亚马逊AWS官方博客
在 Kubernetes 上优化 Spark 性能
Original URL: https://thinkwithwp.com/cn/blogs/containers/optimizing-spark-performance-on-kubernetes/
Apache Spark是一个开源项目,在分析领域可谓大放异彩。目前,各类知名的大数据与机器学习类工作负载(例如流传输、大型数据集的处理与ETL等)都由它一力承担。
Kubernetes则是一套高人气开源容器管理系统,负责为用户提供用于应用程序部署、维护以及扩展的基础解决方案。Amazon EKS是AWS上的一项托管Kubernetes服务,提供高可用性的控制平面,能够运行生产级工作负载。客户可以在EKS上运行各类常见工作负载,例如微服务、批处理以及机器学习等等。
本文主要面向希望在Kubernetes平台之上运行Spark工作负载的工程师与数据科学家群体。
我们为何考虑在Kubernetes上运行Spark
首先,我们来聊聊客户为什么要考虑在Kubernetes上运行Spark。
Kubernetes属于理想的Spark资源管理器原生选项
从Spark 2.3开始,大家就可以使用Kubernetes运行并管理各类Spark资源。在此之前,我们只能选择Hadoop Yarn、Apache Mesos运行Spark,或者将其运行在独立集群当中。但在Kubernetes上运行Spark,能够大大减少实验时间。此外,用户也可以通过多种优化技术降低运营复杂性。
在容器与Kubernetes生态系统中运行Spark拥有诸多优势
在将Spark应用程序打包成容器之后,所有的依赖项将与应用程序本体一道打包为单一实体。容器模式将让我们更轻松地保证Hadoop版本与库版本之间的兼容性。另一个优点在于,我们可以对容器镜像进行版本控制并添加各种标签。以此为基础,如果大家需要尝试使用不同版本的Spark或者其依赖项,完全可以通过Kubernetes轻松实现。
将Kubernetes引入您的技术栈之后,我们可以利用Kubernetes生态系统带来的诸多优势。例如,我们可以使用Kubernetes插件实现监控及日志记录。大部分Spark开发人员会选择将Spark工作负载部署到各类组织中已有的Kubernetes基础设施当中,且无需进行任何额外的维护与升级。集群运营人员可以使用Kubernetes命名空间与资源配额机制,为集群访问活动添加资源限制条件。这样,我们相当于拥有了自己的基础设施,而无需占用其他团队的资源。再有,大家还可以使用Kubernetes节点选择器来保护Spark工作负载所专用的基础设施。最后,Driver Pod负责创建Executor Pod,因此我们可以使用Kubernetes服务账户通过Role或者CLusterRole实现权限控制、定义出细粒度访问控制机制,并配合其他工作负载一起安全运行自己的工作负载。
无论是运行即席Spark工作负载,还是面对涉及实时Spark工作负载的业务需求,多租户Kubernetes基础设施都是一种理想的方案选项,能够极大缩短集群的启动时间。此外,我们最好将Spark与其他以数据为中心、负责管理数据生命周期的应用程序共同运行,而非运行孤立集群。如此一来,我们可以利用同一款编排工具构建起端到端生命周期解决方案,并轻松建立起能够在其他区域重现、甚至在本地环境中运行的技术栈。
虽然优势多多,但Kubernetes编排工具对于Spark的支持功能目前仍处于测试阶段。根据说明文档的提醒,最终用户在使用时需要关注配置、容器镜像以及入口点等元素的变化可能带来的运行状态影响。
TPC-DS基准测试
TPC-DS是一项用于衡量决策支持类解决方案性能水平的基准性能测试方案。它为决策支持系统整理出一项基本定义,包括检查大量数据、为实际业务问题提供答案、需要解决各类操作要求与复杂性(例如即席、报表、迭代OLAP,以及数据挖掘等)的SQL查询系统。而这类系统的一大特征,就是高CPU与I/O负载水平。
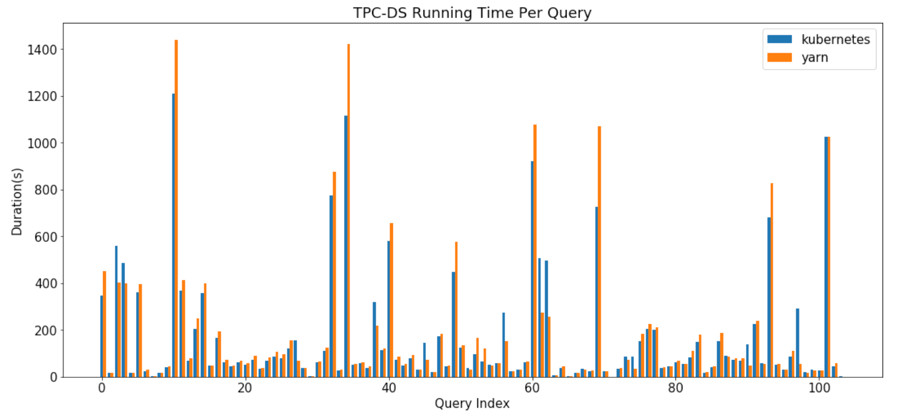
我们在Amazon EKS上运行了TPC-DS基准测试,并将结果与Apache Yarn进行了比较。在本轮基准测试当中,我们选择了SQL 2003标准中使用范围最广的104项查询。其中有99项查询来自TPC-DS基准测试,有4项查询拥有2种变体(14、23、24与39),外加1项“s_max”查询——用于执行对最大表(store_sales)的完整扫描与汇总。
大家可以点击此处查看基准测试结果。
本轮TPC-DS基准测试使用的数据集大小为1 TB,其中Kubernetes的总体运行时间约比Yarn低5%左右。

既然确有性能优势,我们该如何在Kubernetes上运行Spark?
