Original URL:https://thinkwithwp.com/blogs/big-data/metadata-classification-lineage-and-discovery-using-apache-atlas-on-amazon-emr/
随着数据在当今世界中的作用不断发展演变,数据治理已然成为有效数据管理的重要环节。许多组织使用数据湖作为单个存储库,存储属于组织中某个业务实体的各种格式的数据。使用元数据、分类和数据沿袭是有效利用数据湖的关键。
这篇文章将指导您了解安装在 Amazon EMR 上的 Apache Atlas 如何提供此功能。您可以使用此设置来动态分类数据并查看数据在各种过程中移动期间的数据沿袭。在此过程中,您可以在 Atlas 中使用领域专用语言 (DSL) 来搜索元数据。
Amazon EMR 和 Apache Atlas 简介
Amazon EMR 是一项托管服务,可简化大数据框架(如 Apache Hadoop 和 Spark)的实施。如果您使用 Amazon EMR,则可以从一组定义好的应用程序中进行选择,或者从列表中选择您自己的应用程序。
Apache Atlas 是用于 Hadoop 的企业级数据治理和元数据的一套框架。Atlas 为组织提供开放的元数据管理和治理功能,用于建立组织的数据资产目录。Atlas 支持数据分类,包括描述了数据演变方式的存储沿袭。它还提供用于搜索关键元素及其业务定义的功能。
在 Apache Atlas 提供的所有功能中,本文最关注的核心功能是 Apache Hive 元数据管理和数据沿袭。成功设置 Atlas 后,它将使用原生工具导入 Hive 表并分析数据,以便直观地向最终用户展示数据沿袭。要了解有关 Atlas 及其功能的更多信息,请访问 Atlas 网站。
AWS Glue 数据目录与Apache Atlas
AWS Glue 数据目录提供了跨各种数据源和数据格式的统一元数据存储库。AWS Glue 数据目录与 Amazon EMR 以及 Amazon RDS、Amazon Redshift、Redshift Spectrum 和 Amazon Athena 集成。该数据目录可与任何兼容 Hive 元存储的应用程序配合使用。
只需要了解 Apache Atlas on Amazon EMR 的安装范围,Amazon EMR 上的 Hive 元存储库即可提供数据沿袭、发现和分类功能。此外,您可以使用此解决方案为没有 AWS Glue 的 AWS 区域进行分类。
架构
Apache Atlas 要求您在使用EMR集群时必备的应用程序组件(例如 Apache Hadoop、HBase、Hue 和 Hive)。Apache Atlas 将使用 Apache Solr 用于搜索,并使用 Apache HBase 用于存储。在 Atlas 安装过程中,Solr 和 HBase 都会安装在Amazon EMR 集群上。
该解决方案的架构支持内部和外部 Hive 表。为了使 Hive 元存储在多个 Amazon EMR 集群之间持久保留,您应该将该元存储包含在外部 Amazon RDS 或 Amazon Aurora 数据库内。Amazon EMR 文档中提供了引用外部 RDS Hive 元存储的 Hive 服务的示例配置文件。
下图展示了我们的解决方案架构。
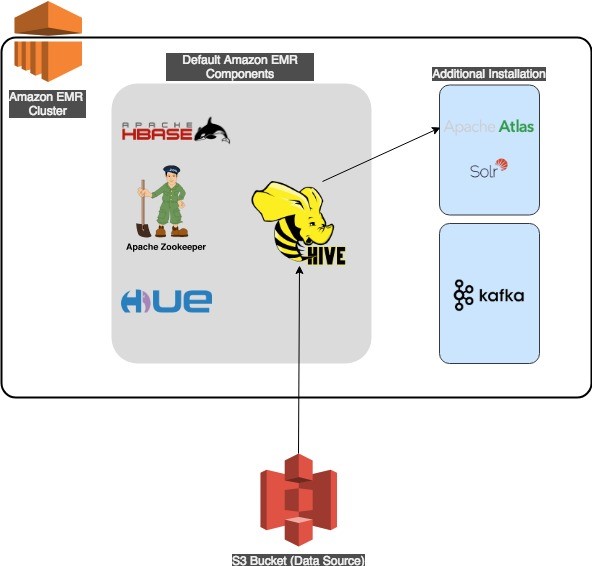
Amazon EMR – Apache Atlas 工作流
为了演示 Apache Atlas 的功能,我们在本文中执行了以下操作(您可以选择1a或者1b任意一种方式来启动带Atlas的EMR集群):
- 使用 AWS CLI 或 AWS CloudFormation 启动一个 Amazon EMR 集群
- 使用 Hue 填充外部 Hive 表
- 查看 Hive 表的数据沿袭
- 创建一个分类
- 使用 Atlas 领域专用语言发现元数据
1a.使用 AWS CLI,启动带有 Apache Atlas 的 Amazon EMR 集群
以下步骤将指导您使用 AWS CLI 安装 Atlas on Amazon EMR。此安装将使用 Hadoop、HBase、Hive 和 Zookeeper 创建一个 Amazon EMR 集群。此外还执行了一个步骤,运行位于 Amazon S3 存储桶中的脚本,以将 Apache Atlas 安装在 /apache/atlas 文件夹下。
运行自动化外壳shell脚本基于如下假设:
- 您已配置了 AWS CLI 程序包的有效本地副本,其中包含访问密钥和加密密钥。
- 您在计划部署集群的 AWS 区域中具有默认密钥对、VPC 和子网。
- 您拥有足够的权限,可以在 AWS CLI 中配置的默认 AWS 区域内创建 S3 存储桶和 Amazon EMR 集群。
aws emr create-cluster --applications Name=Hive Name=HBase Name=Hue Name=Hadoop Name=ZooKeeper \
--tags Name="EMR-Atlas" \
--release-label emr-5.16.0 \
