亚马逊AWS官方博客
使用经 EMRFS S3 优化的提交器提高 Apache Spark 写入 Apache Parquet 格式文件的性能
与 FileOutputCommitter 比较
在 Amazon EMR 5.19.0 版和更早版本中,默认情况下,将 Parquet 写入 Amazon S3 的 Spark 作业使用称为 FileOutputCommitter 的 Hadoop 提交算法。此算法有两个版本,版本 1 和 2。两个版本都依赖于将中间任务输出写入到临时位置。它们随后执行重命名操作,以使数据在任务或作业完成时可见。
算法版本 1 有两个重命名阶段:第一个阶段在提交单个任务各自的输出时,另一个阶段在提交已完成的或者成功的任务的整体作业输出时。算法版本 2 效率更高,因为任务提交时直接将文件重命名到最终输出位置。这省去了第二个重命名阶段,但是它使部分数据在作业完成之前可见,并非所有工作负载都允许这样做。
在Hadoop 分布式文件系统 (HDFS) 上重命名是仅针对元数据的快速操作。但是,将输出写入对象存储(例如 Amazon S3)时,重命名是通过将数据复制到新目标然后删除源文件来实现的。目录重命名会加剧这种重命名的“代价”,这种情况会在 FileOutputCommitter v1 的两个阶段中发生。尽管这些是 HDFS 上仅针对纯元数据的操作,但在S3上提交程序必须执行 N 次复制和删除操作。
为了部分缓解这种情况,当在 Spark 中使用 EMRFS 将 Parquet 数据写入 S3 时,Amazon EMR 5.14.0+ 默认为 FileOutputCommitter v2。经 EMRFS S3 优化的新提交程序在此工作上进行了改进,通过使用 Amazon S3 分段上传的事务属性来完全避免重命名操作。然后,任务可以将其数据直接写入最终输出位置,将每个输出文件的完成推迟到任务提交时间之后。
性能测试
通过执行以下 INSERT OVERWRITE Spark SQL 查询,我们评估了不同提交程序的写入性能。SELECT * FROM range(…) 子句在执行时生成数据。这产生了15GB的数据恰好写入到Amazon S3上的100个Parquet文件中。
注意:EMR 集群与 S3 存储桶所在同一 AWS 区域中运行。使用 UUID 生成器来生成不同的trial_id值,确保运行的测试之间没有冲突。
我们在使用 emr-5.19.0 标签版本创建的 EMR 集群上执行了测试,该集群在master group中具有一个 m5d.2xlarge 实例,在core group中具有八个 m5d.2xlarge 实例。我们使用 Amazon EMR 为该集群设置的默认 Spark 配置属性,包括以下内容:
在为每个提交程序进行 10 次试运行后,我们捕获了查询执行时间并在下表中进行了总结。FileOutputCommitter v2 平均为 49 秒,而经 EMRFS S3 优化的提交程序平均仅为 31 秒,即 1.6 倍的加速。
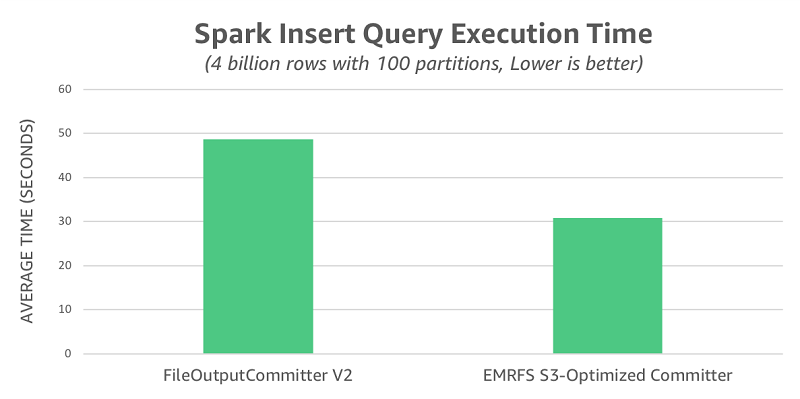
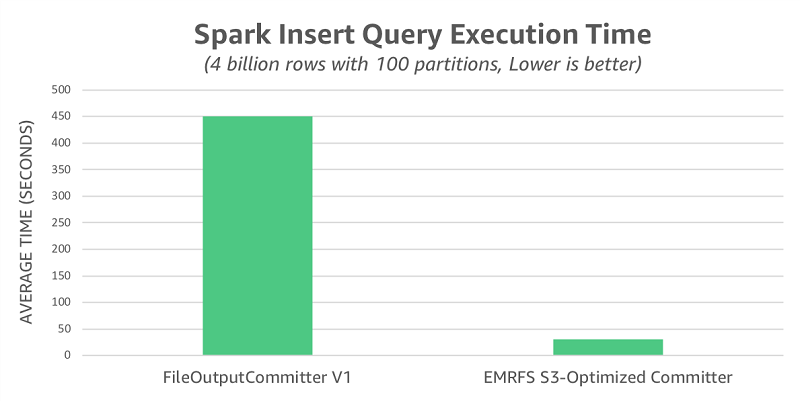
如前所述,FileOutputCommitter v2 部分但不是全部地消除了 FileOutputCommitter v1 使用的重命名操作。为了说明重命名对 S3 的全部性能影响,我们使用 FileOutputCommitter v1 重新运行了该测试。在此场景中,我们观察到平均运行时间为 450 秒,比经 EMRFS S3 优化的提交程序慢 14.5 倍。
我们评估的最后一个场景是启用 EMRFS 一致性视图时的情况,该视图解决了由于 Amazon S3 数据一致性模型而可能引起的问题。在这种模式下,经 EMRFS S3 优化的提交程序时间不受此更改的影响,仍保持平均 30 秒。另一方面,FileOutputCommitter v2 平均需要 53 秒,这比关闭一致性视图功能时要慢,将整体性能差异扩大到 1.8 倍。

作业正确性
