亚马逊AWS官方博客
基于AWS machine learning bot 的 named-entity recognition (NER) 快速解决方案
Amazon machine learning bot为用户提供了一种快速的开箱即用的解决方案,其底层基于Amazon SageMaker 将机器学习模型的定制及部署实现了高效的自动化。并且, ML bot 提供了可视化、易操作的web user interface界面。用户可以上传具体应用场景的图片或文字数据,快速完成从数据标注,模型训练到模型效果评估的全部流程。
本文重点介绍了如何运用ML的 命名实体识别(name entity recognition)来快速构建自然语言处理的API功能。具体内容如下:
1. Machine learning bot 框架介绍
ML bot是一个一键式的打包封装的机器学习解决方案,它提供了多种不同类型的原始机器学习模型,并且可以根据需求通过互相交互来评价模型。在一键式应用的基础上,ML bot也确保了数据的安全性,基于Amazon云技术的加密和授权,用户可以把数据储存在Amazon的云端并直接导入到ML bot的模型当中。ML bot不仅拥有用户友好的人性化交互界面,也为用户提供了实时更新的最新机器学习模型。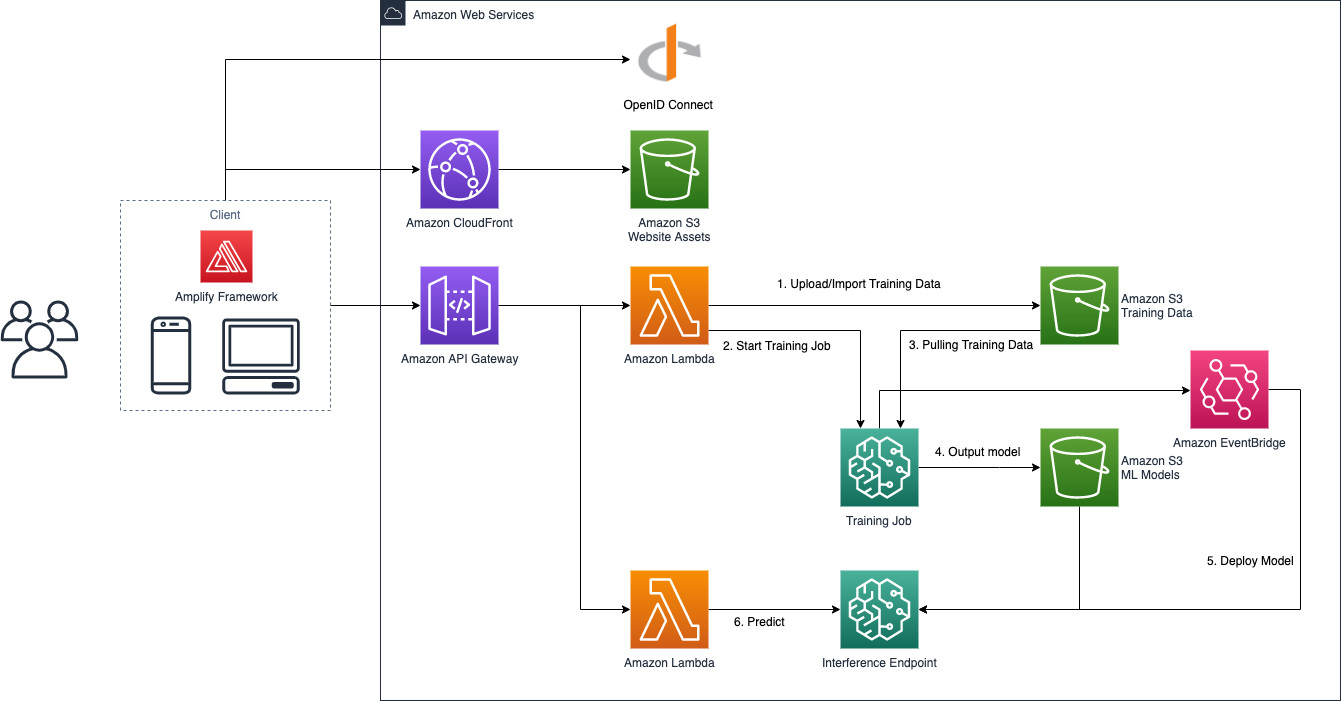
本文中我们采用了ML bot下的命名实体识别模型(NER)。命名实体识别是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。命名实体识别是信息提取、问答系统、句法分析、机器翻译等应用领域的重要基础工具,作为结构化信息提取的重要步骤,该模型可以在后续阶段通过对不同文本内容的分析然后被应用于快速消费品,金融和医疗等领域中。
