亚马逊AWS官方博客
用于预测COVID-19传播路径的COVID-19模拟器与机器学习工具包
Original URL: https://thinkwithwp.com/cn/blogs/machine-learning/introducing-the-covid-19-simulator-and-machine-learning-toolkit-for-predicting-covid-19-spread/
用于预测COVID-19传播路径的COVID-19模拟器与机器学习工具包
如今,医疗领域已经在COVID-19的诊断与传染机理方面取得突破,包括接触者多长时间会出现症状、以及接触之后平均会有多少人出现症状等等。研究行业也在积极进行努力,希望更准确地预测感染者暴露、康复或天生具有免疫力的人口百分比。研究人员目前使用各部门及机构发布的可用数据,同时参考流感、SARS、MERS等类似疾病的历史数据,借此建立流行病学模型与模拟器方案。但对于任何模型来说,准确捕捉现实世界中的复杂性因素都是一项艰巨的任务。模型构建中的最大挑战之一无疑在于寻找正确参数,这些参数会影响不同国家或人群中疾病的传播趋势,并需要配合各种干预策略(例如停课及社交隔离等)及疫情动向设计假设场景。
现在,我们开始为研究人员及数据科学家开放工具包,希望帮助大家更好地建模并了解特定时段之内COVID-19在不同社群中的变化情况。这套工具集包括疾病传播模拟器以及多套机器学习(ML)模型,可用于测试各种干预措施的影响。首先,ML模型会评估疾病传播并将结果与历史数据进行比较,借此引导系统调整。接下来,您可以使用学习到的参数运行该模拟器,借此建立起采用不同干预措施时的假设场景。下图所示,为工具集当中各可扩展构建模块之间的交互方式。
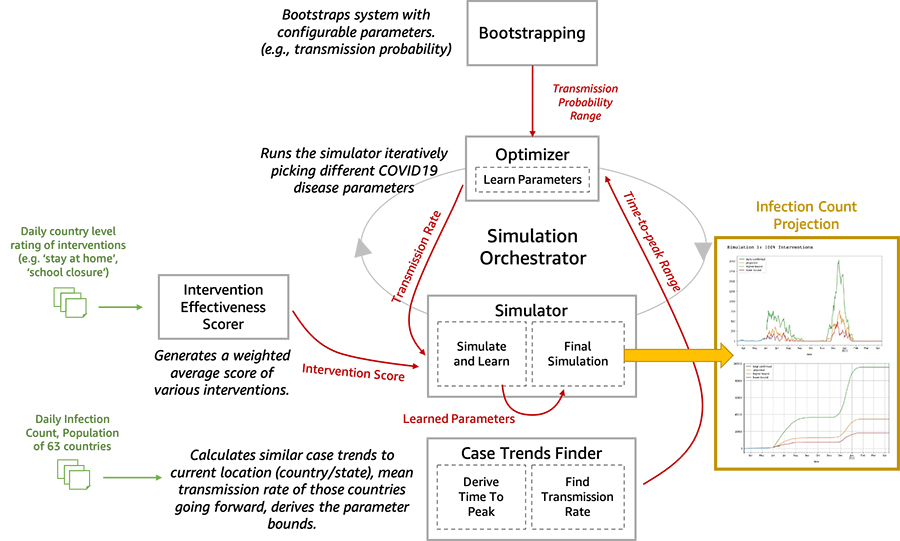
在本文中,我们将详细描述疾病传播模拟的工作原理,如何通过监督学习以寻找模拟参数,并根据干预措施评分对疾病的传播率做出预测。
传染病的历史趋势
我们在开源工具集中提供多套notebooks,可在美国、印度以及欧洲各国的国家级辖区上运行假设场景。在这些notebooks中,我们使用多种数据源囊括新发布病例的具体情况。例如,我们在美国notebook中使用由卡耐基梅隆大学发布的Delphi Epidata API访问各类数据集,其中包括但不限于约翰霍普金斯大学系统科学与工程中心(JHU-CSSE)、谷歌搜索调查趋势、Facebook帖子以及2009年至2010年期间H1N1疫情的历史数据。
我们还使用自有notebook covid19_data_exploration.ipynb将以往疫情流行历史数据与COVID-19进行叠加。以下图为例,其中将COVID-19疫情与季节性流感以及十年前加利福尼亚州、得克萨斯州以及伊利诺伊州的H1N1进行了比较。
第一图为季节性流感、H1N1以及COVID-19在加利福尼亚州内7天周期内的平均发病率。

尽管美国大多数州的COVID-19病例于夏季达到顶峰,但也存在一些例外。在伊利诺伊州,大多数病例出现在年初,类似于H1N1期间的春季发病高峰。

另一方面,在得克萨斯州等其他州,我们还观察到与H1N1秋季对应的潜在峰值。