经 EMRFS S3 优化的提交程序具有与 FileOutputCommitter v2 同样的局限性,因为两者都通过将提交责任完全委派给各个任务来提高性能。下面讨论该设计选择所带来的显著影响。
不完整或失败作业产生部分结果
由于两种提交程序都将任务写入最终输出位置,因此使用任何一种时,并发读取同一位置的读取者都可以查看到部分结果。如果作业失败,则在整个作业失败之前提交的所有任务都将留下部分结果。如果在没有先清理输出位置的情况下再次运行该作业,则可能导致重复输出。
缓解此问题的一种方法是确保作业每次运行都使用不同的输出位置,仅在作业成功时才将位置发布给下游读取器。以下代码块是针对使用 Hive 表的工作负载的策略示例。请注意每次运行作业时如何将 output_location 设置为唯一值,并且仅当余下的查询成功时才注册表分区。只要读取器通过表抽象以独占方式访问数据,它们就无法在作业完成之前看到结果。
这种方法要求将分区指向的位置视为不可变的。要更新分区内容,需要将所有结果重新放入 S3 中的新位置,然后更新分区元数据以指向该新位置。
来自非幂等任务的重复结果
可能导致两种提交程序均产生错误结果的另一种情况是,由非幂等任务组成的作业将每次任务的输出结果尝试生成到不确定的位置。
以下查询示例说明了该问题。它使用基于时间戳的表分区方案来确保它将每次任务结果尝试写入不同的位置。
通过确保任务在每次任务尝试中写入一致的位置,可以避免在这种情况下出现重复结果的问题。例如,不要在任务中调用返回当前时间戳的函数,而应考虑提供当前时间戳作为作业的输入。同样,如果作业中使用了随机数生成器,请考虑使用固定种子或基于任务分区号的种子,以确保重新尝试执行的任务使用相同的值。
注意:Spark 的内置随机函数 rand()、randn() 和 uuid() 在设计时已经考虑到这一点。
启用经 EMRFS S3 优化的提交程序
从 Amazon EMR 5.20.0 版开始,默认情况下已启用经 EMRFS S3 优化的提交程序。在 Amazon EMR 5.19.0 版中,您可以通过在 Spark 内或创建集群时将 spark.sql.parquet.fs.optimized.committer.optimization-enabled 属性设置为 true 来启用提交程序。当您使用 Spark 的内置 Parquet 支持将 Parquet 文件通过 EMRFS 写入 Amazon S3 时,提交程序才会生效。这包括将 Parquet 数据源与 Spark SQL、DataFrames 或 Datasets 一起使用。但是,在某些用例中,经 EMRFS S3 优化的提交程序不会生效,而在某些使用案例中,Spark 完全在提交程序之外执行自己的重命名。有关提交程序和这些特殊情况的更多信息,请参阅 Amazon EMR 发行指南中的使用经 EMRFS S3 优化的提交程序。
相关工作 – S3A 提交程序
经 EMRFS S3 优化的提交程序的灵感来自支持 S3A 文件系统的提交程序所使用的概念。关键要点是,这些提交程序使用 S3 分段上传的事务性来消除部分或全部重命名成本。这也是经 EMRFS S3 优化的提交程序所使用的核心概念。
有关生态系统中可用的各种提交程序(包括支持 S3A 文件系统的提交程序)的更多信息,请参阅正式的 Apache Hadoop 文档。
小结
与 FileOutputCommitter 相比,经 EMRFS S3 优化的提交程序提高了写入性能。从 Amazon EMR 5.19.0 版开始,您可以将其与 Spark 内置的 Parquet 支持一起使用。有关更多信息,请参阅 Amazon EMR 发行指南中的使用经 EMRFS S3 优化的提交程序。
关于作者
 Peter Slawski 是 Amazon Web Services 的一名软件开发工程师。
Peter Slawski 是 Amazon Web Services 的一名软件开发工程师。
 Jonathan Kelly 是 Amazon Web Services 的高级软件开发工程师。
Jonathan Kelly 是 Amazon Web Services 的高级软件开发工程师。