亚马逊AWS官方博客
推出 Amazon Kinesis Data Analytics Studio – 使用 SQL、Python 或 Scala 与流数据快速交互
及时获得见解并对从您的企业和应用程序接收的新信息做出快速反应的最佳方式是分析流数据。这些数据通常必须按顺序和以增量方式按记录或者通过滑动时间窗口进行处理,并且可用于各种分析,包括关联、聚合、筛选和采样。
为了更轻松地分析流数据,今天,我们非常高兴推出 Amazon Kinesis Data Analytics Studio。
现在,通过 Amazon Kinesis 控制台,您可以选择 Kinesis 数据流,并且只需单击一下即可启动由 Apache Zeppelin 和Apache Flink 提供支持的 Kinesis Data Analytics Studio 笔记本,以便交互式分析流中的数据。同样,您可以在 Amazon Managed Streaming for Apache Kafka 控制台中选择集群,以启动笔记本来分析 Apache Kafka 流中的数据。您还可以从 Kinesis Data Analytics Studio 控制台中启动笔记本并连接到自定义源。

在笔记本中,您可以使用 SQL 查询和 Python 或 Scala 程序与流数据交互并立即获得结果。如果您对结果满意,则只需单击几下,您即可将代码提升至大规模、可靠运行地生产流处理应用程序,无需额外的开发工作。
对于新项目,我们建议您使用新的 Kinesis Data Analytics Studio,而不是 Kinesis Data Analytics for SQL 应用程序。Kinesis Data Analytics Studio 将易用性和高级分析功能相结合,这使得可以在几分钟内快速构建复杂的流处理应用程序。我们来看看这些步骤的实际操作。
使用 Kinesis Data Analytics Studio 分析流数据
我想要更好地了解某些传感器发送给 Kinesis 数据流的数据。
为了模拟此工作负载,我使用此 random_data_generator.py Python 脚本。您无需知道 Python 即可使用 Kinesis Data Analytics Studio。实际上,我将在以下步骤中使用 SQL。此外,您还可以避免任何编码工作,并使用 Amazon Kinesis 数据生成器用户界面 (UI) 将测试数据发送 Kinesis Data Streams 或 Kinesis Data Firehose。我将使用 Python 脚本来更精细地控制正在发送的数据。
import datetime
import json
import random
import boto3
STREAM_NAME = "my-input-stream"
def get_random_data():
current_temperature = round(10 + random.random() * 170, 2)
if current_temperature > 160:
status = "ERROR"
elif current_temperature > 140 or random.randrange(1, 100) > 80:
status = random.choice(["WARNING","ERROR"])
else:
status = "OK"
return {
'sensor_id': random.randrange(1, 100),
'current_temperature': current_temperature,
'status': status,
'event_time': datetime.datetime.now().isoformat()
}
def send_data(stream_name, kinesis_client):
while True:
data = get_random_data()
partition_key = str(data["sensor_id"])
print(data)
kinesis_client.put_record(
StreamName=stream_name,
Data=json.dumps(data),
PartitionKey=partition_key)
if __name__ == '__main__':
kinesis_client = boto3.client('kinesis')
send_data(STREAM_NAME, kinesis_client)此脚本使用 JSON 语法将随机记录发送给我的 Kinesis 数据流。例如:
从 Kinesis 控制台中,我选择了一个 Kinesis 数据流 (my-input-stream) 并从 Process(处理)下拉菜单中选择 Process data in real time(实时处理)。通过这种方式,流被配置为笔记本的源。

然后,在下面的对话框中,我将创建一个 Apache Flink – Studio 笔记本。
我为该笔记本输入了一个名称 (my-notebook) 和描述。从我之前选择的 Kinesis 数据流 (my-input-stream) 读取的 AWS Identity and Access Management (IAM) 权限将会自动附加到笔记本担任的 IAM 角色。

我选择 Create(创建)以打开 AWS Glue 控制台并创建一个空的数据库。返回 Kinesis Data Analytics Studio 控制台,我刷新了列表并选择新的数据库。它将定义我的源和目标的元数据。从这里,我还可以查看默认的 Studio 笔记本设置。然后,我选择 Create Studio notebook(创建 Studio 笔记本)。