--ec2-attributes SubnetId=<subnet-xxxxx>,KeyName=<Key Name> \
--use-default-roles \
--ebs-root-volume-size 100 \
--instance-groups 'InstanceGroupType=MASTER, InstanceCount=1, InstanceType=m4.xlarge, InstanceGroupType=CORE, InstanceCount=1, InstanceType=m4.xlarge \
--log-uri ‘<S3 location for logging>’ \
--steps Name='Run Remote Script',Jar=command-runner.jar,Args=[bash,-c,'curl https://s3.amazonaws.com/aws-bigdata-blog/artifacts/aws-blog-emr-atlas/apache-atlas-emr.sh -o /tmp/script.sh; chmod +x /tmp/script.sh; /tmp/script.sh']
成功执行命令后,系统将显示包含集群 ID 的输出:
{
"ClusterId": "j-2V3BNEB9XQ54H"
}
使用以下命令列出活动集群的名称(准备就绪后,您的集群将显示在列表中):
aws emr list-clusters --active
在上一条命令的输出中,查找服务器名称 EMR-Atlas(除非您在脚本中更改了该默认名称)。如果您有可用的 jq 命令行实用程序,则可以运行以下命令来过滤除了该名称及其对应集群 ID 之外的所有内容:
aws emr list-clusters --active | jq '.[][] | {(.Name): .Id}'
输出示例:
{
"external hive store on rds-external-store": "j-1MO3L3XSXZ45V"
}
{
"EMR-Atlas": "j-301TZ1GBCLK4K"
}
在集群显示在活动列表中之后,Amazon EMR 和 Atlas 即可开始运行。
1b.使用 AWS CloudFormation,启动带有 Apache Atlas 的 Amazon EMR 集群
您还可以使用 CloudFormation 启动集群。使用 emr-atlas.template 来设置您的 Amazon EMR 集群,或使用以下按钮直接从 AWS 管理控制台启动:

若要启动,请为以下参数提供值:
| VPC |
<VPC> |
| Subnet |
<子网> |
| EMRLogDir |
<Amazon EMR 日志记录目录,例如 s3://xxx> |
| KeyName |
<EC2 密钥对名称> |
使用 CloudFormation 模板预置 Amazon EMR 集群可实现与前面列示的 CLI 命令相同的结果。
在继续下一步之前,请耐心等待,直到 CloudFormation 堆栈的事件中显示堆栈的状态已转为“CREATE_COMPLETE”。
2.使用 Hue 创建 Hive 表
接下来,您登录到 Apache Atlas 和 Hue,并使用 Hue 创建 Hive 表。
要登录到 Atlas,请首先使用 Amazon EMR 管理控制台在集群安装中找到Master服务器的公共 DNS 名称。然后,使用以下命令创建到 Atlas Web 浏览器的SSH隧道。
ssh -L 21000:localhost:21000 -i key.pem hadoop@<EMR Master IP Address>
如果前面的命令不起作用,请确保您的密钥文件 (*.pem) 具有适当的权限。您可能还必须向主服务器的安全组添加一条 SSH(端口 22)的入站规则。
成功创建 SSH 隧道后,请使用以下 URL 访问 Apache Atlas UI。
http://localhost:21000
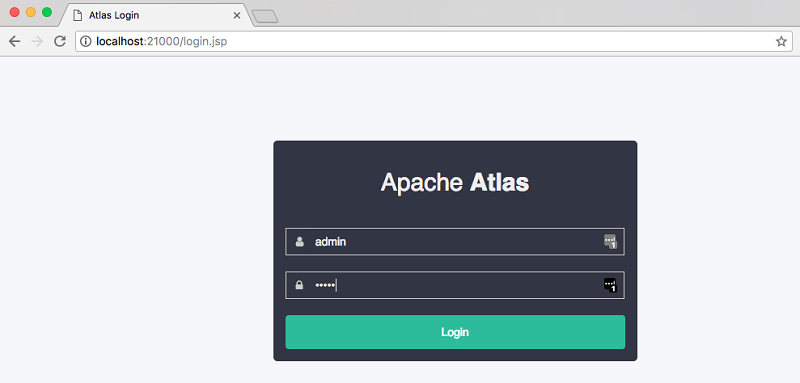
此时您应该看到如下所示的屏幕。默认的登录详细信息是用户名 admin、密码 admin。
要为 Hue 设置 Web 界面,请遵循 Amazon EMR 文档中的步骤。与对 Apache Atlas 执行的操作一样,在远程端口 8888 上创建 SSH 隧道以进行控制台访问:
ssh -L 8888:localhost:8888 -i key.pem hadoop@<EMR Master IP Address>
隧道启动后,使用以下 URL 进行 Hue 控制台访问。
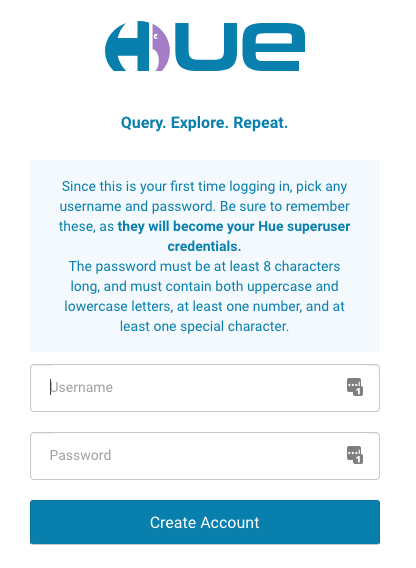
首次登录时,系统会要求您创建一个 Hue 超级用户,如下所示。注意保存好超级用户凭据,切勿遗失。
创建 Hue 超级用户后,您可以使用 Hue 控制台运行 Hive 查询。
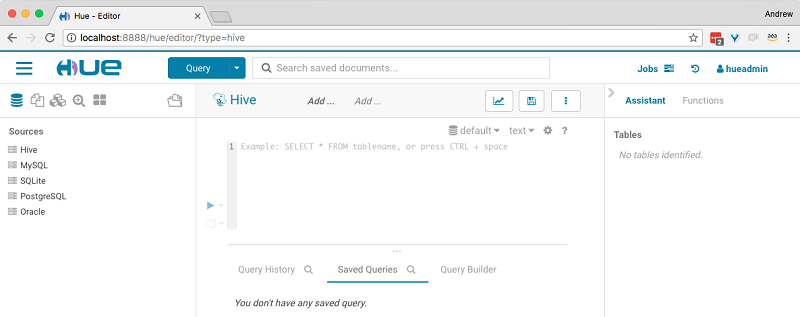
登录到 Hue 后,请执行以下步骤并运行以下 Hive 查询:
-
create database atlas_emr;
use atlas_emr;
-
