亚马逊AWS官方博客
企业级数据共享规模化模式
数据共享正在成为企业数据战略的重要元素。对于公司而言,AWS Data Exchange 这样的 AWS 服务提供了与其他公司共享增值数据或从这些数据获利的途径。一些企业希望有一个数据共享平台,他们可以在该平台上建立协作和战略方法,在封闭、安全和排外的环境中,与有限的一组公司交换数据。例如,金融服务公司与其审计公司,或制造公司与其供应链合作伙伴。这可以促进新产品和服务的开发,并有助于提高其运营效率。
数据共享是一项团队工作,值得注意的是,在构建合适的基础设施之外,成功的数据共享还需要企业确保业务负责人支持数据共享计划。他们还需要确保提供高质量的数据。数据平台所有者和安全团队应鼓励正确使用数据,并修复任何隐私和保密问题。
本文讨论了各种数据共享选项以及常见架构模式,企业可以采用这些模式,基于 AWS 服务可用性和数据合规性来设置其数据共享基础设施。
数据共享选项和数据分类类型
企业在运营时受各种安全合规要求的约束。一些企业可以使用像 AWS Data Exchange 这样的 AWS 服务。但是,一些机构在受严格监管的行业中开展工作,例如联邦机构或金融服务等,他们可能会受到限制,只能使用明示允许的 AWS 服务选项。例如,如果某个企业被要求在 Fedramp Medium 或 Fedramp High 环境中运营,则他们共享数据的选项可能会限制为可用且已明示允许的 AWS 服务。服务可用性基于 AWS 的平台认证,允许列表则基于企业对其安全合规性架构和准则的定义。
企业要与其合作伙伴共享的数据类型,也可能会对用于数据共享的方法产生影响。遵守数据分类规则可能会进一步限制他们能够选择的数据共享选项。
以下是一些常规数据分类类型:
- 公共数据 – 重要信息,但通常可供人们免费读取、研究、查看和存储。这些数据通常具有最低的数据分类和安全级别。
- 私有数据 – 您可能需要保密的信息,例如电子邮件收件箱、手机中的内容、员工识别号码或员工地址。私有数据如果被共享、销毁或更改,可能会对个人或企业构成轻微的风险。
- 机密或受限数据 – 有限的个人或团体可以访问的敏感信息,通常需要特别许可或特别授权。对机密或受限数据的访问可能涉及身份和授权管理等方面。机密数据的示例包括社会安全号码和车辆识别号。
以下是决策树示例,在根据服务可用性、分类类型和数据格式(结构化或非结构化)选择数据共享选项时,您可以参考该决策树。其他因素,例如可用性、多个合作伙伴可访问性、数据大小、使用模式(批量加载/API 访问)等,也可能会影响数据共享模式的选择。

在以下部分中,我们将详细地讨论每个模式。
模式 1:使用 AWS Data Exchange
