亚马逊AWS官方博客
Step Functions 分布式 Map – 大规模并行数据处理的无服务器解决方案
我很高兴地宣布 AWS Step Functions 的分布式 Map 现已正式推出。此流程扩展了对协调大规模并行工作负载(例如半结构化数据的按需处理)的支持。
Step Function 的 Map 状态对数据集中的多个条目执行相同的处理步骤。现有 Map 状态一次仅限于 40 次并行迭代。由于这种限制,扩展数据处理工作负载以并行处理数千个(甚至更多)项目变得非常困难。在今天之前,为了实现更高的并行处理,您必须对现有的 Map 状态组件实施复杂的变通方法。
借助全新的分布式 Map 状态,您可以编写 Step Functions 来协调无服务器应用程序中的大规模并行工作负载。现在,您可以迭代存储在 Amazon Simple Storage Service (Amazon S3) 中的数百万个对象,例如日志、图像或 .csv 文件。新的分布式 Map 状态可以启动多达一万个并行工作流来处理数据。
可以通过编写 Step Functions 支持的任何服务 API 来处理数据,但通常,您将调用 Lambda 函数,使用最喜欢编程语言编写的代码来处理数据。
Step Functions 分布式 Map 支持的最大并行执行次数为 10,000 次,远高于许多其他 AWS 服务支持的并发数。可以使用分布式 Map 的最大并发数功能来确保不会超过下游服务的并发数。使用其他服务时,需要考虑两点因素。首先,服务针对您的账户支持的最大并发数。其次,突增和提升速率决定了实现最大并发数的速度。
我们以 Lambda 为例说明。函数的并发数是在给定时间为请求提供服务的实例数量。Lambda 的默认最大并发数配额为每个 AWS 区域 1,000 个。您可以随时要求增加此配额。对于初始突增流量,函数在某个区域中的累积并发数可以达到 500 到 3000 之间的初始水平,该水平因地区而异。突增并发数配额适用于您在该地区的所有函数。
使用分布式 Map 时,请务必验证下游服务的配额。在开发过程中限制分布式 Map 的最大并发数,并相应地计划增加服务配额。
为了将新的分布式 Map 与原始 Map 状态流进行比较,我创建了如下的表。
| 原始 Map 状态流程 | 新的分布式 Map 流程 | |
| 子工作流 |
|
|
| 并行分支 | Map 迭代并行运行,一次有效的最大并发数约为 40。 | 可以将数百万个项目传递给多个子执行,一次最多可并发 10,000 个执行。 |
| 输入源 | 仅接受 JSON 数组作为输入。 | 接受作为 Amazon S3 对象列表、JSON 数组或文件、csv 文件或 Amazon S3 清单的输入。 |
| 有效载荷 | 256 KB | 每次迭代都会收到对文件 (Amazon S3) 的引用或来自文件的单个记录(状态输入)。实际文件处理能力受到 Lambda 存储空间和内存量的限制。 |
| 执行历史记录 | 25,000 个事件 | Map 状态的每次迭代都是子执行,每次最多有 25,000 个事件(快速模式对执行历史记录没有限制)。 |
分布式 Map 中的子工作流既适用于标准工作流,也适用于低延迟、短持续时间的快捷工作流。
这项新功能经过优化,可与 S3 配合使用。我可以直接从分布式 Map 配置中配置存储数据的存储桶和前缀。分布式 Map 在一亿个项目后停止读取,支持最大 10GB 的 JSON 或 csv 文件。
处理大型文件时,请考虑下游服务功能。我们再次以 Lambda 为例说明。每个输入(例如 S3 上的文件)都必须适合 Lambda 函数执行环境的临时存储空间和内存量。为了更轻松地处理大型文件,Lambda Powertools for Python 引入了一项新的流式处理功能,以最小的内存占用量获取、转换和处理 S3 对象。这样,您的 Lambda 函数就可处理大于其执行环境规模的文件。要了解有关此新功能的更多信息,请查看 Lambda Powertools 文档。
我们来看看实际操作
在本演示中,我将创建处理存储在 S3 上的一千张狗图像的工作流。这些图像已经存储在 S3 上。
➜ ~ aws s3 ls awsnewsblog-distributed-map/images/
2022-11-08 15:03:36 27034 n02085620_10074.jpg
2022-11-08 15:03:36 34458 n02085620_10131.jpg
2022-11-08 15:03:36 12883 n02085620_10621.jpg
2022-11-08 15:03:36 34910 n02085620_1073.jpg
...