- 使用存储在 S3 上的数据创建一个名为 trip_details 的新外部表。将 S3 位置更改为您拥有的存储桶地址。
CREATE external TABLE trip_details
(
pickup_date string ,
pickup_time string ,
location_id int ,
trip_time_in_secs int ,
trip_number int ,
dispatching_app string ,
affiliated_app string
)
row format delimited
fields terminated by ',' stored as textfile
LOCATION 's3://aws-bigdata-blog/artifacts/aws-blog-emr-atlas/trip_details/';
-
- 使用存储在 S3 上的数据创建一个名为 trip_zone_lookup 的新查找外部表。
CREATE external TABLE trip_zone_lookup
(
LocationID int ,
Borough string ,
Zone string ,
service_zone string
)
row format delimited
fields terminated by ',' stored as textfile
LOCATION 's3://aws-bigdata-blog/artifacts/aws-blog-emr-atlas/zone_lookup/';
-
- 通过联接以下表创建 trip_details 和 trip_zone_lookup 的交叉表:
create table trip_details_by_zone as select * from trip_details join trip_zone_lookup on LocationID = location_id;
接下来,执行 Hive 导入。在 Atlas 中导入的元数据时,只能通过 Amazon EMR 服务器(没有 Web UI)上的命令行来使用 Atlas Hive 导入工具。 首先,请使用 SSH 登录到 Amazon EMR 主服务器:
ssh -i key.pem hadoop@<EMR Master IP Address>
然后执行以下命令。该脚本要求您输入 Atlas 的用户名和密码。默认用户名是 admin,默认密码是 admin。
/apache/atlas/bin/import-hive.sh
如果导入执行成功,其效果如下所示:
Enter username for atlas :- admin
Enter password for atlas :-
2018-09-06T13:23:33,519 INFO [main] org.apache.atlas.AtlasBaseClient - Client has only one service URL, will use that for all actions: http://localhost:21000
2018-09-06T13:23:33,543 INFO [main] org.apache.hadoop.hive.conf.HiveConf - Found configuration file file:/etc/hive/conf.dist/hive-site.xml
2018-09-06T13:23:34,394 WARN [main] org.apache.hadoop.util.NativeCodeLoader - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2018-09-06T13:23:35,272 INFO [main] hive.metastore - Trying to connect to metastore with URI thrift://ip-172-31-90-79.ec2.internal:9083
2018-09-06T13:23:35,310 INFO [main] hive.metastore - Opened a connection to metastore, current connections: 1
2018-09-06T13:23:35,365 INFO [main] hive.metastore - Connected to metastore.
2018-09-06T13:23:35,591 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Importing Hive metadata
2018-09-06T13:23:35,602 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Found 2 databases
2018-09-06T13:23:35,713 INFO [main] org.apache.atlas.AtlasBaseClient - method=GET path=api/atlas/v2/entity/uniqueAttribute/type/ contentType=application/json; charset=UTF-8 accept=application/json status=200
