亚马逊AWS官方博客
利用 Amazon Aurora Global Database 提升业务连续性
Original URL: https://amazonaws-china.com/cn/blogs/database/improving-business-continuity-with-amazon-aurora-global-database/
利用Amazon Aurora Global Database提升业务连续性
随着企业业务的日益全球化,您对于数据库的需求也将随之扩展。举例来说,您在苏黎世的团队与位于北京的办公室必须以同样的速度、同样的安全性以及同样的便捷性使用完全相同的资源。为此,我们推出Amazon Aurora Global Database,旨在将您的Amazon Aurora数据库资源推向全世界。
Aurora能够在其名为“保护组”的10 GB逻辑单元中构建存储卷。以此为基础,它将跨越同一区域内三个可用区的六个存储节点,将各保护组内的数据进行往来复制。如果数据量超出当前分配的存储量,则Aurora可以无缝扩展分配容量以满足业务需求,并根据实际情况灵活添加新的保护组。
初次亮相于re: Invent 2018大会的Aurora Global Database则进一步将复制流程扩展到AWS云的区域层面。这不仅带来更快的跨区域灾难恢复,也实现了高性能、低延迟的跨区域读取扩展。凭借Aurora Global Database,您可以将数据库扩展至多个区域,并将对数据库性能造成的影响控制在最低水平。
在本文中,我们将介绍Aurora Global Database的基本情况,并探讨其优势与实际用例。
Aurora Global Database是什么?
Aurora Global Database即Aurora全局数据库,能够跨越多个区域实现服务中断状况下的灾难恢复,并以更低延迟支持全局读取。
作为Aurora中的一项功能,Global Database在Aurora的专用存储层内借助专用基础设施以处理跨区域复制操作。存储层内的专用复制服务器负责承担全部复制任务,从而在不影响数据库性能的前提下为用户提供更强的业务恢复能力与可用性水平。
与传统方案相比,Aurora Global Database中使用的MySQL二进制日志复制与存储复制拥有一系列关键区别。首先,逻辑复制(或者说二进制日志复制)会在复制源(即主数据库)上记录数据变更的语句或行更改,而后将其重新应用于复制目标(副本数据库)。主数据库与副本数据库彼此独立,并可包含相互不同的数据集。
在另一方面,Aurora Global Database利用物理存储级复制创建出与主数据库内数据集完全相同的副本,从而消除了对二进制日志的依赖性。换句话说,Global Database的次区域实例不再需要重播数据修改的语句,这就大大减少了复制开销,并为应用程序工作负载预留出更多容量。
如此一来,来自写入程序的已提交事务通常会在一秒之内被全局复制到您所选定的区域。当Global Database处理这项复制之后,相关数据即可被永久保存在集群所在区域内的三个可用区当中。
为什么使用Global Database?