创建笔记本之后,我选择 Run(运行)。
在笔记本运行时,我选择 Open in Apache Zeppelin(在 Apache Zeppelin 中打开)以获取该笔记本的访问权限,并以 SQL、Python 或 Scala 编写代码以与我的流数据交互并实时获得见解。
在笔记本中,我创建了一个新的笔记并将其称之为 Sensors.然后,我创建了一个 sensor_data 表,用于描述流中的数据的格式:
%flink.ssql
CREATE TABLE sensor_data (
sensor_id INTEGER,
current_temperature DOUBLE,
status VARCHAR(6),
event_time TIMESTAMP(3),
WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND
)
PARTITIONED BY (sensor_id)
WITH (
'connector' = 'kinesis',
'stream' = 'my-input-stream',
'aws.region' = 'us-east-1',
'scan.stream.initpos' = 'LATEST',
'format' = 'json',
'json.timestamp-format.standard' = 'ISO-8601'
)
上一个命令中的第一行告知 Apache Zeppelin 为 Apache Flink 解释器提供流 SQL 环境 (%flink.ssql)。此外,我还可以使用批量 SQL 环境 (%flink.bsql)、Python (%flink.pyflink) 或 Scala (%flink) 代码与流数据进行交互。
对于使用过 SQL 和数据库的用户来说,CREATE TABLE 语句的的一部分非常熟悉。将会创建一个表用于存储流中的数据。WATERMARK(水印)选项用于以事件时间衡量进度,如 Apache Flink 文档的“事件时间和水印”部分所述。
CREATE TABLE 语句的第二部分描述用于接收表中的数据(如 kinesis 或 kafka)、流名称、AWS 区域、流的整体数据格式(如 json 或 csv)和时间戳使用的语法(在本例中为 ISO 8601)的连接器。我也可以选择处理流的起始位置,我首先将会使用 LATEST 读取最新的数据。
表就绪后,我将会在创建笔记本时选择的 AWS Glue 数据目录数据库中找到它:

现在,我可以在 sensor_data 表中运行 SQL 查询,并使用滑动或翻滚窗口来更好地了解我的传感器中发生的情况。。
为了概括了解流中的数据,我将会从简单的 SELECT 入手以获取 sensor_data 表中的所有内容:
%flink.ssql(type=update)
SELECT * FROM sensor_data;此时,第一行命令中包含一个参数 (type=update),因此当新的数据抵达时 SELECT 的输出(不只一行)将持续更新。
在我的笔记本终端上,我启动 random_data_generator.py 脚本:
首先,我会看到一个包含数据的表。为了更好地了解,我选择了 bar graph(条形图)视图。然后,我按状态对结果进行了分组,以查看其平均 current_temperature,如下所示:
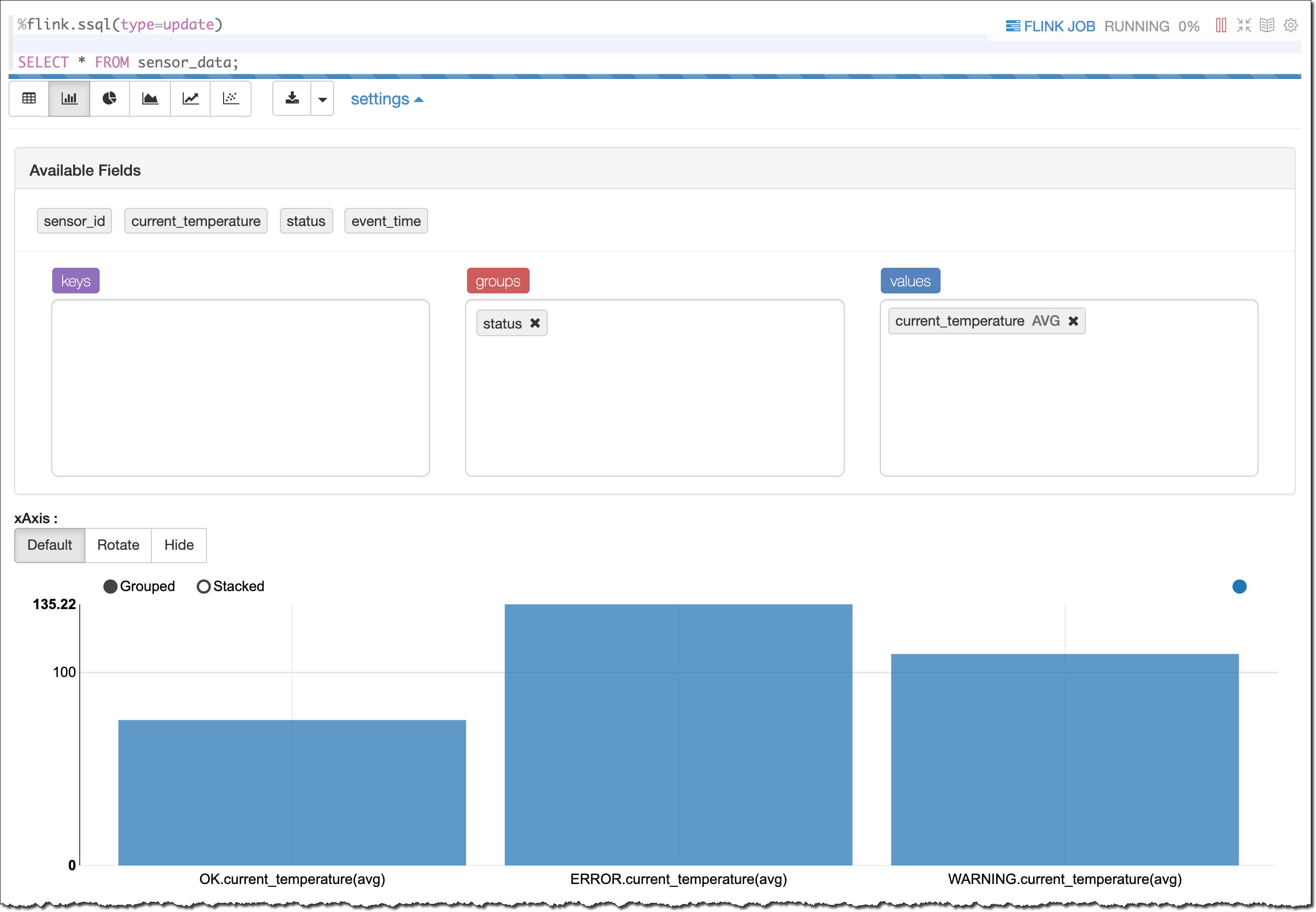
正如我生成这些结果所预期的一样,我会看到不同的平均温度,具体取决于状态(OK(正常)、WARNING(警告)或 ERROR(错误))。温度越高,传感器中出现不正常工作的可能性越大。
我可以使用 SQL 语法显式运行聚合查询。这一次,我想要在 1 分钟的滑动窗口计算结果,并且结果每 10 秒钟更新一次。为此,我在 SELECT 语句的 GROUP BY 部分中使用 HOP 函数。要将时间添加到选择的输出,我使用 HOP_ROWTIME 函数。有关更多信息,请参阅 Apache Flink 文档中的“组窗口聚合工作原理”。
%flink.ssql(type=update)
SELECT sensor_data.status,
COUNT(*) AS num,
AVG(sensor_data.current_temperature) AS avg_current_temperature,
HOP_ROWTIME(event_time, INTERVAL '10' second, INTERVAL '1' minute) as hop_time
FROM sensor_data
GROUP BY HOP(event_time, INTERVAL '10' second, INTERVAL '1' minute), sensor_data.status;此时,我将查看以表格式显示的结果:

为了将查询结果发送至目标流,我创建了一个表并将该表连接到流。首先,我需要授予笔记本电脑写入流的权限。
在 Kinesis Data Analytics Studio 控制台中,我选择了 my-notebook。然后,在 Studio notebooks details(Studio 笔记本详细信息)部分,我选择了 Edit IAM permissions(编辑 IAM 权限)。在这里,我可以配置笔记本使用的源和目标,并且 IAM 角色权限将会自动更新。