2018-09-06T13:23:35,987 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Database atlas_emr is already registered - id=cc311c0e-df88-40dc-ac12-6a1ce139ca88.Updating it.
2018-09-06T13:23:36,130 INFO [main] org.apache.atlas.AtlasBaseClient - method=POST path=api/atlas/v2/entity/ contentType=application/json; charset=UTF-8 accept=application/json status=200
2018-09-06T13:23:36,144 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Updated hive_db entity: name=atlas_emr@primary, guid=cc311c0e-df88-40dc-ac12-6a1ce139ca88
2018-09-06T13:23:36,164 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Found 3 tables to import in database atlas_emr
2018-09-06T13:23:36,287 INFO [main] org.apache.atlas.AtlasBaseClient - method=GET path=api/atlas/v2/entity/uniqueAttribute/type/ contentType=application/json; charset=UTF-8 accept=application/json status=200
2018-09-06T13:23:36,294 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Table atlas_emr.trip_details is already registered with id c2935940-5725-4bb3-9adb-d153e2e8b911.Updating entity.
2018-09-06T13:23:36,688 INFO [main] org.apache.atlas.AtlasBaseClient - method=POST path=api/atlas/v2/entity/ contentType=application/json; charset=UTF-8 accept=application/json status=200
2018-09-06T13:23:36,689 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Updated hive_table entity: name=atlas_emr.trip_details@primary, guid=c2935940-5725-4bb3-9adb-d153e2e8b911
2018-09-06T13:23:36,702 INFO [main] org.apache.atlas.AtlasBaseClient - method=GET path=api/atlas/v2/entity/uniqueAttribute/type/ contentType=application/json; charset=UTF-8 accept=application/json status=200
2018-09-06T13:23:36,703 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Process atlas_emr.trip_details@primary:1536239968000 is already registered
2018-09-06T13:23:36,791 INFO [main] org.apache.atlas.AtlasBaseClient - method=GET path=api/atlas/v2/entity/uniqueAttribute/type/ contentType=application/json; charset=UTF-8 accept=application/json status=200
2018-09-06T13:23:36,802 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Table atlas_emr.trip_details_by_zone is already registered with id c0ff33ae-ca82-4048-9671-c0b6597e1475.Updating entity.