AWS Data Exchange 简化了数据交换过程,帮助企业降低成本、提高敏捷性并加快创新。企业可以选择使用 AWS Data Exchange 与外部合作伙伴私密共享数据。AWS Data Exchange 提供在身份和资源级别应用的边界控制。这些控制措施决定哪些外部身份有权访问特定的数据资源。AWS Data Exchange 为外部各方访问数据提供了多种不同的模式,例如:
- AWS Data Exchange for Amazon Redshift
- AWS Data Exchange for AWS Lake Formation(目前为预览版)
- 适用于数据 API 的 AWS Data Exchange
- 适用于数据文件的 AWS Data Exchange
- AWS Data Exchange for Amazon S3(目前为预览版)
下图展示了一个示例架构。
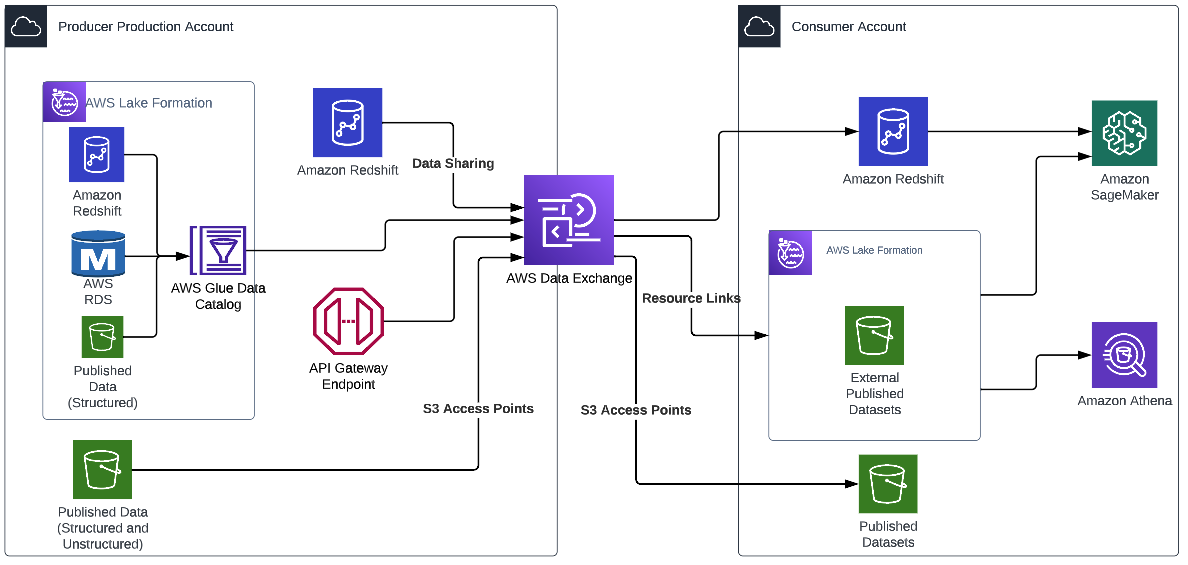
借助 AWS Data Exchange,在配置了要共享(或销售)的数据集后,AWS Data Exchange 就会自动管理创建者和使用者之间的授权(和账单)。创建者不必管理政策、设置新的接入点或为每个使用者创建新的 Amazon Redshift 数据共享,在订阅结束时会自动撤销访问权限。这可以显著减少共享数据的操作开销。
模式 2:使用 AWS Lake Formation 进行集中访问管理
在创建者和使用者均使用 AWS 服务,且具有可以使用 AWS Lake Formation 的 AWS 账户时,您可以使用这种模式。这种模式提供了一种无需编写代码的数据共享方法。下图展示了一个示例架构。
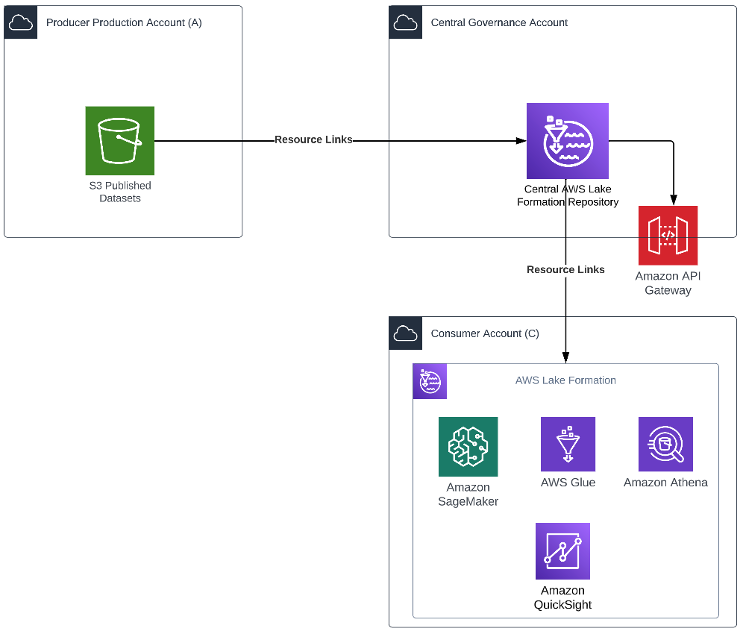
在这种模式下,中央监管账户配置了 Lake Formation,用于管理创建者企业账户的访问权限。来自生产账户 Amazon Simple Storage Service(Amazon S3)存储桶中资源的链接在 Lake Formation 中创建。创建者将 AWS Glue Data Catalog 资源上的 Lake Formation 权限授予外部账户,或者直接授予其他账户中的 AWS Identity and Access Management(IAM)主体。Lake Formation 使用 AWS Resource Access Manager(AWS RAM)来共享资源。如果被授予者账户与授予者账户属于同一企业,则可立即向被授予者提供共享资源。如果被授予者账户不属于同一企业,则 AWS RAM 会向被授予者账户发送邀请,以便其接受或拒绝资源授予。要使共享资源可供使用,被授权者账户中的使用者管理员必须使用 AWS RAM 控制台或 AWS 命令行界面(AWS CLI)接受邀请。