➜ ~ aws s3 ls awsnewsblog-distributed-map/images/ | wc -l
1000工作流和 S3 存储桶必须位于同一区域。
首先,我导航到 AWS 管理控制台的 Step Functions 页面,然后选择创建状态机。在下一页上,我选择使用可视化编辑器设计我的工作流。分布式 Map 适用于标准工作流,因此我保留默认选择。我选择 Next(下一步)进入可视化编辑器。
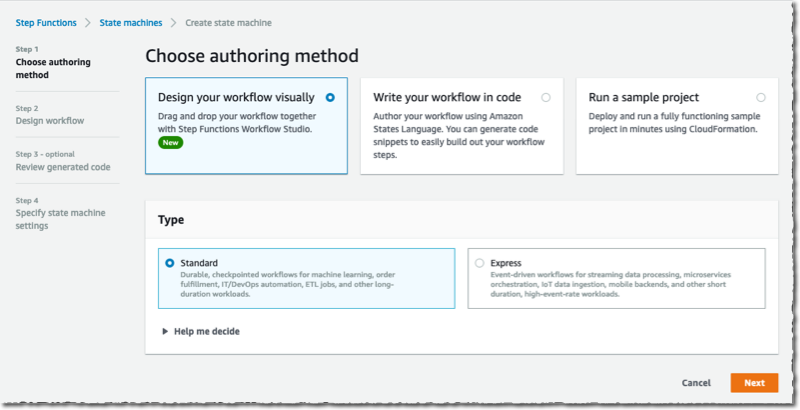 在可视化编辑器中,我在左侧窗格中搜索并选择 Map 组件,然后将其拖到工作流区域。在右侧窗格中,我配置该组件。我选择 Distributed(分布式)作为处理模式,选择 Amazon S3 作为项目源。
在可视化编辑器中,我在左侧窗格中搜索并选择 Map 组件,然后将其拖到工作流区域。在右侧窗格中,我配置该组件。我选择 Distributed(分布式)作为处理模式,选择 Amazon S3 作为项目源。
分布式 Map 与 S3 原生集成。我输入存储图像的存储桶名称 (awsnewsblog-distributed-map) 和前缀 (images)。
 在 Runtime Settings(运行时设置)部分,我选择 Express(快捷)作为子工作流类型。我也可以决定限制并发数上限。它有助于确保我们在特定账户或区域的下游服务(本演示中为 Lambda)的并发配额内运行。
在 Runtime Settings(运行时设置)部分,我选择 Express(快捷)作为子工作流类型。我也可以决定限制并发数上限。它有助于确保我们在特定账户或区域的下游服务(本演示中为 Lambda)的并发配额内运行。
默认情况下,我的子工作流的输出将汇总为状态输出,最大为 256KB。要处理更大的输出,我可以选择将 Map 状态结果导出到 Amazon S3。

最后,我定义了要为每个文件执行的操作。在此演示中,我想为 S3 存储桶中的每个文件调用 Lambda 函数。该函数已经存在。我在左侧窗格中搜索并选择 Lambda 调用操作。我将此操作拖动到分布式 Map 组件中。然后,我使用右侧的配置面板选择本示例中要调用的实际 Lambda 函数:AWSNewsBlogDistributedMap。
完成后,我选择 Next(下一步)。我在 Review generated code(审查生成的代码)页面(此处未显示上再次选择 Next(下一步)。
在 Specify state machine settings(指定状态机设置)页面上,我输入状态机的名称和要运行的 IAM 权限。然后,我选择 Create state machine(创建状态机)。
