亚马逊AWS官方博客
在 Amazon EMR 上运行 PySpark 报表业务
关于Spark和Amazon EMR
在大数据领域,Apache Spark是非常流行的集群计算框架,用于快速处理、查询和分析大数据。Spark是基于Scala语言编写的框架,但如果您从未使用过Scala也无需担心。Spark除了提供Scala/Java支持外,还提供了Python API接口。使用PySpark,您可以通过Python直接使用Spark SQL、Spark Streaming和Spark MLlib等核心组件。大多数数据科学家和分析专家都习惯使用Python,因为它具有丰富的第三方库集。PySpark使更广泛的用户群体可以利用分布式处理大数据,而不仅局限于传统意义上的大数据工程师。
Amazon EMR服务提供托管的Hadoop环境,可以在几分钟内启动集群并自动完成Spark环境的配置。EMR提供PySpark、PySpark3支持,还自带Jupyter Notebook功能,可以方便地在NoteBook中对python代码进行调试。EMR还提供了多种高级功能,比如与AWS S3和Glue数据目录集成、可使用Spot实例降低成本、可通过EMR步骤功能提交多阶段任务等等。
Spark在业界有非常广泛的应用场景。在这篇博客中,我们会向您展示如何通过EMR快速、高效地编写和提交报表任务。本文中的示例将使用pyspark.sql模块操作Spark DataFrame,从S3中读取数据,经过一系列转换,再将合并报表保存到S3和Glue数据目录中。示例中所使用的数据为模拟数据,您可以在自有环境中通过开源工具生成任意大小的数据集进行PySpark的学习和实验。
数据集
本文使用TPC-H开源工具产生模拟数据集。TPC-H是一个用于支持商业决策的测试基准,它可以逼真地模拟数据仓库的实际应用环境,进行大量的数据分析、执行高复杂度的查询和回答关键的商业问题。我们将通过TPC-H的数据工具生成一些模拟数据表,并通过PySpark实现合并报表操作。
通过以下命令,可以在Amazon Linux2的EC2实例中生成总大小为1G的数据表并上传至指定的S3存储桶。在此之前,请先创建一个新的S3存储桶,并将命令中的<YOUR BUCKET NAME>替换为存储桶的名称。如果稍后想用更大对数据集和EMR集群进行实验,TPC-H工具也可以支持生成10G、100G甚至更大的数据集。该工具可生成的数据共包括客户信息、订单信息等在内的10张结构化数据表,不同数据表之间可以通过客户编号、订单编号、零部件编号等数个字段进行关联。详细的表结构可以参考此链接中的第13页。
注:有关aws cli的安装,请参考https://docs.thinkwithwp.com/cli/latest/userguide/cli-chap-install.html;
有关s3的命令使用,请参考https://docs.thinkwithwp.com/cli/latest/reference/s3/
启动EMR Spark集群
通过控制台启动集群
要在 EMR中使用Spark,请EMR登录控制台,在创建集群界面点击“转到高级选项”,并在软件配置界面勾选Spark。在创建Spark集群时,建议同时勾选将AWS数据目录“用于Spark表元数据”。元数据包含用Spark创建的database、table等元信息。不同于Hive Metastore,Glue Catalog可以提供持久性的元数据存储,这些元数据的生命周期并不会随EMR集群终止,这便于您随时启动和关闭EMR集群来进行数据操作。

在EMR集群中使用Spot实例作为任务节点是节约成本的一种有效方法。任务节点是可选的计算型节点,不负责HDFS数据存储。根据数据大小和代码逻辑的复杂程度,可以适当配置任务节点来加速计算。Spot实例有可能在运行任务时被回收,但Spark在各个层面有多重失败重试机制,可以保证大多数情况下任务的继续运行。