获得授权的主体可以与外部账户中的 IAM 主体明确共享资源。当创建者想要控制外部账户中可以访问其资源的用户时,此功能很有用。IAM 主体获得的权限是直接授予的权限,加上与在账户级授予并向下传递到主体的权限。接收方账户的数据湖管理员可以查看直接的跨账户授权,但无法撤消权限。
模式 3:从创建者外部共享账户中使用 AWS Lake Formation
创建者可能有严格的安全要求,任何外部使用者都不应访问其生产账户或其集中治理账户。他们也可能没有在其生产平台上启用 Lake Formation。在这种情况下,如下图所示,创建者的生产账户(账户 A)专用于其内部企业用户。创建者创建另一个账户,即创建者的外部共享账户(账户 B),专用于外部共享。这使得创建者有更大的自由度,可针对特定企业创建特定策略。
以下架构图显示了模式概览。
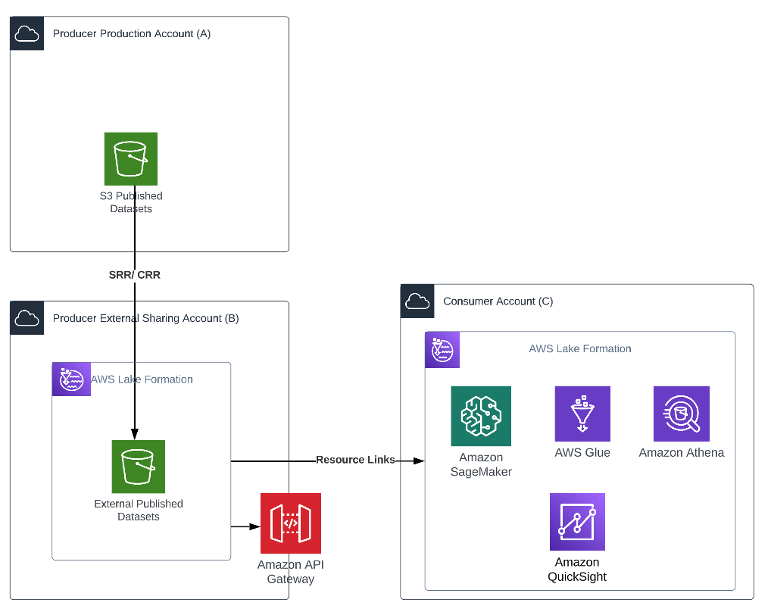
创建者实施了一个流程,在账户 B 中创建数据的异步副本。对于需要共享的对象,可以将存储桶配置为同区域复制(SRR,Same Region Replication)或跨区域复制(CRR,Cross Region Replication)。这可以帮助自动将数据刷新到外部账户的 External Published Datasets(外部已发布数据集)S3 存储桶,而无需编写任何代码。
通过创建数据的副本,创建者可以进一步隔离外部使用者与其生产数据。它还可以帮助满足任何合规性或数据主权要求。
Lake Formation 设置在账户 B 上,管理员为其账户中的 External Published Datasets(外部已发布数据集)S3 存储桶创建资源链接,用以授予访问权限。管理员按照前述的相同过程授予访问权限。
模式 4:使用 Amazon Redshift 数据共享
这种模式非常适合主要在 Amazon Redshift 上发布数据产品的创建者。这种模式还要求创建者的外部共享账户(账户 B)和使用者账户(账户 C)均具有加密的 Amazon Redshift 集群或 Amazon Redshift Serverless 端点,并且它们满足 Amazon Redshift 数据共享先决条件。
以下架构图显示了模式概览。
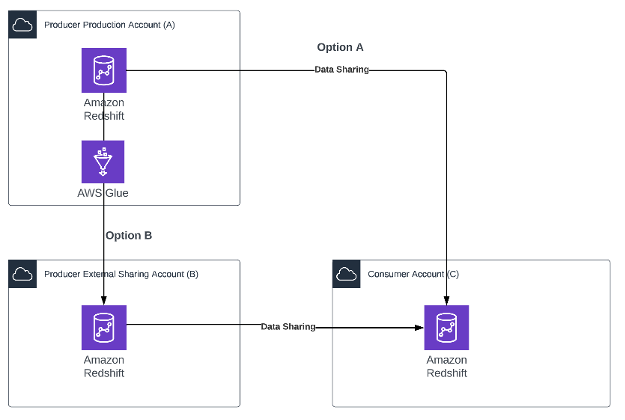
根据创建者的合规性限制,可以有两种选择:
- 选项 A – 创建者直接在生产 Amazon Redshift 集群上启用共享数据。
- 选项 B – 创建者可能会在共享生产集群方面进行限制。创建者创建一个简单的 AWS Glue 作业,从生产账户 A 的 Amazon Redshift 集群中,将数据复制到外部账户 B 的 Amazon Redshift 集群。此 AWS Glue 作业可以根据使用者的需要安排刷新数据。当账户 B 中有数据时,创建者可以根据需要创建多个视图和多个数据共享。