各州及各国家之间的趋势存在巨大差异,因此我们也提供notebooks以供您从现有数据当中学习,并使用预期峰值预测未来可能出现的假设场景。
运行假设场景生成结果
我们使用的 covid19_data_exploration.ipynb notebook包含涵盖全球各地区及国家的完整假设分析场景列表。在本节中,我们将讨论法国、意大利、美国以及印度马哈拉施特拉邦的假设场景。首先,我们使用ML预测疾病趋势,包括根据用户指定的参数预测波峰与波谷(例如,我们使用3个月周期的COVID-19病例数据为起点,并与H1N1趋势进行比较,借此推断6个月之后可能出现的第二波或第三波疫情爆发)。接下来,我们还将介绍轻度干预与重度干预等管控措施,讨论与之对应的防疫结果。
法国
在法国方面,我们考虑在假设场景中采取更为严格的干预措施,第二波爆发发生在第一波的6个月之后且更为严重(参考H1N1的变化趋势)。下图所示,为每日病例数及累积病例数。在这种情况下,我们的假设场景(橙线)与实际曲线(蓝线)紧密匹配。

意大利
在意大利方面,我们引入了较为温和的干预政策及严格干预政策的两种情况,且同样是在6个月之后出现第二波爆发(参考H1N1的变化趋势)。第一组图表所示,为采用轻度干预政策的每日病例数量与总病例数。
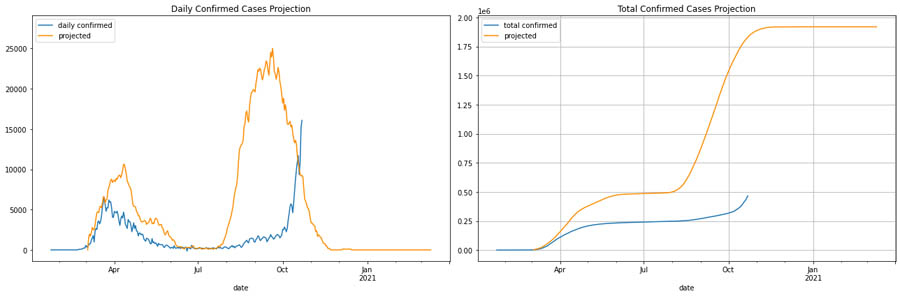
下图则为温和政策下每日及累积病例数量与严格干预政策之间的比较。
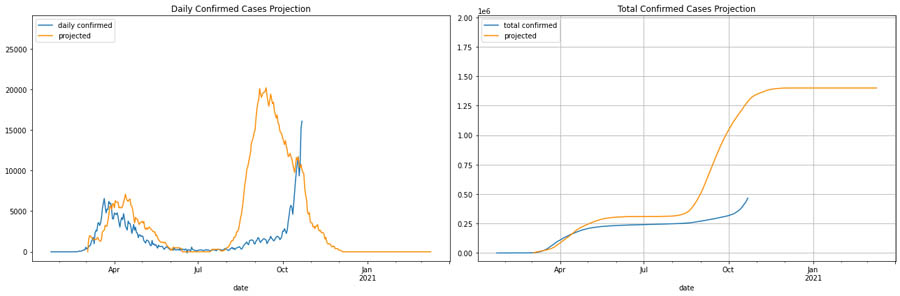
在第一波爆发期间,较为温和的干预政策初期效果较好,而较严格的干预则有助于控制疫情的后期扩散。因此,在这种假设场景下,我们可以观察模型如何捕捉各种干预因素。如图所示,虽然第二波趋势与我们的预测相符,但其出现的时间点(首波爆发后的6个月)与实际动向不符。因此,对于意大利假设场景的最佳预测,应该是将第二波爆发的时间点转移到H1N1疫情的时间点,即同年秋季。
美国
在美国场景中,我们认为首波疫情的3个月之后即将出现第二波爆发,而干预政策将始终较为严格。总体而言,美国的情况更适合将《牛津冠状病毒政府反应跟踪计划》中提出的评分机制与较为严格的干预政策结合起来,我们也将这套组合引入了notebook以及本文示例当中。在这种假设场景下,我们观察到第二波爆发与H1N1同样发生在同年秋季。

印度马哈拉施特拉邦
我们在印度马哈拉施特拉邦案例中采用了稳定的干预政策水平,并预计第二波爆发将出现在6个月之后。左图所示为实际(蓝线)与估计(橙线)病例数。右图所示则为累积病例总数。在这种情况下,可以看到第二波爆发的规模与第一波基本相当。

疾病模拟器
我们使用有限状态机为人群中的每个个体建立疾病传播模型,而后报告群体的总体状况。我们为每个个体的疾病参数计算出概率分布,并通过均值、标准差以及上下限进行参数设置。例如,您可以设置参数,认定个体会在与感染者接触后的2到5天内出现症状,而大多数人会在2到3天内出现症状。同样的,您可以设置恢复期参数,例如在接触感染者后的14至21天之内恢复健康。这种随机性能够以个体水平为基础得出总体变化趋势,借此模拟现实世界中的情况。