Aurora Global Database能够提供以下几项重要助益:
- 快速实现指向次区域的全局故障转移
- 带来更低的跨区域复制延迟
- 几乎不会对数据库性能造成影响
- 兼容MySQL
快速实现指向次区域的全局故障转移
可靠的灾难恢复能力是支持业务连续性计划的核心前提,也是抵御意外事件的有力武器。Aurora Global Database在灾难恢复中的两大重要指标上拥有出色的表现:
- RTO(恢复时间目标)——即灾难发生后,需要多长时间才能恢复正常工作状态。
- RPO(恢复点目标)——灾难事件可能破坏的数据量。
在Aurora Global Database的支持下,RPO将被控制在5秒以内——这将最大程度降低数据丢失,而RTO也保持在1分钟以下、显著缩短停机时长。
Aurora Global Database提供灾难恢复功能,即使在所处区域范围内发生故障时亦可继续运行。在数据库发生潜在降级或者隔离期间,Aurora Global Database会快速响应并将次区域提升为主区域。借助全局存储复制功能,提升后的新主区域能够在一分钟内接管全部读取/写入工作负载,从而最大程度降低故障问题对应用程序正常运行时间的影响。
带来更低的跨区域复制延迟
除了提供灾难恢复功能之外,Aurora Global Database还允许用户将指向主区域的数据读取操作快速转移至次区域。Aurora Global Database的常规复制等待时长低于1秒,上限不超过5秒。极低的延迟水平,意味着您的在线事务处理(OLTP)工作负载可轻松实现全局读取扩展。
此外,低延迟还允许您更快为全局客户端应用程序提供读取服务,进而实现更佳用户体验与参与度改善。在Aurora Global Database的支持下,客户对跨区域应用程序堆栈执行的操作将共享相同的配置数据,并以近即时方式实现数据复制。
如果您在全球设有多家办事处,且客户群体分布在世界各地,则可在主区域处上传您的内容,并保证以本地级别延迟将内容交付给身在各个位置的客户。
几乎不会对数据库性能造成影响
Aurora存储层中的Aurora Global Database专用基础设施能够确保配置在主区域及次区域内的数据库资源始终完全可用,进而支持各类应用程序工作负载。更重要的是,Aurora复制操作几乎甚至完全不会对主数据库集群性能造成影响。
快速跨区域迁移
Aurora Global Database能够将生产数据库直接复制至另一AWS区域,借此实现应用程序迁移。在更新次区域之后,您可以将副本数据库从Aurora Global Database中分离出来,并像使用常规Aurora数据库集群那样对其执行操作。在将现有独立集群接入目标区域内的应用程序堆栈之后,该集群将立即开始提供读取/写入工作负载支持。
兼容MySQL
Aurora Global Database目前已经支持Amazon Aurora的MySQL兼容性。凭借着MySQL技能的广泛普及,全球各地的应用程序开发者都将在延续自身使用习惯的同时,充分享受到开源数据库带来的灵活性优势。
创建Aurora Gobal Database
您可以通过AWS Management Console、AWS CLI或者在AWS CLI/SDK中运行 CreateGlobalCluster操作以创建Aurora Global Database。若需了解更多细节信息,请参阅创建Aurora Global Database。
在以下截图当中,我启动了一个Aurora Global Database,其中主集群位于美国西部2(俄勒冈州)区域,次集群则位于美国东部1(北弗吉尼亚州)区域。关于如何添加次集群的细节信息,请参阅向Aurora Global Database添加AWS区域。
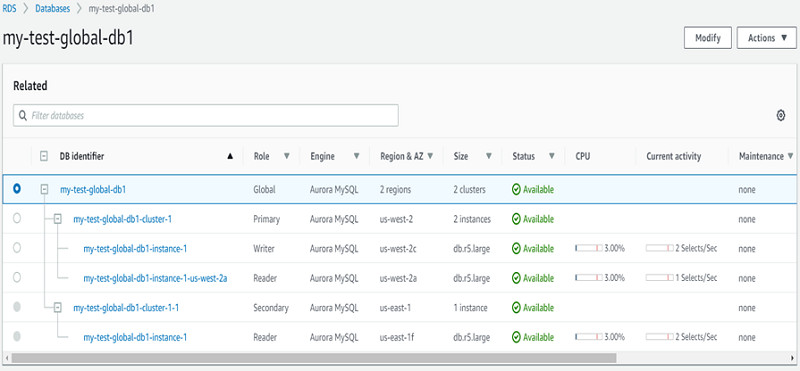
若需了解如何从Aurora Global Database中删除集群、执行故障转移或者导入数据,请参阅Amazon Aurora Global Database使用指南。
总结
在本文中,我们介绍了Aurora Global Database功能。在它的帮助下,用户可以利用快速灾难恢复机制轻松应对所在区域内发生的大规模故障,亦可灵活将数据交付至全球不同区域内的客户应用程序当中。
如果您还有其他疑问或反馈,请通过aurora-pm@amazon.com与我联系,或者直接在本文下方留言。我期待听取大家的意见与建议。