亚马逊AWS官方博客
在Amazon SageMaker中正确设计资源规划、避免非必要成本
Original URL: https://thinkwithwp.com/cn/blogs/machine-learning/right-sizing-resources-and-avoiding-unnecessary-costs-in-amazon-sagemaker/
Amazon SageMaker是一项全托管服务,可帮助您轻松构建、训练、部署以及监控机器学习(ML)模型。SageMaker采用的模块化设计,使您能够在机器学习生命周期中的不同阶段随时选择适合当前用例的功能。Amazon SageMaker可以将基础设施管理层面的繁重工作抽象剥离,配合多种不同功能与按实际使用量付费的计费标准,为您的大规模机器学习活动提供必要的敏捷性与可扩展性支持。
在本文中,我们将介绍Amazon SageMaker的计费模型,同时分享一系列最佳实践,旨在阐述如何对Amazon SageMaker的资源使用加以优化,借此有效控制机器学习模型的构建、训练与部署开销。此外,本文还提供相应编程方法,能够自动停止或检测出正在产生成本的闲置资源,帮助大家避免这部分非必要成本。
Amazon SageMaker计费标准
机器学习代表的是一种迭代过程,其中包含多种不同计算需求,分别用于对代码进行原型设计、探索数据集,以及面向实时及脱机预测模型执行处理、训练与托管等。在传统范例中,我们很难准确估算出不同工作负载具体需要何等数量的计算资源来支持,因此资源过度配置问题可谓屡见不鲜。Amazon SageMaker的模块化设计带来了出色的灵活性,能够根据机器学习生命周期中的各个阶段为机器学习工作负载带来可扩展性、性能与成本层面的显著优化。关于Amazon SageMaker运作方式的更多详细信息,请参阅以下资源:
下图所示,为机器学习生命周期当中各个阶段的模块化设计简要架构。每一套环境的构建(被称为、训练(以及相应调优)乃至部署,都将使用具有不同定价标准的独立计算资源。

关于在Amazon SageMaker上开展机器学习探索之旅的更多成本信息,请参阅使用Amazon SageMaker降低机器学习总体拥有成本并提高生产率。
使用Amazon SageMaker,我们只需要为实际使用的资源量付费。机器学习生命周期中的各个阶段也成为Amazon SageMaker相应资源的划分依据。在本节中,我们将沿着构建、处理、训练以及模型部署(或托管)的脉络逐一加以说明。
构建环境
Amazon SageMaker提供两种用于构建机器学习模型的环境,分别为 SageMaker Studio Notebooks 以及按需notebook实例。Amazon SageMaker Studio是一套面向机器学习应用的全集成开发环境,具有完善的协作、灵活性与托管的Jupyter notebook使用体验。现在,您可以免费访问Amazon SageMaker Studio这一全集成开发环境(简称IDE),且仅根据Studio中实际使用的AWS服务资源量付费。关于更多详细信息,请参阅Amazon SageMaker Studio导览。
Studio实例与按需实例属于两种费率相同的计算实例,具体参见Amazon SageMaker 计费标准中的说明。使用Studio,您的notebooks与相关工件(包括数据文件及脚本等)将持久驻留在 Amazon Elastic File System (Amazon EFS)当中。关于存储费用的更多详细信息,请参阅 Amazon EFS计费标准。
Amazon SageMaker按需notebook实例是一种全托管计算实例,专门负责运行Jupyter notebook应用。Amazon SageMaker负责创建实例及其相关资源。各Notebooks中则包含运行或者重新创建机器学习工作流所需要的一切。您可以在notebook实例中使用Jupyter notebook进行数据的准备与处理、编写模型训练代码,将模型部署至Amazon SageMaker当中进行托管,并对模型进行测试或验证。
处理
Amazon SageMaker Processing允许您在全托管基础设施之上轻松运行自己的模型预处理、后处理以及评估类工作负载。Amazon SageMaker将替您管理各实例,根据作业需求启动相应实例,并在作业完成之后终止实例。关于更多详细信息,请参阅 Amazon SageMaker Processing – 全托管型数据处理与模型评估服务。
训练与调优