2. 数据集说明
为了在ML bot上展示我们的模型,我们采用了从社交媒体上采集来的包含命名实体的公开数据集作为我们的训练集。该数据集中的文本采用UTF-8进行编码,每行为一个段落标注,共包括2000段落。所有的实体以如下的格式进行标注: {{实体类型:实体文本}}
标注的实体类别包括以下六种:time: 时间 location: 地点 person_name: 人名 org_name: 组织名 company_name: 公司名 product_name: 产品名。
例:此次{{location:中国}}个展,{{person_name:苏珊菲利普斯}}将与她80多岁高龄的父亲一起合作,哼唱一首古老的{{location:威尔士}}民歌{{product_name:《白蜡林》}}。届时在{{location:画廊大厅}}中将安放6个音箱进行播放,艺术家还特意回到家乡{{location:格拉斯哥}},同父亲一起在{{org_name:中国音乐学院}}里为作品录制了具有{{location:中国}}元素的音乐片段。
3. Machine learning bot的named-entity recognition (NER)使用步骤
由于我们大部分的数据都存储在Amazon海外区的Simple Storage Service(S3)中,本文将着重介绍通过海外区Amazon来部署ML bot,详细的步骤可以参考ML bot的documentations(http://ml-bot.s3-website.cn-north-1.amazonaws.com.cn/deploy/)。首先,我们需要在Amazon CloudFormation上创建一个新的堆栈,并导入预先设置好的ML bot的模板。