我们的有限状态机类似于使用机器学习进行COVID-19投射中提出的模拟模型,其中也包含无症状个体引发的感染传播问题,如下图所示。默认状态机具备可扩展性,您可以向模型当中添加更多疾病传播状态。只要状态转移与新状态之间的关系拥有良好定义,即可保证转换后的结论同样可信。例如,您可以添加检测结果呈阳性的状态。

我们的疾病模拟还可以捕捉人口动态。当某人从一个州前往另一个州,则会引发群体层面的影响。例如,如果某人此前曾因健康问题而存在免疫力问题,或者是未遵守社交隔离政策,则可能会从“易感状态”转为“接触状态”。从理论上讲,我们的仿真模型会在自动机网络中对每个人的状态进行迭代[4]。状态转换的概率由以下两种因素驱动:
- 特定于疾病的个别因素——关于特定个体的症状持续时间的概率密度,决定了其从“接触状态”到“系统发病”的周期。
- 特定于传播的群体因素——社交范围较大或直接接触过感染者的个体,从易感状态转变为接触状态的可能性更高。
学习模拟参数
模拟体系当中包含不同类型的参数。其中某些参数对于研究人员及科学家属于已知或已发现结果,例如出现症状前的间隔天数。您可以从机构发布的实际数据中了解其他参数,例如传播率(不同人群之间的传播率参数具有很大区别)等,这些参数随着时间推移也可能迅速变化。以下是ML学习方法中的三大核心模拟参数:
- 传播率——传播率可以直接从目标位置的近期病例数量中计算得出,也可以从与目标位置传播率模式相匹配的全国传播率期望值中得出。由于大多数地区(国家/州/县)已经度过第一波高峰或者迎来了第二波爆发,因此来自各个国家的每日确认病例数据本身一般能够带来更可靠的传播率结论。
- 达到第一波感染高峰的时间(几周)——可以从具有匹配传播率模式的国家中学习此参数。对于已经度过第一波峰值的区域,则可通过每日确诊病例曲线的滑动窗口分析捕捉此项参数。如果没有足够多的匹配国家/地区,也可选择可配置范围,例如1至5周。
- 传播控制——此参数的可配置范围,源自特定验证时间范围内对已知病例数量的模拟与纠错。100%的干预无法阻止100%传播,干预措施往往只能控制整个传播范围内的一小部分。此参数以分数形式表示,而且在不同区域之间往往存在很大差异。可以通过迭代模拟试验,将首轮峰值数据与特定范围(例如0.1至1)的值进行拟合以学习此项参数。
学习干预评分
我们通过以下三种方式,对干预措施的效果进行评分:
- 拟合严格度指数得分——使用OXCGRT提供的严格度指数(
score_stringency_idx)作为因变量,拟合回归模型当中每日干预措施的得分。接下来,提取干预效果得分并作为集成回归模型中的特征重要度指标。 - 拟合确诊病例数——将回归病例模型中的每日干预得分与确诊病例数年的变化(移动平均值)进行拟合以作为因变量。特征重要度得分即表示干预效果。
- 观察病例数变化——通过逐一消除干预措施以衡量总病例数的变化。根据消除之后引发的病例数影响,对各项干预措施进行相应评分。
最后,将这三项分数通过可配置加权平均值进行合并。虽然不同干预措施之间存在共存关系及一定相关性影响,但总体而言,这个过程基本可以体现干预措施的近似相对有效性得分。
工具集的局限性
我们的这套工具集存在以下局限性:
- 我们的疾病模型预计会在高斯分布之后出现多轮峰值,这种模式在以往的流感大流行中有着明确体现[2]。