我们可以通过两种方式在Kubernetes上运行Spark:使用Spark-submit,或者使用Spark Operator。通过spark-submit CLI,我们可以使用Kubernetes支持的各种配置选项提交Spark作业。
Spark-submit
Spark-submit是在Kubernetes上运行Spark的最简单方法。查看以上代码片段,大家可能注意到其中需要调整的两个位置。其一是对Kubernetes集群终端节点的更改,我们可以通过EKS控制台(或者AWS CLI)获取。其二是更改托管Spark应用程序所使用的容器镜像。我们可以通过两种方式提交作业:客户端模式与集群模式。二者之间有着细微的差别。如果使用客户端模式,我们可以要求Driver在专用基础设施上运行(与Executor区分开来);而如果选择集群模式,则Driver与Executor都将位于同一个集群当中。大家还可以在命令中指定Spark配置以及Kubernetes特定选项。
Spark Operator
要在Kubernetes上运行Spark,使用Spark Operator是种更好的方法。这是因为Spark Operator能够为Spark工作负载带来原生Kubernetes使用体验。此外,大家还可以选择kubectl与sparkctl批量提交Spark作业。
优化技巧
下面,我们一起来看用于改善Spark工作负载性能的几项优化技巧。对于其中需要调整的特定配置,请大家参考eks-spark-benchmark repo。
Kubernetes集群
Kubernetes属于通用型容器编排平台,因此我们可能需要调整其中某些参数,以保证在系统上实现符合负载需求的性能表现。从广义上讲,这些参数可以分为三类:基础层(EC2实例、网络、存储、文件系统等)、平台层(Kubernetes、附件)以及应用层(Spark、S3A提交程序)。大家可以通过相应技巧评估可行的性能提升选项,同时评估系统的可靠性,并据此针对特定工作负载的资源需求量进行综合比较。
NVMe实例存储
这里,我们建议大家使用AWS Nitro EC2实例来运行Spark工作负载。Nitro EC2实例的最大优势,在于全面引入AWS提供的各类创新成果(例如更快的块存储I/O、更高的安全性、轻量化虚拟机管理程序等等)。EC2 Nitro实例通过两种方式提供块存储功能,纯EBS以及基于NVMe的SSD。例如,r5.24xlarge实例配合纯EBS SSD存储卷可带来可观的EBS传输带宽(19000 Mbps),而r5d.24xlarge则有4个900 GiB NVMe SSD存储卷。我们在TPC-DS基准测试当中选择了基于NVMe的实例存储方案。但我们建议大家对基于NVMe的实例存储方案进行全面评估,这是一种性能更强大的存储解决方案,以物理连接接入主机服务器,并可作为临时存储空间以进一步提升I/O容量上限。我们将在后面的Shuffle性能调整章节中具体讨论如何使用本地NVMe SSD作为Spark的暂存空间。这里再次强调,本地NVMe SSD在默认情况下不会被挂载至实例当中,您需要额外进行配置。如果使用eksctl构建集群,则可以使用我们示例中的集群配置引导EKS工作节点。
单可用区节点组
在大多数情况下,使用多可用区选项运行微服务架构能够显著提高可用性,这也是我们推荐的最佳实践之一。在默认情况下,AWS中的Kubernetes会尝试将工作负载分配至同多个可用区绑定的节点当中。但这种模式会给Spark工作负载带来两个潜在问题。首先,跨可用区延迟通常在个位数毫秒级别,当我们与单一可用区内的节点进行比较时(延迟单位为微秒级别),前者的随机服务性能确实要逊色一筹。另外,Spark shuffle是一项极耗资源的操作,会占用大量磁盘I/O、数据序列化以及网络I/O资源,而在单可用区内选择节点可以提高这方面性能。最后,跨可用区数据传输成本。Amazon EC2实例对于传入数据与传出数据各设定了每GB 0.01美元的服务费率,由于Spark shuffle是高网络I/O操作,因此大家应该认真考虑由此带来的数据传输成本。
当然,大家还需要验证单可用区选项能否满足系统提出的可用性需求。对于在本质上具有瞬态属性的Spark工作负载,单可用区肯定可以满足要求,大家不妨直接选择单可用区Kubernetes节点组。但如果使用的是多租户Kubernetes集群,则可以使用其他高级调度功能(例如节点亲和性)或者查看Volcano调度程序中提供的高级功能,我们将在后文部分具体介绍。