根据训练数据集的实际大小与所需要的处理速度,大家可以使用单一通用型实例,也可以选择庞大的分布式GPU实例集群。Amazon SageMaker将代表您管理这些资源,并自动为训练作业配置、启动、而后停止/终止用于执行训练作业的计算资源。Amazon SageMaker训练与调优功能将保证您只需要根据实例在模型训练期间的运行时长付费。关于更多详细信息,请参阅对深度学习模型进行规模化训练与调优。
Amazon SageMaker自动模型调优,也被称为超参数调优,旨在立足您所定义的实例集群配合指定的算法与超参数范围,通过在数据集上运行多项训练作业以寻找模型的最佳版本。与训练作业类似,大家只需要为调优期间实际消耗的资源量付费。
部署与托管
您可以通过以下两种不同方式实现模型部署,进而执行推理:
- 用于实时推理的机器学习托管——在模型训练完成后,您可以将其部署在配备有Amazon SageMaker托管服务的持久端点上以实时获取预测结果。
- 批量转换——您可以使用Amazon SageMaker批量转换以离线形式获取完整的数据集预测结果。
Amazon SageMaker计费模型
下表所示,为Amazon SageMaker的计费模型汇总:
| 机器学习计算实例 | 存储 | 数据输入/输出 | |
| 构建(按需notebook实例) | 在notebook实例运行期间,以实例-小时为单位计算 | 按配置存储容量以GB-月为单位计算 | 无成本 |
| 构建(Studio Notebook) | 在notebook实例运行期间,以实例-小时为单位计算 | 详见Amaon Elastic File System (EFS) 计费标准. | 无成本 |
| 处理 | 在处理作业运行期间,以实例-小时为单位计算 | 按配置存储容量以GB-月为单位计算 | 无成本 |
| 训练与调优 | 按需实例:从各实例上线开始到停止/终止,每个实例按实例-小时为单位计算。不足完整实例-小时的部分按秒计费。
Spot Training: 使用Managed Spot Training通过竞价实例进行模型训练,与按需实例相比成本节约比例可达90% |
按配置存储容量以GB-月为单位计算 | 无成本 |
| 批量转换 | 在批量转换作业运行期间,以实例-小时为单位计算 | 无成本 | 无成本 |
| 部署(托管) | 在端点运行期间,以实例-小时为单位计算 | 按配置存储容量以GB-月为单位计算 | 按端点实例的已处理数据输入量(GB)与已处理数据输出量(GB)计算 |
本文建议大家从Amazon SageMaker 免费套餐.开始进行体验。关于计费标准的更多详细信息,请参阅 Amazon SageMaker计费标准。
为Amazon SageMaker notebooks、处理作业、训练以及部署设计正确的计算资源配置
根据各自对应的机器学习生命周期内各个阶段,您可以对实际使用的时长与资源进行成本细分,借此优化Amazon SageMaker的资源使用开销,保证仅为真正需要的资源付费。在本节中,我们将讨论一系列通行准则,借此为Amazon SageMaker机器学习生命周期选择正确的资源。
Amazon SageMaker目前提供多种机器学习计算实例选项,具体包括以下实例家族:
- T – 通用型峰值性能实例(适用于日常CPU资源使用量较低,但在必要时可爆发出极高性能的使用场景)
- M – 通用型实例
- C – 计算优化型实例(适用于高度依赖计算资源的应用场景)
- R – 内存优化型实例(旨在为需要处理内存内大型数据集的工作负载提供强大性能)
- P、G 与 Inf – 加速型计算实例(使用硬件加速器或协处理器)
- EIA – 推理加速型实例 (用于 Amazon Elastic Inference)
运行在Amazon SageMaker机器学习计算实例上的计算类工作负载,与运行在 Amazon Elastic Compute Cloud (Amazon EC2)实例上的工作负载适用于相同的实例类型。关于实例规格的更多详细信息,包括虚拟CPU数据及内存容量,请参阅Amazon SageMaker 计费标准。
构建环境
Amazon SageMaker notebook实例环境适用于交互式数据探索、脚本编写以及特征工程与原型建模。我们建议大家在交互构建方面使用容量较小的notebook实例,而其他更为繁重的作业——包括即席训练、调优与处理作业——则交由更大的实例负责。具体选择方式将在以下各节中加以说明。如此一来,即可避免大型实例(或GPU)始终随notebook同步运行。通过选择正确的实例,您将最大程度降低构建成本。