在这两个选项中,创建者可以完全控制共享哪些数据,而使用者管理员则完全控制其企业中的哪些用户可以访问数据。
在创建者和使用者管理员都批准了数据共享请求后,使用者用户可以访问这些数据,就好像这些数据存在于自己的账户中一样,无需编写任何额外的代码。
模式 5:使用 API 安全私密地共享数据
当外部合作伙伴没有使用任何 AWS 服务时,您可以采用这种模式。如果已发布的数据产品分布在多种服务上(例如,Amazon S3、Amazon Redshift、Amazon DynamoDB 和 Amazon OpenSearch Service),而创建者希望保持单一的数据共享接口时,您也可以使用此模式。
这种使用场景示例如下:A 公司希望与其合作伙伴公司 B 近乎实时地共享一些日志数据,B 公司使用这些数据为 A 公司生成预测洞察。A 公司将这些数据存储在 Amazon Redshift 中。A 公司希望首先遮蔽个人身份信息(PII),然后再与合作伙伴分享事务数据,以经济实惠且安全的方式来生成洞察。B 公司不使用 AWS 服务。
A 公司使用 AWS Lambda 函数或 AWS Glue 建立小型批处理流程,该流程查询 Amazon Redshift 以获取增量日志数据,应用规则来遮蔽 PII,并将这些数据加载到 Published Datasets(已发布数据集)S3 存储桶。这将实例化 SRR/CRR 进程,该进程刷新 External Sharing(外部共享)S3 存储桶中的这些数据。
下图显示了使用者随后如何通过基于 API 的方法来访问这些数据。
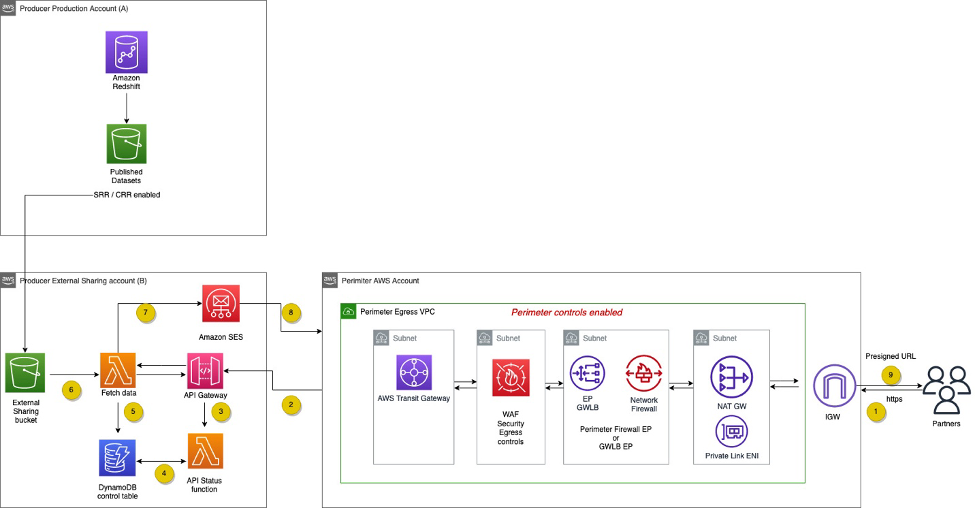
该工作流包含以下步骤:
- API 使用者发送 HTTPS API 请求到 API 代理层。
- API 代理将 HTTPS API 请求转发到外部共享 AWS 账户中的 Amazon API Gateway。
- Amazon API Gateway 调用请求接收方 AWS Lambda 函数。
- 请求接收方函数将状态写入 DynamoDB 控制表。
- 第二个 Lambda 函数是轮询器,用于在 DynamoDB 表中检查结果的状态。
- 轮询器函数从 Amazon S3 提取结果。
- 轮询器函数通过 Amazon Simple Email Service(Amazon SES),向请求方发送预签名 URL,以便从 S3 存储桶中下载文件。
- 请求方使用该 URL 下载文件。
- 网络边界 AWS 账户仅允许传出互联网连接。
- 在流量传出创建者的网络边界之前,API 代理层会强制执行传出安全控制和边界防火墙。
- AWS Transit Gateway 安全传出 VPC 路由表仅允许从所需的创建者子网进行连接,同时防止互联网访问。
模式 6:使用 Amazon S3 接入点。