自动伸缩方面的注意事项
Spark架构中包含Driver与Executor Pod,它们将在分布式上下文内协同工作以提供作业处理结果。Driver Pod负责执行多项操作,例如在工作节点上获取Executor、将应用程序代码(通过JAR或Python定义)发送至Executor,以及将任务发送给Executor等。在应用程序执行完毕后,Executor Pod将被终止,而Driver Pod则继续存在并处于“已完成”状态,直到被垃圾回收或者手动操作清理掉为止。大家可以通过Driver Pod访问日志以检查处理结果。因此,最重要的就是防止Driver Pod因集群中的scale-in操作而失效。我们可以在Driver Pod清单中添加以下关于Cluster Autoscaler(CA)的注释以预防这类情况。
"cluster-autoscaler.kubernetes.io/safe-to-evict": "false"
另外,如果大家选择多租户集群并以Spark工作负载利用率为基础对节点进行自动伸缩,则可直接使用Kubernetes Cluster Autoscaler (CA)。一旦现有资源无法满足请求的需要,CA会根据失败的Pod请求推断必要的集群容量。但这项机制会导致Executor Pod的调度延迟随之增加。要解决这个问题,我们不妨以低优先级运行Pause Pod为集群预留冗余资源(详见优先级抢占)。在资源有限的情况下,调度程序会抢占这些Pause Pod以放置Executor Pod。如此 一来,CA扩展可以腾出时间逐步添加更多节点以恢复Pause Pod。
内存管理
要想更好地管理Spark工作负载资源,我们首先需要理解Kubernetes是如何实现内存管理的。除了Kubernetes守护程序之外,各Kubernetes节点中通常也运行有大量OS系统守护程序。这些系统守护程序会占用大量资源,其可用性将直接决定Kubernetes节点的稳定性水平。Kubelet会公开Node Allocatable,供我们为关键守护程序保留一部分系统资源。例如,通过使用kube-reserved,我们可以为kubelet、容器运行时等Kubernetes系统守护程序保留一部分计算资源。而通过使用system-reserved,我们可以为sshd、udev等OS系统守护程序保留计算资源。关于更多详细信息,请参阅为系统守护程序保留计算资源。我们也可以使用Allocatable为各Pod设定保留计算资源。

在默认情况下,Kubernetes会根据Pod定义中指定的请求/限制使用cgroups进行内存分配,这就是设置spark.executor.memory。此外,Kubernetes还会考虑到spark.kubernetes.memoryOverheadFactor * spark.executor.memory或者至少预留384 MiB内存作为额外的非JVM内存缓冲区(涵盖堆外内存分配、非JVM任务以及各类系统进程)。如果要更改这一默认设置,请通过分配spark.executor.memoryOverhead值以覆盖此项操作。
关于堆设置部分,Kubernetes上的Spark会将Xms (最小堆)与 -Xmx (最大堆)同样分配为spark.executor.memory。在这种情况下,Xmx会略低于Pod的内存限制,借此避免Executor由于内存不足(OOM)错误而被意外关闭。
导致OOM错误并引发Pod关闭的主要原因有以下三点:
- 如果您的Spark应用程序使用过多堆内存,则容器OS内核会关闭Java程序,xmx < 实际内存用量 < pod.memory.limit。
- 如果内存用量 > pod.memory.limit,您的主机OS cgroups会关闭该容器。Kubelet会尝试在同一主机或者其他主机上重启这个因OOM被关闭的容器。
- 如果工作节点遭遇内存压力,Kubelet会尝试保护节点并随机关闭Pod以释放内存资源。关闭操作完全随机,不会按照Pod的实际内存消耗量进行选择。
因此,请大家务必注意上述问题以避免发生OOM错误。如果大家不太熟悉这些设置,请参阅Java说明文档以及Spark on Kubernetes配置说明。如果您希望主动监控Spark的内存消耗情况,建议在Prometheus或者其他类似的监控解决方案中通过cadvisor监控内存指标(container_memory_cache and container_memory_rss)。
