亚马逊AWS官方博客
利用 Amazon CloudWatch 指标做出更好的 Amazon RDS 决策
Original URL: https://thinkwithwp.com/blogs/database/making-better-decisions-about-amazon-rds-with-amazon-cloudwatch-metrics/
如果您正在使用 Amazon Relational Database Service (RDS),您可能想知道如何确定修改实例配置的最佳时间。这可能包括确定实例类、存储大小或存储类型等配置。Amazon RDS 支持多种数据库引擎,包括 MySQL、PostgreSQL、SQL Server、Oracle 和 Amazon Aurora。Amazon CloudWatch 可监控所有这些引擎。这些 CloudWatch 指标不但能够指导您选择最佳的实例类,还可以帮助您选择适当的存储大小和类型。本文将讨论如何利用 CloudWatch 指标确定 Amazon RDS 修改,以实现最佳的数据库性能。
CPU 和内存消耗
在 Amazon RDS 中,您可以利用 CloudWatch 指标 CPUUtilization、CPUCreditUsage 和 CPUCreditBalance 来监控 CPU。所有 Amazon RDS 实例类型都支持 CPUUtilization。CPUCreditUsage 和 CPUCreditBalance 只适用于突发通用性能实例。
CPUCreditUsage 被定义为实例为使用 CPU 而消耗的 CPU 积分数量。CPU 积分管理着突发至突发性能实例基线性能以上的性能的能力。一个 CPU 积分能够让一个完整 CPU 核心以 100% 的利用率运行一分钟。CPUUtilization 显示了实例的 CPU 利用率百分比。随机 CPU 消耗峰值并不会影响数据库的性能,但持续的 CPU 高利用率会阻碍正在到来的数据库请求。根据整体数据库工作负载,您的 Amazon RDS 实例的高 CPU 利用率 (70%–90%) 会导致整体性能下降。如果遇到糟糕或意外的查询或者异常高的工作负载,会导致非常高的 CPUUtilization 值,因此您可能升级为更大的实例类。Amazon RDS 性能详情有助于检测会消耗大量 CPU 资源的糟糕 SQL 查询。有关更多信息,请参阅 YouTube 上的“利用性能详情分析 Amazon Aurora PostgreSQL 的性能”。
如下 CloudWatch 图形显示了 CPU 高利用率模式。CPU 长时间保持高利用率状态。此锯齿模式充分表明,您应将 Amazon RDS 实例升级为更高的实例类。