数据科学家可能需要合作处理图像、视频和文本文档。法律和审计团队可能需要与审计机构共享报告和报表。本模式讨论了共享此类文档的方法。本模式假设外部合作伙伴也在使用 AWS。Amazon S3 接入点让创建者可以设置跨账户存取,从而与其使用者共享访问权限,而无需编辑存储桶策略。
接入点是附加到存储桶的指定网络端点,可用于执行 S3 对象操作,例如 GetObject 和 PutObject。每个接入点都有不同的权限和网络控制,Amazon S3 对通过该接入点执行的任意请求应用这些权限和网络控制。每个接入点都会强制执行自定义的接入点策略,该策略与附加到底层存储桶的存储桶策略结合在一起使用。
以下架构图显示了模式概览。
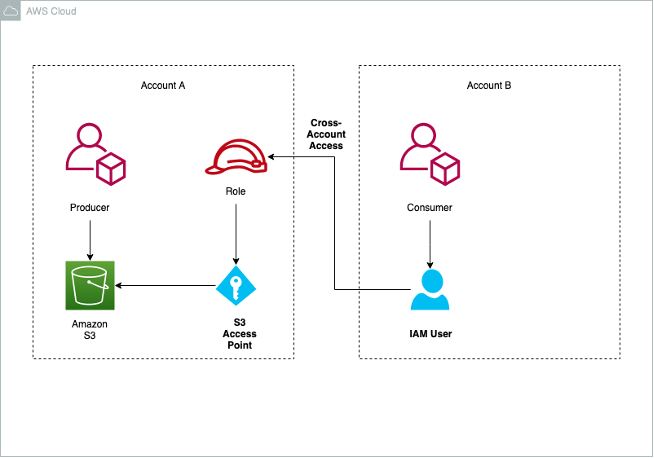
创建者创建 S3 存储桶并启用访问点的使用。作为配置的一部分,创建者为使用者指定使用者、IAM 角色和权限。
在使用者账户中具有 IAM 角色的使用者用户可以通过互联网访问 S3 存储桶,也可以通过 VPC 端点和 AWS PrivateLink,仅限通过 Amazon VPC 进行访问。
总结
每家企业都有一套独特的限制和要求,而建立有效的数据共享解决方案需要满足这些条件。在这篇文章中,我们展示了可供企业使用的各种选项和最佳实践。数据平台所有者和安全团队应携手合作,评测哪种方法最适合您的具体情况。AWS 账户团队也可以提供帮助。
相关资源
有关相关主题的更多信息,请参阅以下内容:
- AWS 上的数据边界
- AWS Data Exchange
- 使用 AWS Lake Formation 在 AWS 账户之间安全共享数据
- 在 Amazon Redshift 中跨集群共享数据
- 使用 S3 接入点设置跨账户 Amazon S3 访问
Original URL: https://thinkwithwp.com/blogs/big-data/patterns-for-enterprise-data-sharing-at-scale/
关于作者
 Venkata Sistla 是 AWS 的云架构师,侧重于数据与分析。他擅长构建数据处理功能,帮助客户消除阻碍他们利用数据获得业务洞察的约束。
Venkata Sistla 是 AWS 的云架构师,侧重于数据与分析。他擅长构建数据处理功能,帮助客户消除阻碍他们利用数据获得业务洞察的约束。
 Santosh Chiplunkar 是 AWS 的首席驻场架构师。他在帮助客户解决数据挑战方面拥有 20 多年的经验。他帮助客户制定数据和分析策略,并为他们提供如何实现策略的指导。
Santosh Chiplunkar 是 AWS 的首席驻场架构师。他在帮助客户解决数据挑战方面拥有 20 多年的经验。他帮助客户制定数据和分析策略,并为他们提供如何实现策略的指导。