在构建阶段,Amazon SageMaker按需notebook实例的具体大小取决于您需要在内存中加载的探索性数据分析(EDA)数据量以及对应计算量。我们建议从通用型实例(例如T或M家族)起步,并根据需求随时做出调整。
支持峰值弹性的T实例家族非常适合notebook运行,因为其只会在运行notebook内各单元时才带来强度较大的CPU压力,平时工作负载较低。例如,ml.t2.medium实例就足以解决大部分基础数据处理、特征工程与EDA需求,而与之对应的小型数据集可以保存在4 GB内存当中。如果需要将更多数据加载至内存内以进行特征设计,则可以选择拥有更大内存容量的实例,例如ml.m5.12xlarge(192 GB内存)。如果特征工程还涉及大量计算作业(例如图像处理),本文建议大家选择计算优化型C实例家族,例如ml.c5.xlarge。
相较于按需notebook实例,Studio notebooks的主要优势在于其基础计算资源拥有更充分的弹性,允许用户即时变更实例,从而根据计算需求随时实现计算资源的规模伸缩。从ml.t3.medium 到 ml.g4dn.xlarge,随着构建类计算需求的增加,您的作业或基础设施管理流程不会发生任何中断。不同实例之间的往来移动将无缝实现,您能够在实例启动过程中继续工作。相比之下,按需notebook实例则要求大家停止当前实例、更新设置并使用新的实例类型并执行重新启动。
为了降低构建成本,我们建议大家停止使用按需notebook实例,或者在不需要时关闭Studio实例。此外,大家也可以使用AWS身份与访问管理(AWS Identity and Access Management,简称IAM)条件键作为限制特定用户所使用的部分实例类型(例如GPU实例)的有效方法,并借此控制成本。为了避免非必要开支,我们将在后文的建议部分详细介绍更多细节。
处理环境
在完成数据探索与原型设计,并准备将预处理及转换操作应用于完整数据集后,大家可以使用在EDA阶段编写的处理脚本启动Amazon SageMaker Processing作业,且无需对此前您所使用的、规模较小的notebook实例做出任何扩展。Amazon SageMaker Processing将把处理完整数据集过程中所需要的一切(包括代码、容器与数据)分派至独立于Amazon SageMaker notebook实例之外的计算基础设施当中。在作业完成后,Amazon SageMaker Processing还将负责资源供应、数据与工件传输,以及基础设施的关闭等操作。
使用Amazon SageMaker Processing的好处在于,您只需要在作业运行期间为处理实例付费。因此,您可以选择更为强大的实例,而不必过多担心成本问题。例如,作为一项通行建议,您可以使用ml.m5.4xlarge处理中等规模的作业(数据量在MB到GB级别),使用ml.c5.18xlarge处理需要大量计算资源的工作负载,也可以选择ml.r5.8xlarge将数GB数据加载至内存内以加快处理速度,并仅根据处理作业的运行时长付费。有时候,您也可以考虑使用更大的实例加快作业执行速度,这可能反而有助于降低总体作业成本。
此外,对于分布式处理作业,您可以增加实例数量以通过多个较小实例建立起集群。要采用这种方式,大家可以在ProcessingInput当中设置s3_data_distribution_type='ShardedByS3Key',通过Amazon Simple Storage Service (Amazon S3)键对输入对象进行分片,以确保各个实例接收到的输入对象数量大体相当,从而降低管理难度。如此一来,您可以在较小实例建立的集群中批量处理输入对象,显著节约成本。再有,您也可以使用.run(…, wait = False)异步执行处理作业,即在提交作业后立即释放notebook单元供其他活动使用,借此更高效地利用计算实例的构建时间。
训练与调优环境