2018-09-06T13:23:36,988 INFO [main] org.apache.atlas.AtlasBaseClient - method=POST path=api/atlas/v2/entity/ contentType=application/json; charset=UTF-8 accept=application/json status=200
2018-09-06T13:23:36,989 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Updated hive_table entity: name=atlas_emr.trip_details_by_zone@primary, guid=c0ff33ae-ca82-4048-9671-c0b6597e1475
2018-09-06T13:23:37,035 INFO [main] org.apache.atlas.AtlasBaseClient - method=GET path=api/atlas/v2/entity/uniqueAttribute/type/ contentType=application/json; charset=UTF-8 accept=application/json status=200
2018-09-06T13:23:37,038 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Table atlas_emr.trip_zone_lookup is already registered with id 834d102a-6f92-4fc9-a498-4adb4a3e7897.Updating entity.
2018-09-06T13:23:37,213 INFO [main] org.apache.atlas.AtlasBaseClient - method=POST path=api/atlas/v2/entity/ contentType=application/json; charset=UTF-8 accept=application/json status=200
2018-09-06T13:23:37,214 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Updated hive_table entity: name=atlas_emr.trip_zone_lookup@primary, guid=834d102a-6f92-4fc9-a498-4adb4a3e7897
2018-09-06T13:23:37,228 INFO [main] org.apache.atlas.AtlasBaseClient - method=GET path=api/atlas/v2/entity/uniqueAttribute/type/ contentType=application/json; charset=UTF-8 accept=application/json status=200