随后在Cloud9控制台里面,为刚刚创建好的堆栈新建一个环境,在新建过程始终保持使用默认配置并在完成后为该环境赋予一个具有administrator access的identity and access management(IAM) role,有关Amazon Web Service(AWS)的详细信息可以参考相关的Amazon documentations(https://thinkwithwp.com/iam/)。
最后,在Amazon的Cognito用户池中找到与之前创建的堆栈相同UserPoolId的用户池,在该用户池的配置页面中选择“用户和组”并点击“创建用户”,输入用户名和密码等必要信息之后进行邮件确认。从Amazon Cloudformation下找到创建好的堆栈并在Outputs标签下找到CloudFrontDomain,点击进入该页面并使用刚刚设置好的用户名和密码登录并开始使用ML bot。

在ML bot的主页面下选择“Get Started”并在下一个页面中选中“Named Entity Recognition”模型,上传训练用的数据集所在的S3地址。
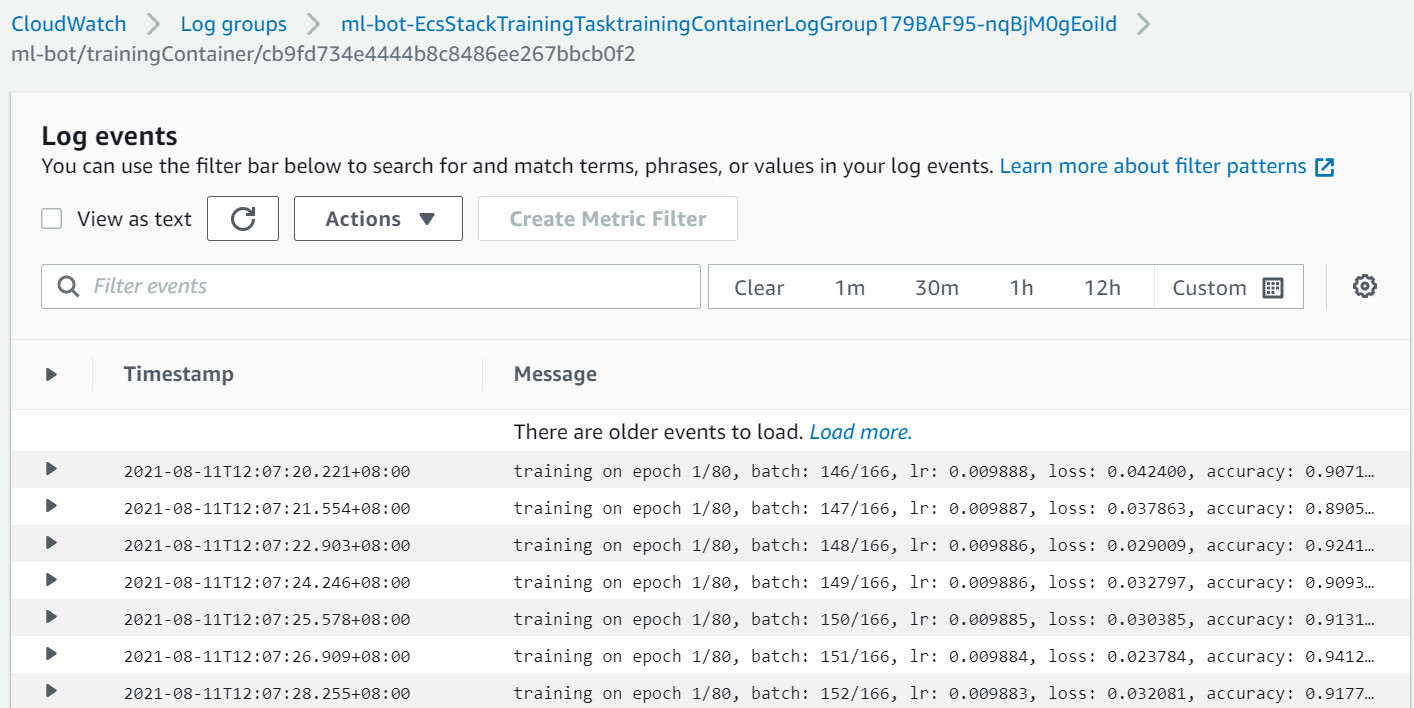
点击“Start Model Training”并等待模型训练完成,在训练过程中可以通过点击“View logs in CloudWatch”来查看模型的训练情况及accuracy的评分(如下图),ML bot的NER模型在使用我们提供的training data下,accuracy基本稳定在0.9以上并在训练过程中逐渐向1.0接近,说明该模型相对比较稳定。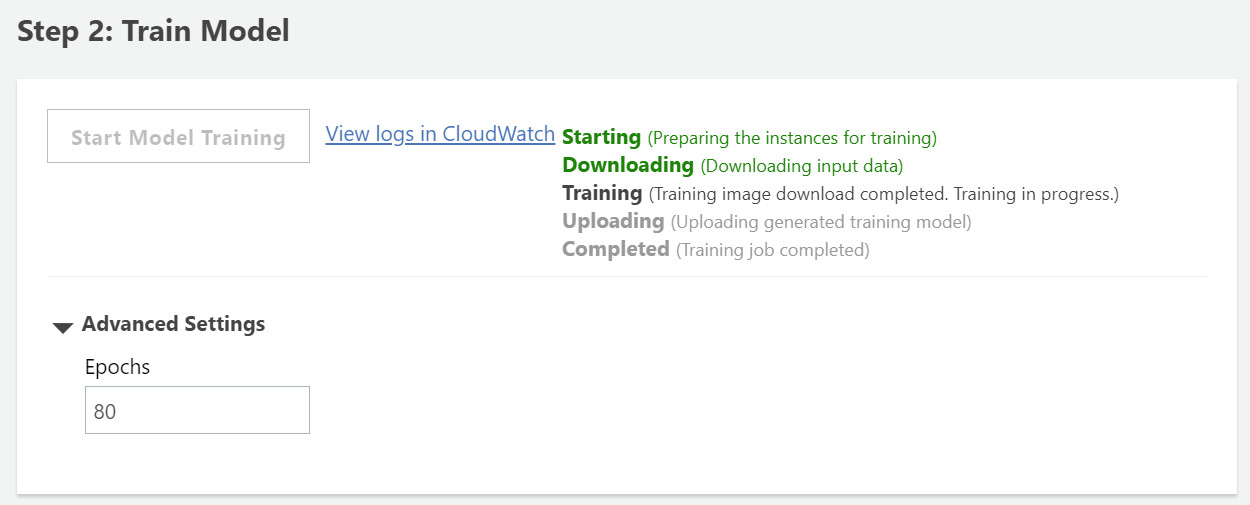