Amazon SageMaker Processing中的计算范式与优势,也同样适用于Amazon SageMaker训练与调优作业。当您使用全托管Amazon SageMaker进行模型训练时,其会将训练作业所需要的一切内容(例如代码、容器与数据等)分派至独立于Amazon SageMaker notebook实例之外的计算基础设施当中。因此,您的训练作业将不会受到当前notebook实例的计算资源限制。您还可以通过调用.fit(…, wait = False)实现所支持的异步训练机制。以此为基础,您可以立即将notebook单元释放出来以供其他活动使用。例如,您可以在另一个机器学习计算实例中再次调用 .fit() 以建立新的训练作业,或者出于实验目的更改超参数设置。一般来说,机器学习训练往往是机器学习生命周期当中计算资源密度最大、耗费时间最长的部分,因此如果能够将训练作业放置在远程计算基础设施中异步进行,我们将可以安全关闭当前notebook实例以实现更全面的成本优化。在后文的建议部分中,我们将具体探讨如何自动关闭未使用的闲置按需notebook实例,借此避免非必要性成本。
在进行训练实例选择时,您需要考虑的成本优化因素包括:
- 实例家族——哪种类型的实例最适合训练?我们需要针对训练的总体成本进行优化,有时候选择单一大型实例能够显著加快训练速度,从而降低总体成本。另外,您还需要考虑所使用的算法能否支持GPU实例。
- 实例大小——算法在运行训练时所需要的最低计算资源与内存容量是多少?我们能否使用分布式训练机制?
- 实例数量——如果您可以使用分布式训练机制,那么应该在集群当中使用哪种实例类型(CPU或GPU)?具体实例数量应该如何计算?
在实例类型的选择方面,大家可以根据负责处理工作负载的实际算法或框架作出决定。如果您使用的是Amazon SageMaker内置算法,则无需复杂编程即可轻松启动作业,关于更多详细信息请参阅适用于内置算法的实例类型。例如,XGBoost目前只能使用CPU进行训练。面对这样一种内存绑定(对应于计算绑定)算法,通用型计算实例(例如M5)的效果要比计算优化型实例(例如C4)更好。
另外,我们还建议大家确保在选定的实例中分配充足的总内存容量,用于保存训练数据。尽管各实例支持使用磁盘空间处理不适合存放在主内存中的数据(通过libsym输入模式实现的非核外功能),但将缓存文件写入磁盘必然会减慢算法的处理速度。对于 ,我们支持使用以下GPU实例进行训练:
ml.p2.xlargeml.p2.8xlargeml.p2.16xlargeml.p3.2xlargeml.p3.8xlargeml.p3.16xlarge
本文建议大家使用内存容量更大的GPU实例进行大规模批量训练。当然,您也可以在多GPU及多设备上运行算法以实现分布式训练。
如果您打算在脚本模式或自定义容器中使用自有算法,则首先需要明确该框架或算法是否支持CPU、GPU或者同时支持两者,再据此确定用于运行工作负载的实例类型。例如,scikit-learn并不支持GPU,因此即使您的计算实例带有GPU加速机制,也不会在运行过程中带来任何实质性的收益(而只会带来更高的训练成本)。要确定实例类型与实例数量(包括是否采用分布式方式进行训练),我们强烈建议您对工作负载进行分析,保证找到实例数量与运行时长之间的最佳平衡点。关于更多详细信息,请参阅Amazon Web Services 在BERT与R-CNN上实现更快训练速度。此外,您还需要在实例类型、实例数量与运行时之间寻求平衡,关于更多详细信息,请参阅在Amazon SageMaker上通过TensorFlow训练ALBERT以实现自然语言处理。
对于采用GPU的P与G实例家族,我们还需要进一步考虑其中的差异因素。例如,P3 GPU计算实例善于处理大规模分布式训练任务,能够以更快速度完成训练;而G4实例则更适合强调成本效益的小型训练作业。
在训练方面,您需要考虑的另一个因素,在于选择使用按需实例抑或是竞价实例。在使用按需机器学习实例的情况下,您需要根据实例的实际运行时长及对应机器学习计算资源付费。但对于其他一些可以随时中断,或者不需要在特定时间启动的作业,您可以选择托管竞价实例(即Managed Spot Training选项)。与按需实例相比,Amazon SageMaker能够在竞价实例上将模型的训练成本降低达90%,并妥善帮助您处理竞价实例中断状况。
部署/托管环境
在大多数情况下,高达九成的机器学习应用开发与运行开支源自推理阶段;换句话说,我们需要一套性能强大、经济高效的机器学习推理基础设施。之所以存在如此明确的区分,是因为构建与训练作业在执行频繁方面相对更低,您只需要在构建与训练期间支付成本;但端点实例却一直在运行,意味着推理设施将持续产生运营成本。因此,能否选择正确的托管方式与实例类型将对机器学习项目的总体成本产生决定性的影响。
在模型部署方面,从用例出发逆推需求最为重要。您预计的运行频率如何?是否要求应用程序处理实时流量,并对客户做出实时响应?您是否针对同一用例面向不同数据子集训练出多套模型?您的预计流量会产生波动吗?您的用例对于推理延迟是否敏感?