2018-09-06T13:23:37,228 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Process atlas_emr.trip_zone_lookup@primary:1536239987000 is already registered
2018-09-06T13:23:37,229 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Successfully imported 3 tables from database atlas_emr
2018-09-06T13:23:37,243 INFO [main] org.apache.atlas.AtlasBaseClient - method=GET path=api/atlas/v2/entity/uniqueAttribute/type/ contentType=application/json; charset=UTF-8 accept=application/json status=404
2018-09-06T13:23:37,353 INFO [main] org.apache.atlas.AtlasBaseClient - method=POST path=api/atlas/v2/entity/ contentType=application/json; charset=UTF-8 accept=application/json status=200
2018-09-06T13:23:37,361 INFO [main] org.apache.atlas.AtlasBaseClient - method=GET path=api/atlas/v2/entity/guid/ contentType=application/json; charset=UTF-8 accept=application/json status=200
2018-09-06T13:23:37,362 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - Created hive_db entity: name=default@primary, guid=798fab06-ad75-4324-b7cd-e4d02b6525e8
2018-09-06T13:23:37,365 INFO [main] org.apache.atlas.hive.bridge.HiveMetaStoreBridge - No tables to import in database default
Hive Meta Data imported successfully!!!
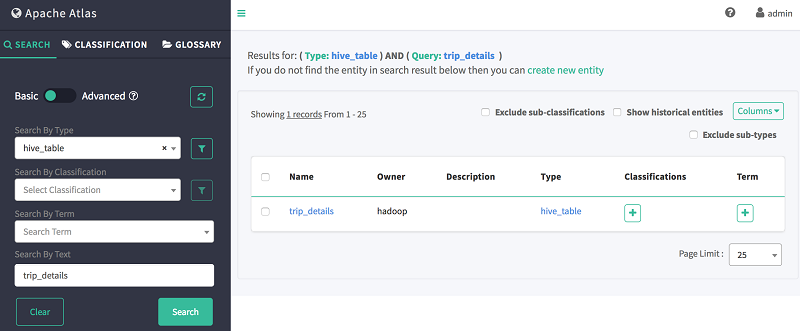
