热衷于边缘机器学习,因此建造了自己的实验室,拥有自动驾驶套件和原型制造生产线,并在实验室中度过了很多闲暇时光。
Mani Khanuja 是 Amazon Web Services(AWS)的人工智能和机器学习专家 SA。她帮助客户使用机器学习来解决他们在应用 AWS 方面的业务挑战。她将大部分时间花在深入研究和指导客户实施与计算机视觉、自然语言处理、预测、边缘机器学习等相关的人工智能/机器学习项目上。她热衷于边缘机器学习,因此建造了自己的实验室,拥有自动驾驶套件和原型制造生产线,并在实验室中度过了很多闲暇时光。