Amazon SageMaker为每一种情况提供了对应的托管选项。如果您的推理数据为批量交付,则Amazon SageMaker 是一种理想的高成本效益方式,可随时启动及撤销全托管基础设施以实现灵活的预测能力。如果您已经针对同一用例训练出多套模型,则多模端点能够为按用户或其他细分条件训练而成的机器学习模型带来更优运营成本。关于更多详细信息,请参阅使用Amazon SageMaker多模端点节约推理成本。
在确定了模型的托管方式之后,大家还需要通过 确定适当的实例类型与集群大小。您可以在活动端点上启用自动规模伸缩功能,也可以禁用自动规模伸缩,借此避免过度配置或为非必要容量支付额外费用。另外需要注意的是,在GPU上具有最高训练效率的算法,也许无法在GPU实例上获得最好的推理计算效果。总而言之,负载测试已经成为确定最经济解决方案当中的一项最佳实践。以下流程图,对整个决策过程做出了总结。

Amazon SageMaker为各个实例家族提供更多细分选项,确保您能够从中选择最适合推理的通用型实例、计算优化型实例以及GPU驱动型实例。各个家族还针对不同的应用场景做出优化,当然其中某些实例类型可能并不适用于运行推理作业。例如,Amazon Inf1实例强调高吞吐量与低延迟,且能够实现云端运行状态下的最低单次推理成本。G4实例则属于单次推理成本最低的GPU型实例,能够带来更高性能、更低延迟与理想的推理成本。而P3实例专门针对训练作业进行优化,在设计中充分考虑到大型分布式训练任务的需求,因此虽然能以最快速度完成训练,但其资源却无法在推理作业中得到充分发挥。
另一种重要的推理成本降低方式是使用Elastic Inference,它能够将推理作业成本降低达75%。考虑到诸多具体因素与影响变量,我们往往很难准确判断最适合的实例类型与资源规模。例如,对于较大的模型,CPU上的严重推理延迟可能无法满足在线类应用场景的需求;成熟的GPU实例虽然速度更快,但可能难以提供符合要求的成本预期。另外,内存与CPU等资源对于应用程序整体性能的影响,可能比推理本身更为重要。借助Elastic Inference,您可以将适当数量的CPU推理加速资源挂载至任意Amazon计算实例之上。这项功能适用于Amazon SageMaker notebook实例与端点,能够为内置算法及深度学习环境提供加速增强。以此为基础,您可以更轻松地为自己的实际应用选择最具性价比的实例选项。例如ml.c5.large实例加 eia1.medium加速选项的组合在使用成本方面比ml.p2.xlarge低约75%,但性能差距却仅为10%到15%。关于更多详细信息,请参阅Amazon Elastic Inference – GPU支持型深度学习推理加速方案。
再有,您也可以要必要时使用 Auto Scaling for Amazon SageMaker,自动向端点添加或删除容量或加速实例。在这项功能的帮助下,您的终端端点可以根据实际负载(由策略中预定义的Amazon CloudWatch指标及目标值确定)对实例数量自动进行增加或减少,保证管理员不必持续监控推理负载与响应结果、并手动更改端点配置。关于更多详细信息,请参阅AWS Auto Scaling。
建议:避免非必要成本
某些Amazon SageMaker资源(例如处理、训练、调优以及批量转换实例)具有显著的临时性特征,Amazon SageMaker会自动启动实例并在作业完成后将其撤销。但是,也有一部分资源(例如构建计算资源或托管端点)拥有持久性特征,需要由用户控制何时停止/终止这部分资源。因此,我们需要明确了解如何识别闲置资源,并通过及时关停进一步实现成本优化。本节将向大家介绍实现此类流程的几种重要自动化方法。