成功导入 Hive 之后,您可以返回到 Atlas Web UI 来搜索 Hive 数据库或已导入的表。在 Atlas UI 的左窗格中,选择搜索,然后在其下方列出的两个字段中输入以下信息:
-
-
- 按类型搜索:hive_table
- 按文本搜索:trip_details
查询的输出如下所示:
3.使用 Atlas 查看 Hive 表的数据沿袭
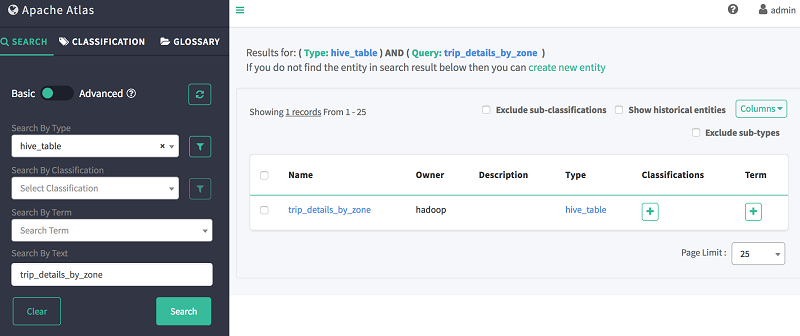
要查看所创建的表的数据沿袭,可以使用 Atlas Web 搜索。例如,要查看先前创建的交叉表 trip_details_by_zone 的数据沿袭,请输入以下信息:
-
-
- 按类型搜索:hive_table
- 按文本搜索:trip_details_by_zone
前文所述查询的输出应如下所示:
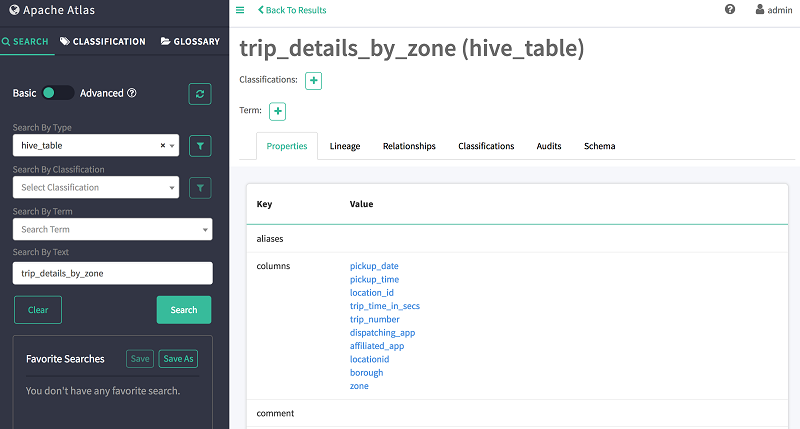
现在,选择表名称 trip_details_by_zone 来查看该表的详细信息,如下所示。
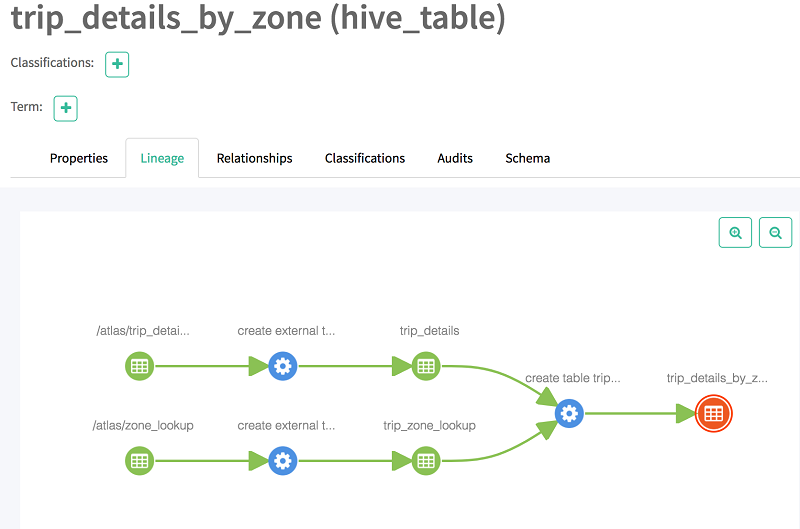
现在,当您选择沿袭时,您应该会看到该表的沿袭。如下所示,沿袭提供有关其基表的信息,并且显示两个表的交叉表。
4.为元数据管理创建分类
Atlas 可以帮助您对元数据进行分类,以满足组织特定的数据治理要求。接下来,我们创建一个示例分类。
要创建分类,请执行以下步骤
-
-
- 从左侧窗格中选择“分类”,然后选择“+”
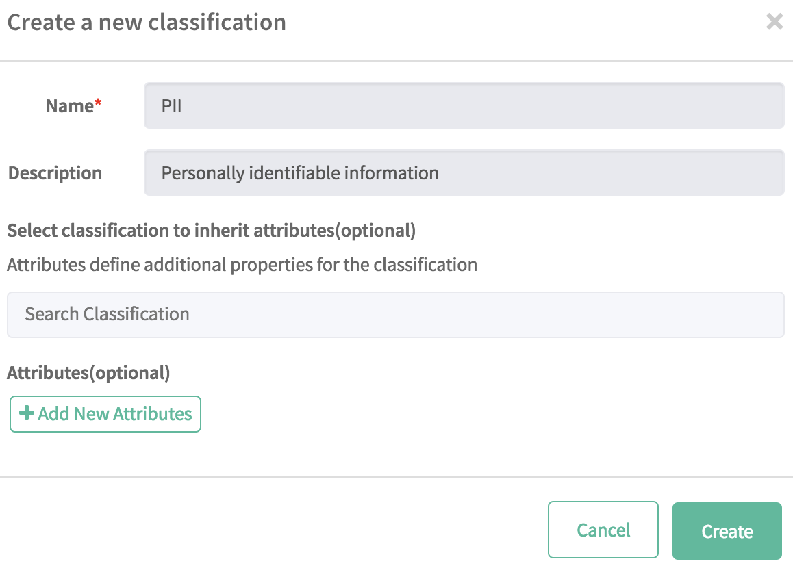
- 在名称字段中键入 PII,在描述中键入个人身份信息
- 选择创建。
接下来,将该表分类为 PII:
-
-
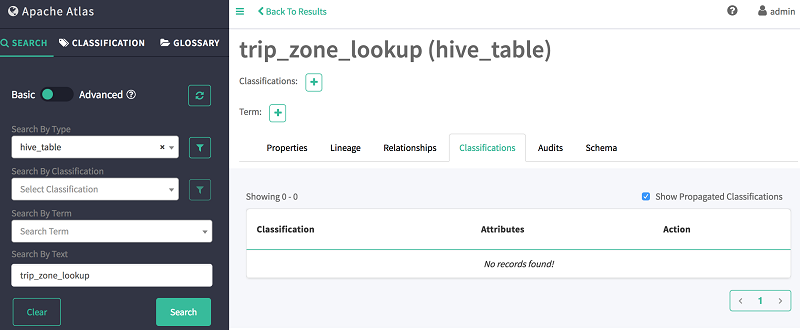
- 返回到左侧窗格中的搜索选项卡。
- 在按文本搜索字段中,键入:trip_zone_lookup
-
-
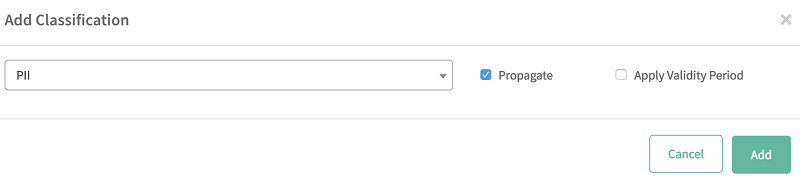
- 选择选项卡,然后选择加号图标 (+)。
- 从列表中选择您创建好的分类 (PII)。
-
-
- 选择添加。
您可以用类似的方式对列和数据库进行分类。
接下来,查看属于该分类的所有实体。
-
-
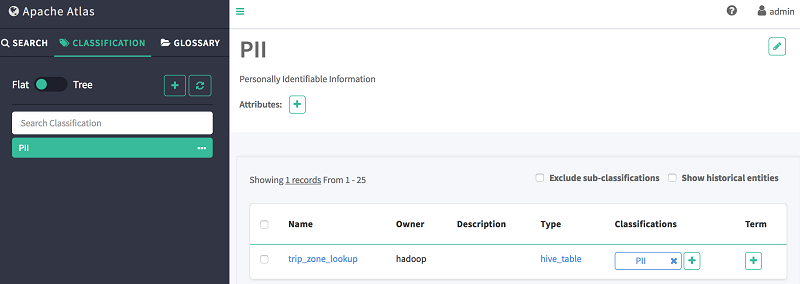
- 选择分类选项卡。
- 选择您先前创建的 PII 分类。
- 查看显示在主窗格上的属于该分类的所有实体。
5.使用 Atlas 领域专用语言 (DSL) 发现元数据
接下来,您可以使用 Atlas 的领域专用语言(DSL,一种类似于 SQL 的查询语言)在 Atlas 中搜索实体。该语言构造简单,可帮助用户浏览 Atlas 数据存储库。其语法模拟了关系数据库领域中广为流行的 SQL。
要使用 DSL 搜索表,请执行以下操作:
-
-
- 选择搜索。
- 选择高级搜索。
- 在按类型搜索中,选择 hive_table。
- 在按查询搜索中,使用如下 DSL 代码段搜索 trip_details:
from hive_table where name = trip_details
如下所示,Atlas 会显示表格的 Schema、数据沿袭和分类信息。
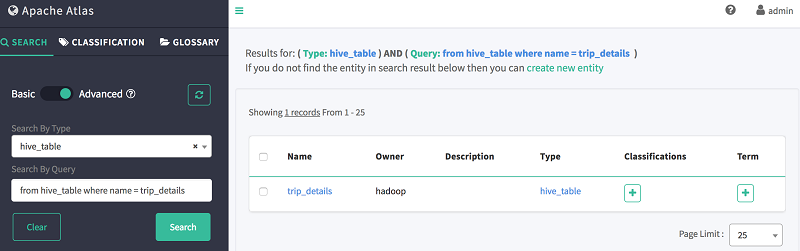
接下来,使用 DSL 搜索一列:
-
-
- 选择搜索。
- 选择高级搜索。
- 在按类型搜索中,选择 hive_column。
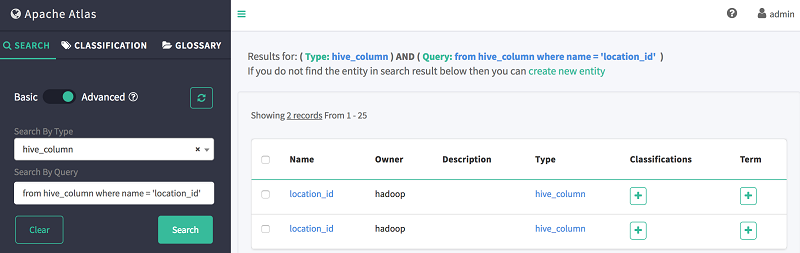
- 在按查询搜索中,使用如下 DSL 代码段搜索 column location_id:
from hive_column where name = 'location_id'
如下所示,Atlas 会显示先前创建的两个表中都存在 location_id 列:
您还可以使用 DSL 对表进行计数:
-
-
- 选择搜索。
- 选择高级搜索。
- 在按类型搜索中,选择 hive_table。
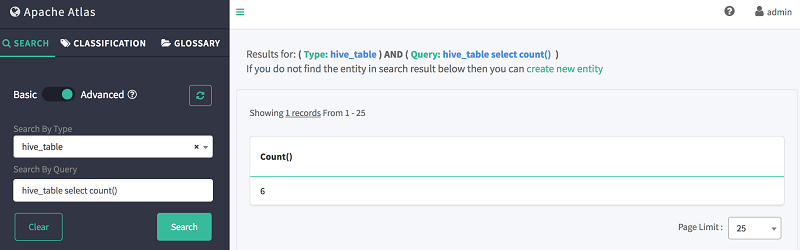
- 在按查询搜索中,使用如下 DSL 命令搜索表存储:
hive_table select count()
如下所示,Atlas 会显示表的总数。
最后一步是清理环境。为了避免产生不必要的费用,请在完成实验后删除 Amazon EMR 集群。
如果使用的是 CloudFormation,最简单的方法是删除先前创建的 CloudFormation 堆栈。默认情况下,集群在创建时会启用终止保护机制。要删除集群,您首先需要关闭终止保护,这可以通过 Amazon EMR 控制台来完成。
小结
在这篇博文中,我们概述了使用 AWS CLI 或 CloudFormation,安装和配置带有 Apache Atlas 的 Amazon EMR 集群所需的步骤。我们还探讨了如何将数据导入 Atlas,以及如何使用 Atlas 控制台执行查询、查看数据构件的沿袭。
有关 Amazon EMR 或 AWS 上任何其他大数据主题的更多信息,请参阅 AWS 大数据博客上的 EMR 博文。
关于作者
 Nikita Jaggi 是 AWS 的一位高级大数据顾问。
Nikita Jaggi 是 AWS 的一位高级大数据顾问。
 Andrew Park 是 AWS 的一位云基础设施架构师。在工作中,除了专注于客户互动之外,他还经常直接与客户合作,构建和交付定制 AWS 解决方案。 Andrew 是一位资深的 Linux 解决方案工程师,喜欢探究 Linux 相关挑战。他是一位开源技术倡导者,热爱棒球,最近在 AWS 本地实践活动中取得了“快乐露营者”奖,他总是热心助人。
Andrew Park 是 AWS 的一位云基础设施架构师。在工作中,除了专注于客户互动之外,他还经常直接与客户合作,构建和交付定制 AWS 解决方案。 Andrew 是一位资深的 Linux 解决方案工程师,喜欢探究 Linux 相关挑战。他是一位开源技术倡导者,热爱棒球,最近在 AWS 本地实践活动中取得了“快乐露营者”奖,他总是热心助人。