 现在,我已经准备好开始执行。在 State machine(状态机)页面上,我选择新的工作流并选择 Start execution(开始执行)。我可以选择输入 JSON 文档以传递给工作流。在此演示中,工作流不处理输入数据。我保持原样,然后选择 Start execution(开始执行)。
现在,我已经准备好开始执行。在 State machine(状态机)页面上,我选择新的工作流并选择 Start execution(开始执行)。我可以选择输入 JSON 文档以传递给工作流。在此演示中,工作流不处理输入数据。我保持原样,然后选择 Start execution(开始执行)。
 |
 |
在工作流的执行过程中,我可以监控进度。我观察迭代次数,以及成功处理或出错的项目数量。
 我可以深入研究一次特定的执行以查看详情。
我可以深入研究一次特定的执行以查看详情。
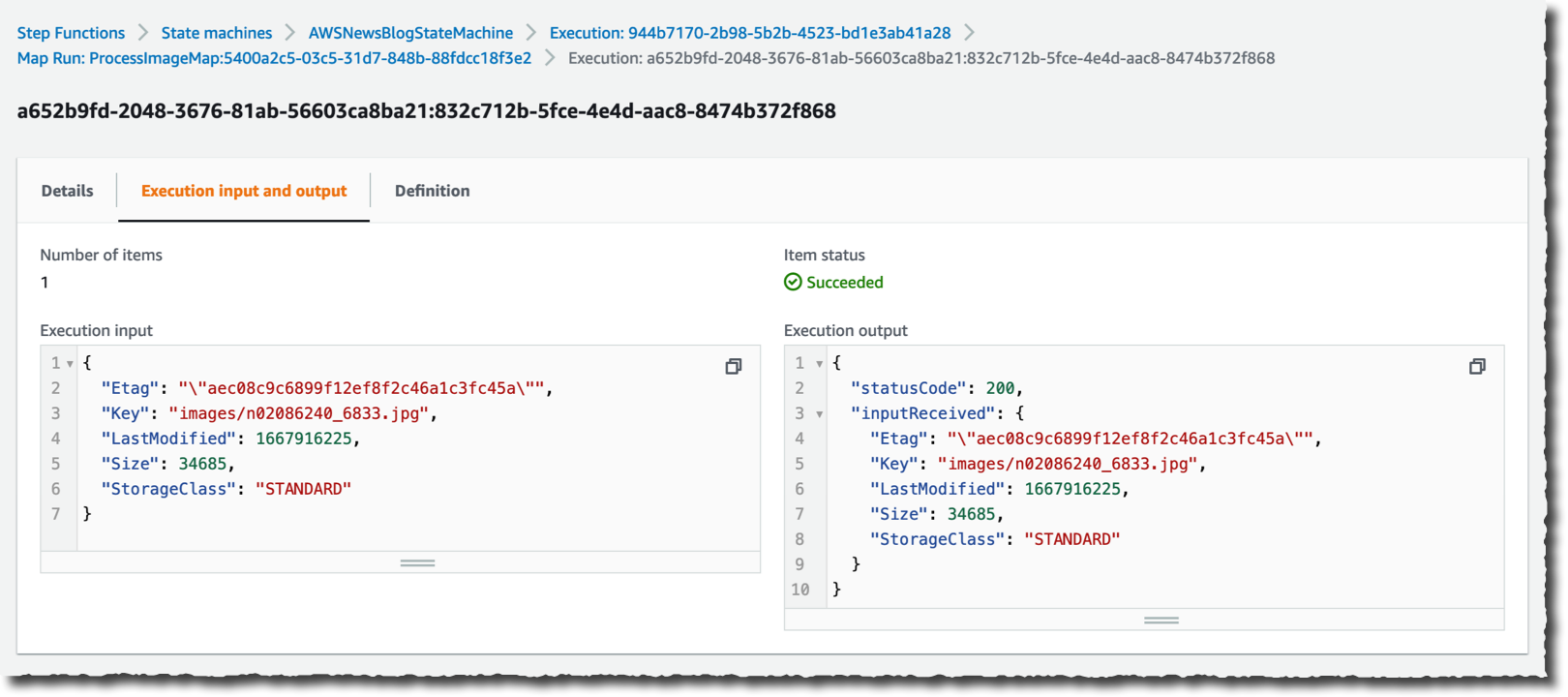
只需单击几次,我就创建了一个大规模且高度并行的工作流,该工作流能够处理大量数据。
我应该使用哪个 AWS 服务
正如在 AWS 上经常发生的情况,您可能会发现这项新功能与 AWS Glue、Amazon EMR 或 Amazon S3 批处理操作等现有服务之间存在重叠。我们试着区分使用案例。
在我的思维模型中,数据科学家和数据工程师使用 AWS Glue 和 EMR 来处理大量数据。另一方面,应用程序开发人员将使用 Step Functions 在其应用程序中添加无服务器数据处理。Step Functions 能够快速从零开始扩展,这使其非常适合客户可能需要等待结果的交互式工作负载。最后,系统管理员和 IT 运营团队可能会使用 Amazon S3 批处理操作进行单步 IT 自动化操作,例如复制、标记或更改数十亿 S3 对象的权限。
定价和可用性
AWS Step Functions 的分布式 Map 已在以下 10 个 AWS 区域正式推出:美国东部(俄亥俄州、弗吉尼亚北部)、美国西部(俄勒冈州)、亚太地区(新加坡、悉尼、东京)、加拿大(中部)和欧洲(法兰克福、爱尔兰、斯德哥尔摩)。
现有内联 Map 状态的定价模型没有变化。对于新的分布式 Map 状态,我们针对每次迭代收取一次状态转换费用。定价因区域而异,起价为每 1,000 个状态转换 0.025 USD。当您使用快速工作流处理数据时,还会根据工作流的请求数量及其持续时间向您收取费用。同样,不同区域的价格各不相同,但起价为每 100 万个请求 1.00 USD 和每 GB 每小时 0.06 USD(按 100ms 比例计算)。
对于相同数量的迭代,与现有内联 Map 相比,结合使用分布式 Map 和标准工作流可降低成本。当您使用快速工作流时,预计分布式 Map 的成本将保持不变,从而实现更多价值。
我很高兴发现您将使用这项新功能构建项目以及它将如何解锁创新。立即开始构建高度并行的无服务器数据处理工作流!