使用竞价实例
所谓竞价实例,即当前未被实际使用的AWS备用EC2实例。与按需实例相比,竞价实例资源的折扣很大(低至一折)。瞬态及长时间运行的Spark工作负载,特别适合竞价实例的天然特性。由于竞价实例随时可能中断,因此我们需要在Spark工作负载中引入适当的缓解措施以保证其不会受到意外影响。首先,请确保只在按需实例上运行Driver Pod,这是因为一旦此类容器遭遇中断,整个作业就必须从零开始重新启动。因此,我们可以运行两个节点组:按需组与竞价组,使用节点亲和性功能在按需节点组上部署Driver Pod,并在竞价节点组上部署Executor Pod。
Amazon FSx for Lustre
Amazon FSx for Lustre是一套经过优化的高性能文件系统,能够快速处理各类工作负载,包括机器学习、高性能计算(HPC)、视频处理、财务建模以及电子设计自动化(EDA)等等。这类工作负载通常需要快速且可扩展的文件系统接口以获取数据,并将数据集存储在Amazon S3等持久数据存储方案中。大家可以按照Github说明在Kubernetes集群中安装CSI驱动程序。Amazon FSx for Lustre还与Amazon S3深度集成。我们可以定义S3数据的存储分类,并指定其导入与导出路径以通过Kubernetes Pod对这些数据发起访问。在Spark工作负载中,Driver Pod与Executor Pod可以直接与S3交互,这将最大程度降低I/O操作的复杂性。如果我们需要将文件导出至Amazon S3,这里建议在容器内构建lustre客户端。
使用Amazon S3
Amazon S3并不属于文件系统,因为其中的数据以对象的形式被保存在所谓“存储桶”之内。我们可以通过Amazon S3 API或者Amazon S3控制台访问这些数据。另一方面,Hadoop专门面向分布式存储系统所编写,可以作为文件系统使用,且提供文件锁定、重命名以及ACL等重要操作功能。
S3中与Hadoop相关的限制
Hadoop提供的S3A客户端能够将S3存储桶转化为类似于Hadoop兼容文件系统的形式,但S3在本质上仍然属于对象存储服务,而且在作为Hadoop兼容文件系统时存在一定限制。其中的几个关键点包括:
- 目录操作可能很慢,而且非原子性。
- 无法支持所有文件操作,例如rename()重命名。
- 在整体输出流写入完成之前,无法在对象存储中查看这部分数据。
- Amazon S3只能对PUTS与DELETES覆盖操作提供最终一致性,指向新对象的PUTS操作则为写后读取一致性。虽然我们可以跨不同服务器进行对象复制,但对当前副本的变更要经过一段时间才会被传播至其他副本。在此过程中,会存在对象存储不一致的问题。具体而言,对文件的列出、读取、更新或删除操作都将出现不一致状况。为了解决这个问题,我们可以配置S3Guard。要了解更多详细信息,请参阅《S3Guard:面向S3A的一致性与元数据缓存方案》。
- HDFS不支持按文件或按目录分配权限,也不支持更为复杂的ACL机制。
- 工作负载集群与Amazon S3之间的传输带宽是有限的,而且具体带宽需求视网络与虚拟机负载而定。
出于以上原因,Amazon S3虽然是个不错的持久数据源与存储选项,但却无法直接替代HDFS等集群内文件系统,也无法作为fs.defaultFS使用。为了解决这些问题,AWS现在提供名为S3A committers的S3A文件系统客户端,专门负责将作业提交至S3。
S3A committers
提交程序主要分为两种类型,staging与magic。其中Staging提交程序出自Netflix之手,具体又分为目录与分区两种类别。Magic提交程序则由Hadoop社区开发,需要配合S3Guard才能保持数据一致性。
- 目录提交程序:将工作数据缓冲至本地磁盘,使用HDFS将提交信息从任务传播至作业提交程序,同时负责管理目标目录树中的所有冲突。
- 分区提交程序:与目录提交程序基本相同,只是按分区管理各项冲突,从而实现对当前数据集的就地更新。分区提交程序只适用于Spark。
- Magic提交程序:数据会被直接写入至S3,但“神奇”的是,数据会进一步被重新定位至最终目标。此外,提交程序还负责管理目录树中的冲突。为了实现S3对象存储一致性,Magic提交程序需要配合S3Guard共同使用。