- 我们的疾病模型中未包含死亡率指标;但大家能够相对简单地扩展有限状态机以引入这项指标。
- 国家一级的干预评分,在某种程度上也将影响州、县等基础层级的疫情变化。但更准确的方法,应该是在相应的区域级别收集并使用干预得分。
- 由于潜在的概率因素,因此人口规模必须足够大(例如人群数量在1000人以上)。
- 尽管我们根据牛津学院最近发表的一项研究将感染者的病毒传播率设定为1:3,但这一数字应该会在不同人群当中有所差异。因此,我们决定将此设为一项可配置参数。目前有多项研究表明,无症状感染者才是最重要的传播源。
- 我们的模型旨在模拟代码repo中的前两轮感染高峰,您也可以根据需要添加更多波次。
工具集架构的深入探讨
在本节中,我们将深入探讨工具集架构中的五大核心组成部分。
- 引导部分——公开各项可配置参数。可配置参数能够在0.1至1之间进行调整。同样的,波次1_周数(wave1_weeks)初步设定为2周,配置范围则为1至5周。
- 感染波次分析:我们对每日确诊病例数据进行滑动窗口分析,借此检测第一与第二轮波次的起点与峰值。此信息随后可由模拟器用于推理参数的潜在概率分布。
- 干预效果评分器——我们使用监督学习、OXCGRT[1]或其他来源的研究数据来估算人群的干预效果得分。以此为基础,我们还创建出一项加权平均得分。
- 优化器——优化模型能够反复更改有待学习的参数,并减少根据历史数据预测发病率时产生的误差。
- 预测——在为特定国家或人群建立了模拟参数之后,我们可以使用干预效果评分(特定疾病动态模式随时间推移的假设场景,例如6个月后出现第二波爆发)运行模拟,借此预测未来干预措施给疫情带来的相对影响。
工具集输入与输出
输入如下:
- 来自60多个国家的每日感染病例数字。
- 每天对超过10种干预措施进行国家/地区评分,例如居家隔离与学校停课。
- 带有峰值、时间点与持续时长的疾病传播模式。
- 模拟持续时间。
我们的输出结果,则是模拟过程中的发病率。
总结
我们的开源代码能够在各区域粒度上模拟COVID-19病例的变化情况。输出结果是在特定干预政策之下,对目标国家或地区在特定时间范围内确诊病例总数的预测结果。
我们的解决方案首先尝试分析疾病的发病模式,借此了解目标实体(国家/州)每日COVID-19病例达到峰值的大概时间点与预期发病率。接下来,这套方案采用仿真模型及相应优化技术选择最佳参数。最后,其通过自爆发点起到未来指定时段内的持续时长、每日确诊数以及累计确诊数做出预测。
作为起步参考,我们在https://github.com/aws-samples/covid19-simulation中的 covid19_simulator.ipynb notebook是发布了面向各国家及州层级的模拟示例,您可以在Amazon SageMaker或本地环境中运行这些模拟方案。
参考文献
[1] 《牛津冠状病毒政府响应跟踪计划》 https://www.bsg.ox.ac.uk/research/research-projects/coronavirus-government-response-tracker