构建环境:自动停止闲置的按需notebook实例
避免闲置notebook实例产生非必要成本的一种重要方式,就是使用生命周期配置自动停止闲置实例。通过Amazon SageMaker中的生命周期配置选项 ,您可以在notebook实例上安装软件包或示例notebook,借此实现notebook环境定制,包括配置网络与安全性,或者使用shell脚本完成其他自定义。由此带来的灵活性,将帮助大家更全面地控制notebook环境的设置与运行方式。
AWS维护着一套包含大量notebook生命周期配置脚本的公共repo,这些脚本能够解决notebook实例自定义当中的各类常见用例,当然也包括用于停止闲置notebook的示例bash脚本。
您可以使用生命周期配置设定您的notebook实例,使其在经过指定的闲置状态之后(通过参数进行设置)自动停止。Jupyter notebook的闲置状态定义方式请参阅此GitHub问题。要创建能够自动停止闲置实例的新生命周期配置,请参考以下操作步骤:
- 在Amazon SageMaker控制台上,选择 Lifecycle configurations。
- 选择 Create a new lifecycle configuration(如果需要创建新的生命周期配置)。
- 在Name部分,请使用字母
- 数字与-字符输入名称,但不支持使用空格。此名称最多可包含63个字符,例如
Stop-Idle-Instance。 - 要创建每次创建notebook及启动notebook时运行的脚本,请选择 Start notebook。
- 在Start notebook editor当中,输入该脚本。
- 选择 Create configuration。
您可以在AWS生命周期配置示例repo中获取相应bash脚本。该脚本会根据脚本内IDLE_TIME参数所定义,在特定闲置时段内运行一项cron作业。您可以结合实际需求更改此时间,并根据需要在Lifecycle configuration页面中更改脚本内容。
为了让脚本正常起效,notebook还应满足以下两个条件:
- Notebook实例应能够接入互联网,借此从公共repo中获取示例配置Python脚本(
autostop.py)。 - 指向
SageMaker:StopNotebookInstance的notebook实例执行角色权限可停止该notebook,指向SageMaker:DescribeNotebookInstance的角色权限则可描述该notebook。
如果您不希望在接入互联网的VPC中创建notebook实例,则需要在bash脚本中内联添加Python脚本。该脚本同样可通过 GitHub repo获取。如下所示,在您的bash脚本中添加对应内容,并将其应用于生命周期配置:
以下截屏所示,为如何在Amazon SageMaker控制台上选择生命周期配置。
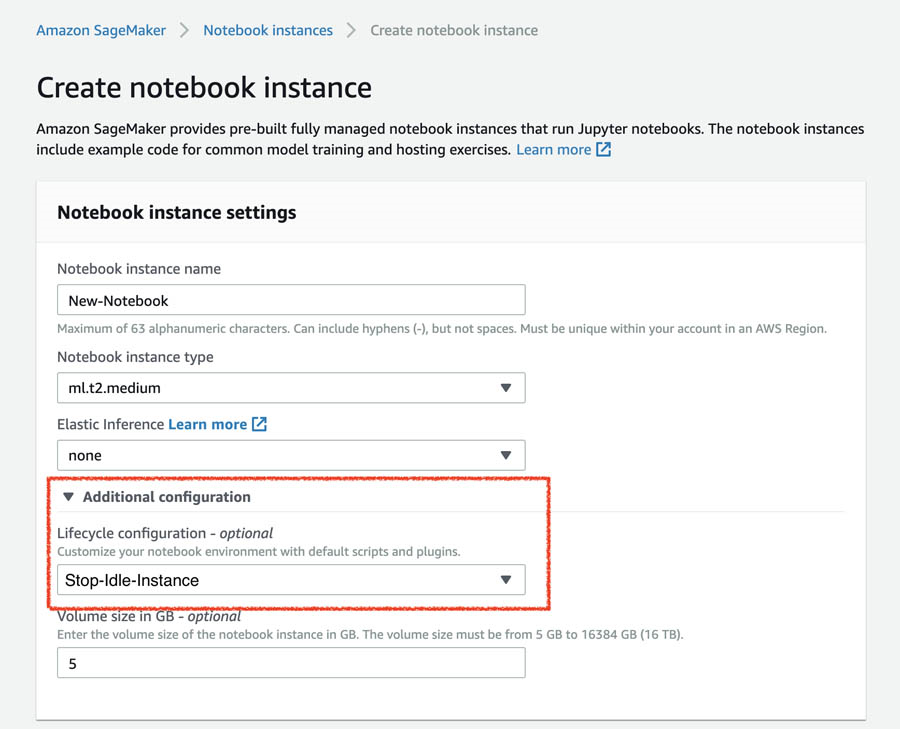
此外,您也可以将该脚本保存在Amazon S3上,并通过VPC端点接入该脚本。关于更多详细信息,请参阅新增功能——用于Amazon S3的VPC端点。