例如,如果我们希望为Spark 2.4.5加Hadoop 3.1组合配置目录S3A committers,则可使用以下选项。
要了解如何为特定Spark及Hadoop版本配置S3A committers,请点击此处参阅更多内容。
Shuffle性能
Spark操作中的大部分开销都源自shuffle阶段,因为其中包含大量磁盘I/O、序列化、网络数据传输以及其他操作。Spark Driver与Executor都会使用Pod内的目录来存储临时文件。如何为这些Pod定义存储选项,自然也是一项很有门道的优化技巧。对于具体shuffle配置调优方法,请参阅eks-spark-benchmark repo。
使用EmptyDir作为暂存空间
每当向容器的可写层中写入新数据时,Docker都会使用写时复制(CoW)。在理想情况下,考虑到性能影响,很少有数据会被写入该层。这方面的最佳实践是将写入工作转移至Docker存储驱动程序。Kubernetes提供存储选项抽象,用户可以将emptyDir存储卷呈现给容器。至于EmptyDir的支持资源,我们可以选择附加至主机、网络文件系统或者主机内存的存储卷。
使用tmpfs 支持emptyDir存储卷
如果在emptyDire规范中定义tmpfs,Kubernetes会将内存分配给Pod作为暂存空间。使用内置内存可以大大提升Spark在shuffle阶段的性能表现,从而显著提升作业整体性能。但这也意味着我们的Spark作业将只能使用被分配给主机的内存,即只适用于无盘主机或者存储空间较小的主机。对于spark-operator,我们可以使用以下配置选项在Spark中使用tmpfs。
使用hostPath支持emptyDir存储卷
同样的,我们也可以将emptyDir配置为主机上挂载的存储卷。对于由NVMe SSD实例存储卷支持的EC2实例,这样的配置方式可以带来远超纯EBS存储卷的性能表现。这种方式也特别适合本文中的示例,即将实例存储作为Spark作业暂存空间的情况。此外,TPCDS等需要处理高强度、大量I/O作业的场景也适合这种方法。请注意,实例存储卷(或者tmpfs)中存储的数据仅在不重启/终止节点的情况下才具备可用性。下面来看Spark-operator使用实例存储卷的具体示例。
使用多个磁盘支持emptyDir存储卷
如果您的实例中匹配多个磁盘,则可以在配置中指定各磁盘以提高I/O性能。在本质上,多磁盘配置方法并无太多区别,只需要做出细微调整。
使用Volcano调度程序进行作业调度
在默认情况下,Kubernetes调度程序会按Pod执行调度操作,但这显然并不适合批量工作负载的实际情况。Volcano调度程序可以通过以下功能协助解决这方面问题。
Gang调度
如果集群中没有足够的资源,Spark作业可能陷入停顿,只得等待Kubernetes集群扩展并向集群中添加新的节点。Gang调度是一种同时调度多个Pod的方法,能够保证Kubernetes永远不会只启动应用程序中的某一部分,从而解决由不同作业引发的资源死锁问题。例如,如果某项作业需要使用X个Pod,但目前的资源只能调度X – 2个Pod,则该作业将持续等待、直到资源可以容纳全部X个Pod为止。另外,如果某项作业需要使用Y个Pod,而集群中拥有充足的资源,则该作业将立即执行。Volcano调度程序提供Gang调度功能,大家可以参考GitHub repo中的说明安装Volcano调度程序。
任务拓扑与高级binpack
大家还可以使用任务拓扑与高级binpack策略进一步增强作业调度能力。通过此项策略,我们能够减少实例间的通信与资源碎片带来的网络传输开销。当然,该策略只适用于一部分用例,不可能百试百灵,在单一EC2实例的多个Executor上使用binpack反而会引发网络性能瓶颈。
总结
要保证Spark工作负载的良好运行,我们必须在计算、网络与存储资源的I/O中做出权衡与优化。客户永远希望以最佳性能与最低成本的前提下运行此类工作负载。为了满足需求,Kubernetes提供多种调整选项,而本文涵盖了其中几项值得关注的优化技巧。希望大家能够由此得到启发,灵活运用最佳实践以改善Spark性能。如果大家还有更多意见或者建议,也请在eks-spark-benchmark GitHub repo上创建问题留下您的反馈。