训练完成的模型可以使用任意的中文文本字段来进行测试,具体结果如下图。经过训练的ML bot的NER模型成功学习了并预测和提取出了时间和组织名相关的命名实体。该条测试用的文本来自于当天的热门新闻。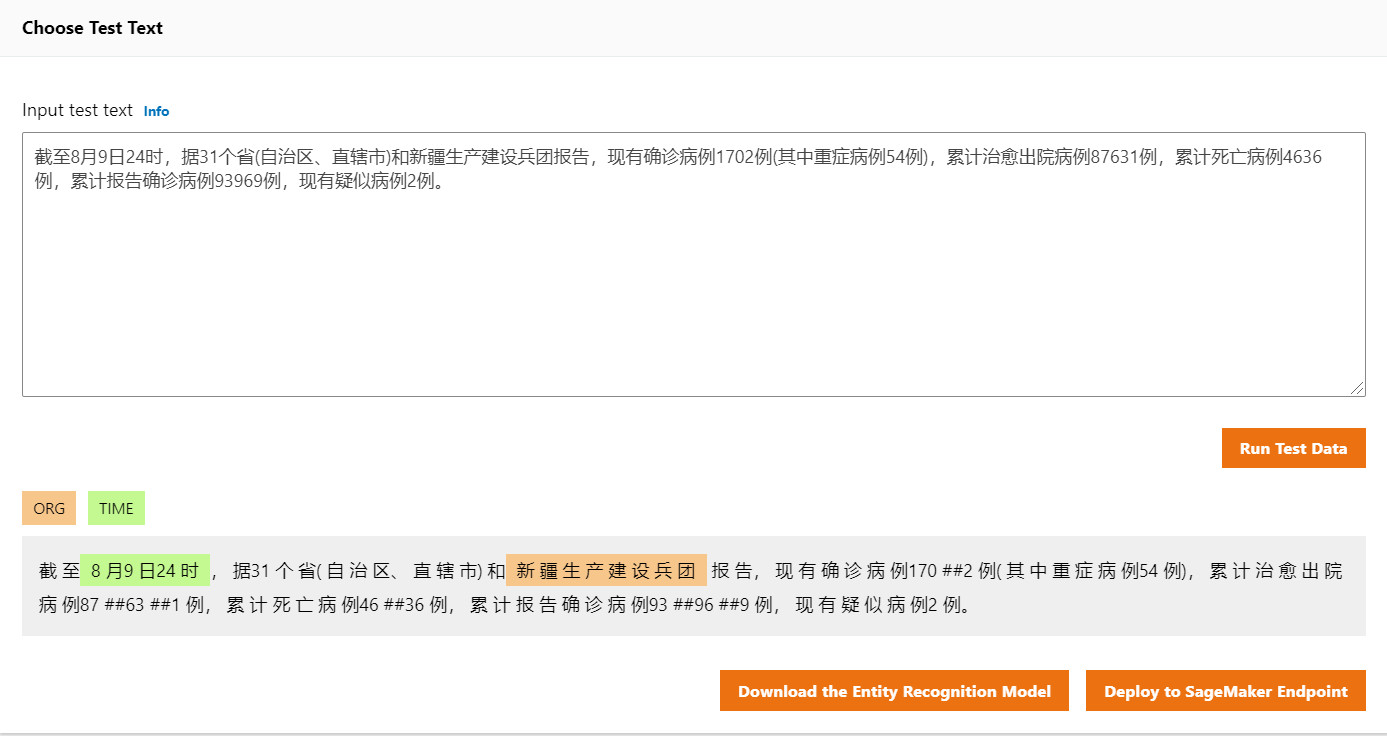
4. API部署及测试
在ML bot的NER模型结果页面的右下角的“Deploy to SageMaker Endpoint”选项可以一键把已经训练好的NER模型部署到Amazon SageMaker Endpoint上作为可调用的API使用,具体的调用方法和结果如下图所示。对比直接在ML bot网站使用NER模型,将模型打包成API使得模型具有更多的灵活性,可以将封装好的模型作为命名实体预测的环节来嵌入到不同的模型流水线中。这一套逻辑和流程不仅操作简单,代码实现也较容易,更可以被应用于多样化的业务场景中,具有一定的普适性。
5. 结论
本文介绍了如何运用Amazon ML bot来快速建立NER模型。用户可以把数据安全的储存在Amazon S3上并导入到该模型中来实现机器学习模型的训练。训练完成的模型在预测准确度上表现良好。模型的调用不仅可以在简易操作的Amazon ML bot页面上直接实现,也可以部署到Amazon Sagemaker Endpoint上作为一个独立的API来调用。我们认为该套方案在具备易操作和易实现的前提下,更具有非常广泛的适用性,能够很好的解决一些企业需要机器学习解决方案同时又缺乏相关领域技术经验与积累的商业痛点。