现在,我们已经创建了生命周期配置,可以在创建新的notebook、或者更新现有notebook时,将其分配给按需notebook实例。要使用生命周期配置创建notebook(本文示例中为Stop-Idle-Instance),大家需要在Additional Configuration部分下将该脚本分配给目标notebook。其他操作步骤与创建一个按需notebook实例部分完全相同。要将生命周期配置附加至现有notebook,您首先需要停止该按需notebook实例,而后选择Update settings对该实例进行变更,而后在Additonal configuration部分附加新的生命周期配置。
构建环境:规划按需notebook实例的启动与停止
下面,我们将介绍另外一种能够在特定时段规划notebook启动与停止的方法。例如,如果您希望在工作日(周一到周五)的上午7:00启动notebook(包括特定分组内的notebook,或者账户中的所有notebook),并在晚间9:00停止所有notebook,则可通过Amazon CloudWatch Events加AWS Lambda函数这一组合来实现。关于配置Lambda函数的更多详细信息,请参阅在AWS Lambda控制台中配置函数。要为该用例建立时间表,大家可以按照以下各节中的说明进行操作。
使用Lambda函数启动notebook
要使用Lambda函数启动notebook,请完成以下操作步骤:
- 在Lambda控制台上,选择create a Lambda function以启动按需notebook实例,并在名称中使用特定关键字。在本文示例中,我们的开发团队在所有按需notebook实例的名称开头使用了 dev-前缀。
- 使用Python作为函数的运行时,并将函数命名为 start-dev-notebooks。
您的Lambda函数应在其执行IAM角色上添加SageMakerFullAccess策略。
3.在 Function代码编辑区,输入以下脚本:
4.在Basic Settings之下,将Timeout调整为15分钟(最大)。
这一步可以保证该函数在停止及启动多个notebook时,拥有最大的允许超时范围。
5.保存您的函数。
使用Lambda函数停止notebook
要使用Lambda函数停止您的notebook,请遵循以下操作步骤,使用以下脚本,并将函数命名为 stop-dev-notebooks:
创建CloudWatch事件
现在,您已经创建了必要的函数,接下来需要创建事件以根据特定时间表触发这些函数。
在这里,我们使用cron表达式设定调度计划。关于创建自定义cron表达式的更多详细信息,请参阅用于建立规则的调度表达式。所有计划内调度事件均使用UTC时区,且最低时间精度为1分钟。
例如,适用于全年范围内周一到周五早7:00的cron表达式写为 0 7 ? * MON-FRI *,而同一天内晚9:00的表达式写为 0 21 ? * MON-FRI *。
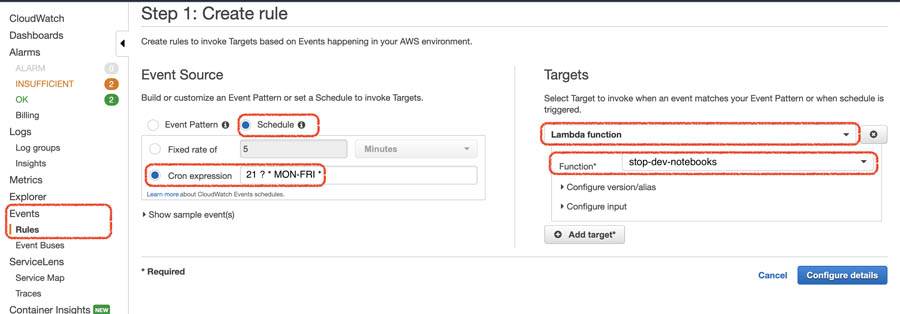
要创建能够按调度计划停止各实例的事件,大家需要完成以下操作步骤:
- 在CloudWatch控制台的Events之下, 选择 Rules。
- 选择 Create rule。
- 在 Event Source之下,选择Schedule,而后选择Cron expression。
- 输入您的cron表达式(例如
21 ? * MON-FRI *,意为周一至周五晚9:00)。 - 在Targets之下, 选择 Lambda function。