在 Included destinations in IAM policy(IAM 策略中所含的目标)部分,我选择了目标并选择 my-output-stream。保存更改并等待笔记本更新。现在,我将开始使用目标流。
在笔记本中,我创建了一个连接到 my-output-stream 的 sensor_state 表。
%flink.ssql
CREATE TABLE sensor_state (
status VARCHAR(6),
num INTEGER,
avg_current_temperature DOUBLE,
hop_time TIMESTAMP(3)
)
WITH (
'connector' = 'kinesis',
'stream' = 'my-output-stream',
'aws.region' = 'us-east-1',
'scan.stream.initpos' = 'LATEST',
'format' = 'json',
'json.timestamp-format.standard' = 'ISO-8601');现在,我将使用此 INSERT INTO 语句来将选择的结果持续插入到 sensor_state 表中。
%flink.ssql(type=update)
INSERT INTO sensor_state
SELECT sensor_data.status,
COUNT(*) AS num,
AVG(sensor_data.current_temperature) AS avg_current_temperature,
HOP_ROWTIME(event_time, INTERVAL '10' second, INTERVAL '1' minute) as hop_time
FROM sensor_data
GROUP BY HOP(event_time, INTERVAL '10' second, INTERVAL '1' minute), sensor_data.status;
这些数据还会发送至目标 Kinesis 数据流 (my-output-stream),以供其他应用程序使用。例如,目标流中的数据可用于更新实时仪表板,或者在软件更新后监控我的传感器的行为。
我对结果非常满意。我想要将此查询及其输出部署为 Kinesis Analytics 应用程序。
首先,我需要在我的笔记本中创建一个 SensorsApp 笔记,并复制我想要作为应用程序的一部分执行的语句。表已创建完毕,因此,我只需复制上面的 INSERT INTO 语句。
然后,从我的笔记本右上角的菜单中,选择 Build SensorsApp and export to Amazon S3(构建 SensorsApp 并导出到 Amazon S3),然后确认应用程序名称。

导出就绪后,我在相同菜单中选择 Deploy SensorsApp as Kinesis Analytics application(将 SensorsApp 部署为 Kinesis Analytics 应用程序)。之后,我对应用程序的配置进行了微调。我将 parallelism(平行度)设为 1,因为我的输入 Kinesis 数据流中只有一个分片,并没有太多流量。然后,我运行应用程序,无需编写任何代码。
从 Kinesis Data Analytics 应用程序控制台中,选择 Open Apache Flink dashboard(打开 Apache Flink 仪表板),以了解有关应用程序的执行情况的更多信息。

可用性和定价
现在,您可以在正式推出 Kinesis Data Analytics 的所有 AWS 区域中使用 Amazon Kinesis Data Analytics Studio。有关更多信息,请参阅 AWS 区域服务列表。
在 Kinesis Data Analytics Studio 中,我们运行 Apache Zeppelin 和 Apache Flink 的开源版本,并且我们在上游做出了更改。例如,我们对 Apache Zeppelin 进行了错误修复,并且我们为 Apache Flink 提供了 AWS 连接器,如适用于 Kinesis Data Streams 和 Kinesis Data Firehose 的连接器。此外,我们将与 Apache Flink 社区携手合作,以提高可用性,包括对运行时错误自动进行分类,以了解是用户代码还是应用程序基础架构中存在错误。
使用 Kinesis Data Analytics Studio 时,您需要根据每小时的平均 Kinesis 处理单元 (KPU)(包括正在运行的笔记本使用的 KPU)数量付费。一个 KPU 包含 1 个计算 vCPU、4 GB 内存和关联的网络。您还需要为正在运行的应用程序存储以及持久应用程序存储付费。有关更多信息,请参阅 Kinesis Data Analytics 定价页面。
立即开始使用 Kinesis Data Analytics Studio,以更好地了解您的流数据。
– Danilo