[2] Mummert A, Weiss H, Long LP, Amigó JM, Wan XF (2013年),《对于多波次流感大流行的一种观点》 PLOS ONE 8(4): e60343. https://doi.org/10.1371/journal.pone.0060343
[3] Viceconte, Giulio, Nicola Petrosillo,《COVID-19 R0:幻数还是难题?》,2020年2月24日, 传染病报告第12卷,1 8516。doi:10.4081/idr.2020.8516 https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7073717/
[4] https://nyuscholars.nyu.edu/en/publications/automata-networks-and-artificial-intelligence)
常见问题解答
问:什么是发病率与患病率?
发病率是指特定时段之内,人群中新病例的发生比例。发病率是一种将时间直接纳入分母的发生率指。患病率与发病率不同,因为患病率包括特定时段内人群中所有新增病例以及原有病例的总和,而发病率仅限于新增病例。
问:如何评估干预措施的效果?
干预效果可以通过以下三种方式进行评分:
- 拟合严格度指数得分——使用OXCGRT提供的严格度指数(
score_stringency_idx)作为因变量,拟合回归模型当中每日干预措施的得分。接下来,提取干预效果得分并作为集成回归模型中的特征重要度指标。 - 拟合确诊病例数——将回归病例模型中的每日干预得分与确诊病例数年的变化(移动平均值)进行拟合以作为因变量。特征重要度得分即表示干预效果。
- 观察病例数变化——通过逐一消除干预措施以衡量总病例数的变化。根据消除之后引发的病例数影响,对各项干预措施进行相应评分。
最后,将这三项分数通过可配置加权平均值进行合并。虽然不同干预措施之间存在共存关系及一定相关性影响,但总体而言,这个过程基本可以体现干预措施的近似相对有效性得分。
问:如何计算预期的传播率与达到峰值的时间?
对于特定地区的新增病例比例以及传播率增长模式,我们的解决方案会首先确定过去曾表现出相似模式、且最终趋于平稳的国家/地区。根据这些参考国家/地区,方案会确定达到峰值所需要的时长以及每日/平均/中位数增长率。当发现多个相匹配的国家/地区时(默认阈值为5个),则进一步使用模式与人口相似度进行比对,并将预期的传播率及达到峰值的时长进行加权平均值计算。
问:各项参数如何学习得出?
这套解决方案持续将模拟结果与已确认的病例数量进行拟合,借此了解其所处环境(国家或州)内的传播率。作为可选项,您也可以借此预测达到感染传播峰值的潜在时长(以周为单位)。在优化之前,方案会通过具有相似传播模式的其他国家/地区的数据估算出达到峰值所需要的时间。
问:模拟作业可以在疾病变化时间表上的任意一点处开始吗?
不行。我们的解决方案中有一项关键参数,即近期传播率变化(增长)。如果模拟切入点处于疾病发展初期,则传播率可能太低而无法支持有意义的未来预测。同样的,如果模拟从平稳期或者下降期处切入,则传播率变化可能为负,进而引发错误预测。这套解决方案最适合在疾病发展的中高增长阶段切入。
本篇作者