- 从列表中选择您的函数(在本文示例中,为
stop-dev-notebooks)。 - 选择 Configure details。
- 为您的事件添加名称,例如
Stop-Notebooks-Event,外加相关描述。 - 保持Enabled。
- 选择 Create。
大家可以采取相同的操作步骤创建notebook启动计划,根据调度要求在特定时间(例如工作日上午7:00)启动notebook,保证员工在上班时各notebook已经准备就绪。
托管环境:自动检测闲置Amazon SageMaker端点
大家可以将机器学习模型部署为端点,借此测试模型的实时推理效果。有时候,这些端点可能意外长期处于服务状态,导致账户不断产生相关成本。您可以使用CloudWatch Events与Lambda函数自动检测这些端点,并及时采取纠正措施(例如将其删除)。例如,您可以检测各端点在过去几个小时内是否始终处于闲置状态(例如在过去24小时或其他特定时段内,从未接受调用)。我们在本节中提供的功能脚本可用于检测闲置端点,并使用闲置端点列表将检测结果发布至Amazon Simple Notification Service (Amazon SNS)主题。作为账户管理员,您可以订阅该主题,保证在检测到此类闲置状况时收到包含闲置端点列表的电子邮件。要创建这样一项调度事件,具体操作步骤如下:
- 创建一个SNS主题,并使用您的电子邮件或手机号码进行订阅。
- 使用以下脚本创建一项Lambda函数 :
- 您的Lambda函数应将以下策略附加至其IAM执行角色当中:
CloudWatchReadOnlyAccess, AmazonSNSFullAccess与AmazonSageMakerReadOnly.
- 您的Lambda函数应将以下策略附加至其IAM执行角色当中:
您也可以修改这部分代码,以根据资源标签过滤各个端点。关于更多详细信息,请参阅AWS Python SDK Boto3说明文档。
调查各端点
此脚本将发送一封包含检测到的闲置端点列表的电子邮件(或者文本消息,具体取决于您SNS主题的配置方式)。接下来,您可以登录至Amazon SageMaker控制台并调查对应端点,并在确定其属于闲置端点时将其删除。具体操作步骤如下:
- 在Amazon SageMaker控制台的Inference之下, 选择 Endpoints。
您可以看到当前区域中账户内的所有端点列表。
- 选择您希望调查的端点,并在Monitor之下选择View invocation metrics。
- 在All metrics之下,选择Invocations。
您可以在端点上看到相应的调用活动。如果您在指定的时段之内未发现任何调用事件(或活动),则表示该端点处于闲置状态,可以将其删除。
- 在确定要删除的端点后,请返回端点列表,选择要删除的端点,而后在Actions菜单下选择
总结
本文向大家介绍了Amazon SageMaker的计费标准,根据机器学习项目内各个阶段正确调整Amazon SageMaker计算资源大小的最佳实践,以及如何通过自动停止闲置的按需notebook实例以避免产生非必要运营成本的具体方法。最后,我们还分享了如何自动检测Amazon SageMaker端点以保证不致发生误删情况。
在了解到Amazon SageMaker的工作方式与Amazon SageMaker资源的计费模型之后,相信大家能够更有针对性地对机器学习项目总体成本做出优化。