内存是另一个用于确定 Amazon RDS 性能的重要指标,有助于做出有关 Amazon RDS 配置的决策。Amazon RDS 支持以下内存相关指标:
- FreeableMemory – 系统未使用的物理内存的数量以及可用的缓存或页面缓存的总量。如果配置了最佳的数据库工作负载,而且一个或多个糟糕的查询并未导致 FreeableMemory 减少,则低 FreeableMemory 模式表明您应将 Amazon RDS 实例扩展为更大的内存分配量。当根据 FreeableMemory 做出决策时,一定要查看增强监控指标,尤其是可用和已缓存。有关更多信息,请参阅增强监控。
- SwapUsage – 数据库实例上使用的交换空间的大小。在 Linux 托管的数据库中,较高的 SwapUsage 值通常意味着实例的内存效率低下。
磁盘空间消耗
Amazon RDS Oracle、MySQL、MariaDB 和 PostgreSQL 引擎都支持 64 TiB 的存储空间。Amazon Aurora 存储空间以 10 GB 为增量自动增大,最高达 64 TB。Amazon RDS 引擎还支持存储自动扩展。此选项以 5 GiB 或 10% 的当前已分配存储空间(以较大者为准)为增量自动增大存储空间。CloudWatch 指标 FreeStorageSpace 用于衡量实例的可用存储空间的大小。如果数据量增大,您会在 FreeStorageSpace 图形上看到存储空间减小。当 FreeStorageSpace 约为 10%–15% 时,将是扩展存储的一个好机会。存储消耗量突增意味着您应查看数据库工作负载。频繁写入活动、详细日志记录或大量事务日志都是导致可用空间减小的重要因素。
下图显示了 Amazon RDS PostgreSQL 实例的 FreeStorageSpace 指标。此图表明,可用存储空间在 20 分钟内减小了大约 90%。
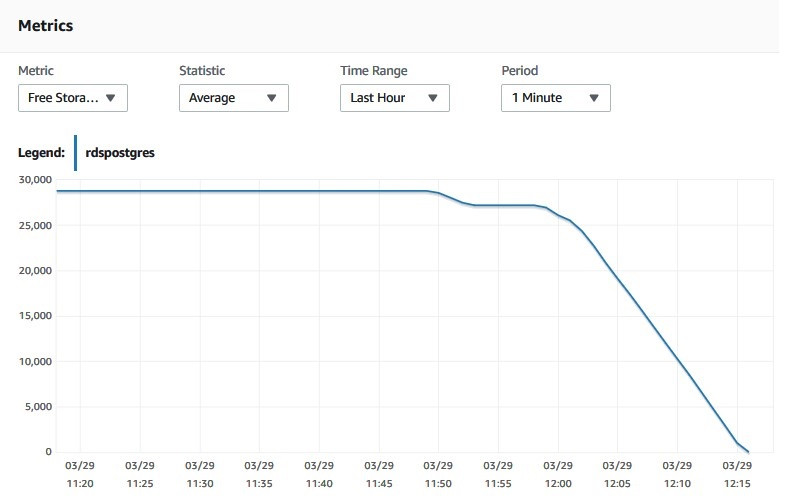
当解决此问题时,将参数 log_min_duration_statement 设置为 0。这意味着正在记录每个 SQL 语句并填写事务日志文件。这些故障排除步骤以及 CloudWatch 图形可以帮助您决定何时调整数据库引擎或扩展实例存储。
数据库连接
DatabaseConnections 指标用于确定正在使用的数据库连接的数量。为了实现最佳的工作负载,当前连接的数量不应超过您最大连接数量的 80% 左右。max_connections 参数用于确定 Amazon RDS 中允许的连接最大数量。您可以在参数组中修改此值。有关更多信息,请参阅使用数据库参数组。
此参数的默认值取决于实例的总 RAM。例如,对于 Amazon RDS MySQL 实例,此默认值由公式 {DBInstanceClassMemory/12582880} 得出。
如果数据库连接数量保持在 max_connections 的 80% 左右,您应升级为具有更大 RAM 的 Amazon RDS 实例类。这样可确保 Amazon RDS 具有更多的数据库连接。例如,如果一个 Amazon RDS PostgreSQL 实例托管在 db.t2.small 实例上,则公式 LEAST({DBInstanceClassMemory/9531392},5000) 会默认将 max_connections 设置为 198。
您可以利用 Amazon RDS 控制台和 AWS 命令行界面 (CLI),或通过连接到此实例来找到此实例的值。请参见如下代码:
postgres=> SHOW max_connections;
max_connections
—————–
198
如下 CloudWatch 图形表明,在 12:40 到 12:48 这段时间,数据库连接数量多次超过 max_connections 值。

当数据库连接数量超过 max_connections 时,您会收到如下错误消息:
严重:将保留剩余的连接槽,以供非复制超级用户连接使用
在这种情况下,您应确定数据库连接数量过多的原因。如果工作负载中未出现任何错误,您应考虑扩展到具有更多内存的 Amazon RDS 实例类。
每秒 I/O 操作数量 (IOPS) 指标
存储类型和大小管理着 Amazon RDS SQL Server、Oracle、MySQL、MariaDB 和 PostgreSQL 实例中的 IOPS 分配。对于通用 SSD 存储,基线 IOPS 是存储空间的三倍(以 GiB 为单位)。为了实现最佳的实例性能,ReadIOPS 与 WriteIOPS 之和应小于所分配的 IOPS。
在突发容量之外,增加 IOPS 的使用量可能会导致性能下降,体现为 ReadLatency、WriteLatency 和 DiskQueueDepth 增大。如果总计 IOPS 工作负载保持在基线 IOPS 的 80%–90%,应考虑修改实例并选择更大的 IOPS 容量。您可以通过几种不同的方法实现此目的:增大通用 SSD 存储、将存储类型更改为预置 IOPS 或者使用 Aurora。
增大通用 SSD 存储
您可以增大通用 SSD 存储,以使实例获得三倍的存储空间(以 GiB 为单位)。尽管您可以创建具有最多 64 TiB 存储空间的 MySQL、MariaDB、Oracle 和 PostgreSQL Amazon RDS DB 实例,但可以实现的最高基线性能为 16000 IOPS。这意味着对于 5.34 TiB 到 64 TiB 的存储卷,实例的最高基线性能都是 16000 IOPS。如果发现 ReadIOPS 在 IOPS 总消耗量中占据了很大的比例,您应升级为具有更大 RAM 的更高实例类。如果数据库工作集几乎都位于内存中,ReadIOPS 应当不会太大并且能够保持稳定。
在如下示例中,为一个 Amazon RDS PostgreSQL 实例配置了 100 GiB 的 GP2 存储空间。此存储空间提供了 300 IOPS 容量,并具有长时间突发能力。如以下图形所示,在 3 月 27 日 12:48,WriteIOPS 为 480,ReadIOPS 为 240。这两个参数之和 (720) 远远超过了基线容量 300。这样就导致 WriteLatecny 和 DiskQueueDepth 升高。
如下图形表明,WriteIOPS 在 12:48 的值为 480。