如果需要通过SSH登录master节点,需要在安全性设置中事先选择EC2密钥对。然后点击“创建集群”。

PySpark编程和调试
通常来讲,PySpark shell可以作为一个简易的交互式入口。如果在创建集群时配置了EC2秘钥对和相应的安全组规则,可以SSH进入Master节点使用“pyspark”命令进入PySpark Shell。但通常notebook可以更好地支持编程和数据分析,便于进行添加叙述性文本、进行可视化等操作。在EMR中,可以直接使用EMR Notebook(一个置于 Amazon EMR 控制台中的 Jupyter Notebook 环境,详情请参考此链接)。
使用EMR Notebook
EMR Notebook可以通过控制台创建,并且不需要单独为Notebook支付任何费用。Notebook的内容存放在S3中,在集群关闭后仍然保留,可以加载到新的EMR集群进行使用。要创建EMR Notebook,在EMR控制台中依次点击“笔记本”-“创建笔记本”:

在Notebook准备就绪后,可以从控制台打开Jupyter Notebook并尝试编写代码:


使用Spark SQL API和DataFrame编写报表任务
Spark SQL是Spark用于处理结构化和半结构化数据的一个高级模块。Spark SQL中的DataFrame是一种以命名列方式组织的分布式数据集。简单来讲,DataFrame类似于传统关系型数据库中的表结构,代表了对底层数据源(例如csv、json、parquet文件)的抽象化。Spark DataFrame的用法之一是进行SQL查询:在关系型数据库中对单表进行的查询操作,都可以在DataFrame中直接执行SQL语句实现。除此之外,DataFrame还提供了一套与Pandas DataFrame类似的API。对已经在Python和R中熟悉DataFrame的用户而言,可以快速熟悉PySpark DataFrame的API,对S3、HDFS和HBase等数据存储进行访问。
基于PySpark API提供的强大功能,我们可以快速编写出复杂的业务逻辑。常用的API功能包括:
创建SparkSession
Spark中所有功能的入口是SparkSession类。可以使用如下代码创建一个基本的SparkSession对象:
在notebook中创建了SparkSession后,可以在EMR控制台中看到相应的应用程序记录。执行代码时,EMR Notebook通过livy接口向Spark集群传输指令。
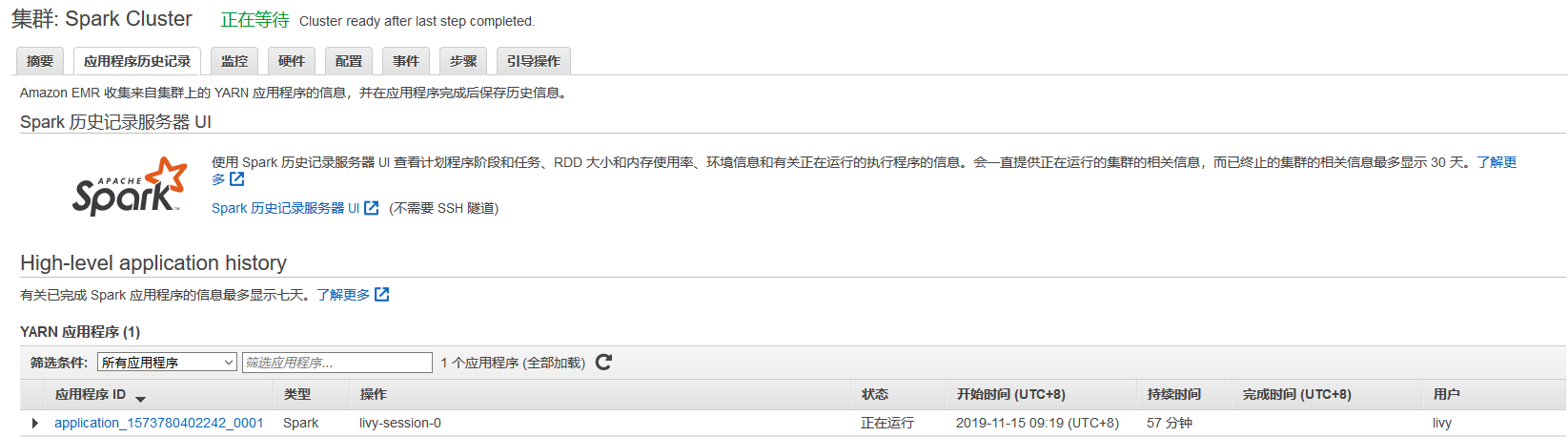
读取存在S3中的数据
如果事先为EMR的角色配置了访问S3的权限,则可以在EMR中直接访问保存在S3中的数据。比如,当我们想要访问partsupp表中的数据时,可以使用如下的代码指定表结构并加载数据:
打印数据和表结构
PySpark DataFrame提供了包括count、first、head、show、printSchema在内的常用API。详情可以参见pyspark.sql.DataFrame API文档。
- 打印数据结构:
- 查询总行数:
- 打印行:
数据过滤
列操作
- 选择一列或多列:
- 添加或替换数据列:
拼接(join)
常见的并表场景包括想要将多个小表横向合并为大表,这时可以直接使用DataFrame.join对数据进行操作。比如,我们想要将lineitem表和之前导入的partsupp表通过“suppkey”字段进行并表:
聚合(aggregation)
并表后可以根据实际业务需求对字段进行聚合。PySpark可以先使用选定的字段生成pyspark.sql.GroupedData对象,再通过agg函数进行聚合。pyspark.sql.functions中包含了聚合操作常用的求和、求平均数等功能。示例代码如下:
将结果写入到S3和Glue Catalog
如果在创建集群时Glue数据目录设置中勾选了“用于Spark表元数据”的选项,我们就可以在写入S3的同时将DataFrame的元数据写入Glue数据目录。
使用EMR步骤功能提交PySpark任务
准备工作
在接下来的步骤中,我们将提供一个名为pyspark_job.py的示例脚本。您也可以选择自行编写脚本进行实验。如果要使用提供的示例脚本,在提交任务之前,请先进行如下的准本工作:
- 在Glue中创建一个新的database
- 将脚本中的<YOUR GLUE DATABASE NAME> 替换为新创建的database名称,并将<YOUR TABLE NAME>替换为想要的输出表格名称
- 将脚本中的四处<YOUR BUCKET NAME>替换为之前存放数据文件的S3存储桶名称
- 修改完成后保存并将py脚本上传至S3
- 如果EMR默认角色没有足够的权限,可能会导致任务失败。这时可以在控制台中编辑EMR_EC2_DefaultRole并赋予其访问Glue的权限。生产环境中,请遵循权限最小化原则,这里为了简化实验步骤,可以直接添加AWS托管策略:AWSGlueServiceRole
- 如果您的账户之前在Glue尚未上线时使用了Amazon Athena数据目录,需要升级到Glue数据目录才能正常运行示例脚本。详细步骤可参照此链接
通过控制台添加步骤功能
EMR提供了步骤功能,可以直接运行存储在S3中的代码,而无需登录主节点进行Spark-submit。此功能可以支持提交.py文件。
要添加步骤,选择“集群”-“步骤”-“添加步骤”。

“应用程序位置”处请选择之前上传至S3的pyspark_job.py文件路径:

提交成功后可以在“步骤”菜单中可以看到当前步骤的状态和日志信息。
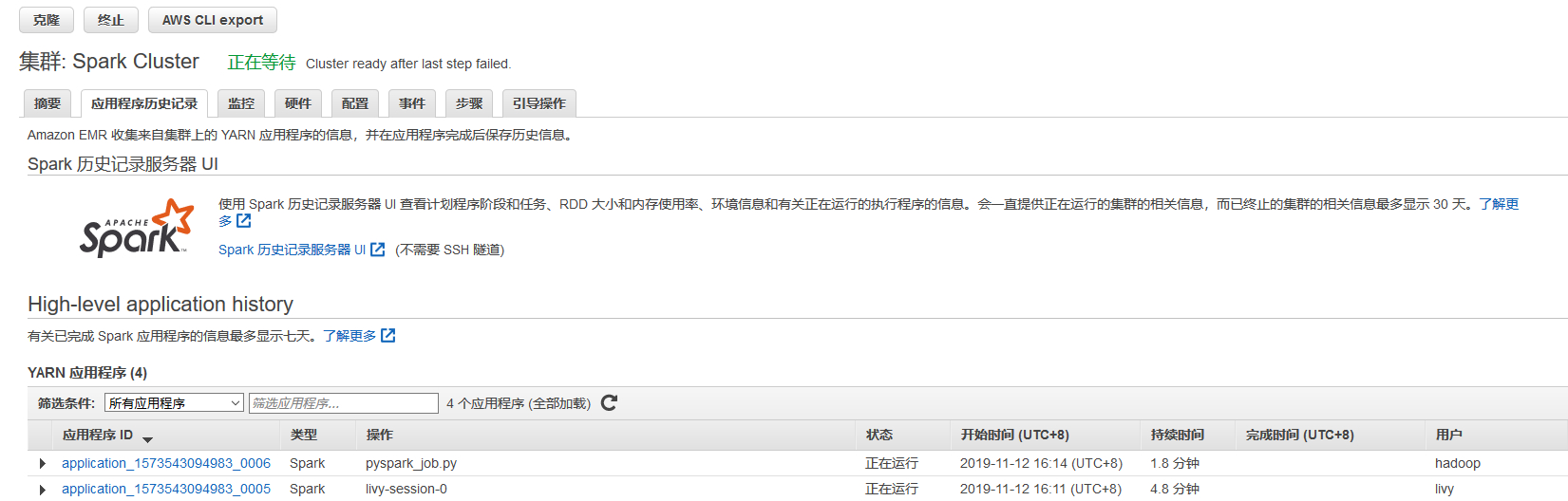
创建EMR一次性集群运行PySpark任务
通过控制台创建一次性集群
对于一些要求低成本的离线任务场景,可以借助步骤功能提交PySpark作业的工作流,并在工作流完成后自动关闭集群。离线任务可以利用S3和Glue数据目录存储计算结果和元数据,实现计算和存储分离。
要创建一次性集群,在“创建集群”-“软件与步骤”-“添加步骤”中勾选“最后的步骤完成后,集群自动终止”。

步骤完成后,我们可以在控制台中看到集群自动终止。

对并表后的数据进行查询
报表任务完成之后,可以在相应的Glue数据目录中看到新建的表,以及S3路径下新生成的数据文件:


常见的业务场景可能会要求对聚合后的数据表进行即席查询(ad-hoc query),即用户根据自己的需求随时调整查询条件。这种情景下使用Presto可以获得极佳的性能。Amazon Athena可以轻松实现交互式SQL查询的需求,无需预配置服务器,只需要在控制台中输入SQL语句就可以对之前存入Glue中的数据目录进行即时查询,查询所需时间可能低至数秒。
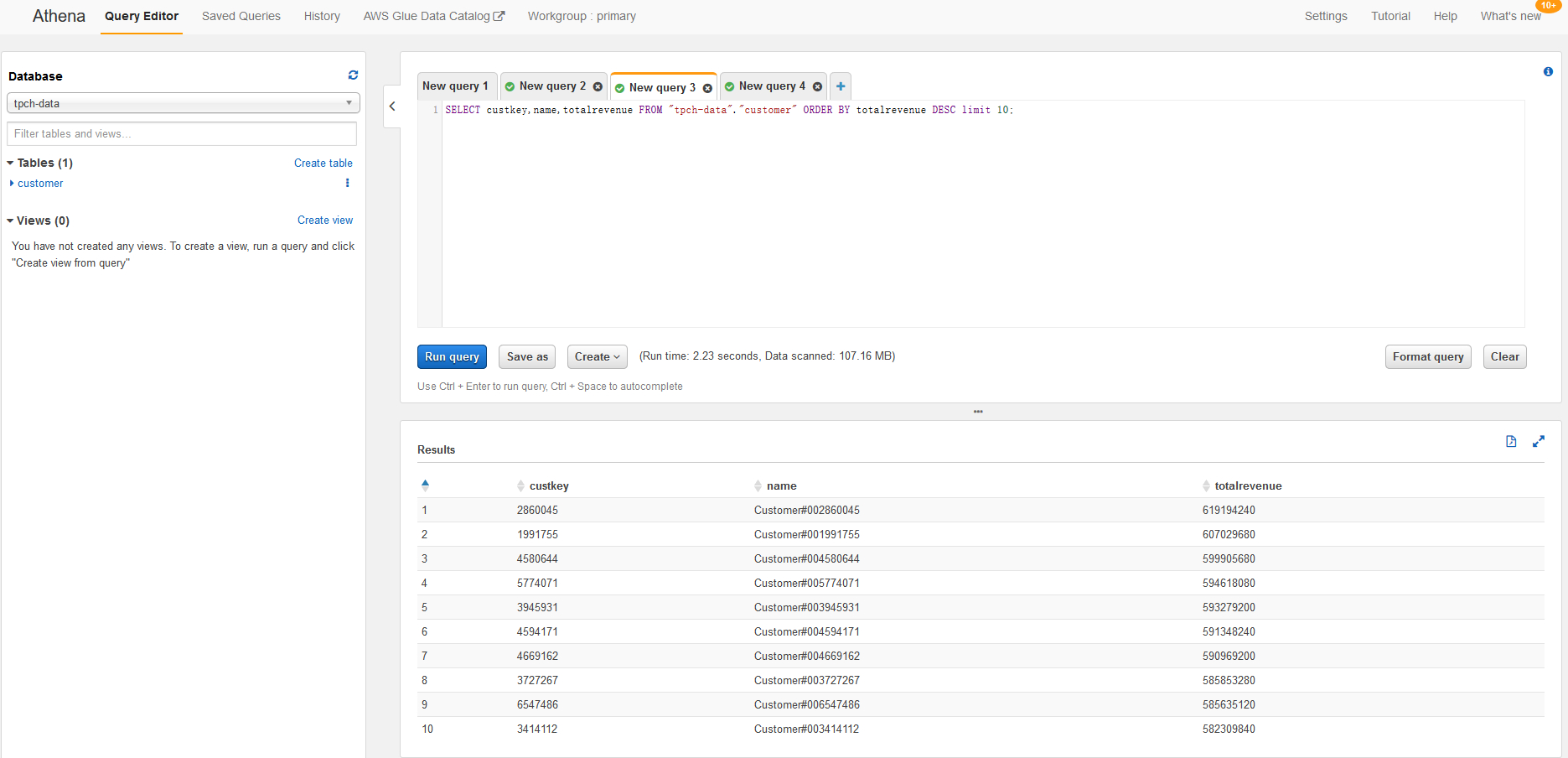
如果您之前使用了提供的示例脚本进行任务,可以使用Athena进行查询。比如,我们想要获取营收排名前十的客户名单,可以在Athena控制台中输入如下SQL语句:
SELECT custkey,name,totalrevenue FROM “tpch-data”.”customer” ORDER BY totalrevenue DESC limit 10;
结语
在此博客中,我们介绍了如何高效地利用Amazon EMR和PySpark编写和运行报表任务。参照博客中的操作进行实践后,您应该已经上手了EMR,并且能够通过PySpark编写自定义的业务逻辑。
要了解其他PySpark API功能,请参考PySpark文档。
要了解EMR,请参考Amazon EMR网页。