如下图形表明,ReadIOPS 在 12:48 的值为 240。

如下图形表明,WriteLatency 在 12:48 高达 78 ms。

如下图形表明,DiskQueueDepth 在 12:48 高达 38。

预置 IOPS
如果实例需要 16000 以上的基线 IOPS 或者低 I/O 延迟和稳定的 I/O 吞吐量,请考虑将您的存储类型更改为预置 IOPS。对于 MariaDB、MySQL、Oracle 和 PostgreSQL,您可以选择介于 1000 到 80000 之间的 PIOPS。
Amazon Aurora
如果未将数据库 IOPS 性能限制在某一个数值,请考虑使用 Amazon Aurora。可以利用存储卷的大小或类型来管理限制。Aurora 没有同一类型的 IOPS 限制;您不必管理、预置或扩展 IOPS 容量。实例大小主要决定 Aurora 工作负载的事务和计算性能。IOPS 的最大数量取决于 Aurora 实例的读/写吞吐量限制。您不会受到 IOPS 的限制,但会受到实例吞吐量的限制。有关更多信息,请参阅选择数据库实例类。
Aurora 是一个与 MySQL 和 PostgreSQL 兼容的关系数据库解决方案,具有一个分布式、可容错并能够自我修复的存储系统。Aurora 存储空间会自动扩展至最多 64 TiB。在一个区域中,Aurora 可提供最多 15 个只读副本,而 Amazon RDS 引擎只能提供最多五个副本。
吞吐量限制
Amazon RDS 实例具有两种吞吐量限制:实例级限制和 EBS 卷级限制。
您可以利用指标 WriteThroughput 和 ReadThroughput 来监控实例级吞吐量。WriteThroughput 是指每秒钟写入到磁盘中的平均字节数量。ReadThroughput 是指每秒钟从磁盘中读取的平均字节数量。例如,db.m4.16xlarge 实例类支持 1250 MB/s 的最大吞吐量。对于基于 16 KiB I/O 大小的 GP2 存储,EBS 卷的吞吐量限制为 250 MiB/S,对于预置 IOPS 存储类型,吞吐量限制为 1000 MiB/s。如果由于吞吐量瓶颈问题导致性能下降,您应验证这两种限制,并根据需要修改实例。
Amazon RDS 性能详情
性能详情用于监视您数据库实例的工作负载,以使您能够监控数据库的性能并解决数据库的性能问题。利用数据库负载和等待事件数据,您可以全面了解实例的状态。您可以利用这些数据来修改实例或工作负载,以提高数据库的整体性能。
如下 CloudWatch 图形表明 Aurora PostgreSQL 实例中出现高 CommitLatency。CommitLatency 在 15:33 为 68 ms。

如下图形表明在 15:33 到 15:45 这段时间出现高 IO:XactSync。

在性能详情中,您会发现当 CommitLatency 升高时,等待事件 IO:XactSync 也会升高。此等待事件与 CommitLatency 相关联,是指等待将事务提交为持久性事务时花费的时间。当会话正在等待写入到稳定的存储空间时,就会出现这种情况。此等待通常发生在系统中出现大量提交活动时。在此延迟期间,Aurora 会等待 Aurora 存储空间确认持久性。在这种情况下,存储持久性可能会与需要消耗大量 CPU 资源的数据库工作负载争夺 CPU 资源。为了缓解这种情况,您可以减少那些工作负载,或者扩展至具有更多 vCPU 的数据库实例。
总结
本文讨论了与 Amazon RDS 和性能详情相关的 CloudWatch 指标以及如何利用这些指标做出您的数据库决策。这些指标可以帮助您决定计算和存储扩展、数据库引擎性能调整和工作负载修改。
本文还回顾了 Amazon RDS 提供的各种存储类以及 Amazon Aurora 的工作方式与使用 EBS 卷的 Amazon RDS 实例的工作方式有哪些不同。这些知识可以帮助您排除故障、评估和决定 Amazon RDS 修改。
有关更多信息,请参阅如何利用 CloudWatch 指标决定为您的 RDS 数据库使用通用 IOPS 还是预置 IOPS 以及使用 Amazon RDS 性能详情。