亚马逊AWS官方博客
如何使用 AWS Step Functions 和 AWS Glue 将 Amazon DynamoDB 表导出至 Amazon S3
重构数据管道
我在之前的博文中概要介绍的 AWS Data Pipeline 架构现已问世将近两年时间。我们曾使用数据管道将 Amazon DynamoDB 数据备份到 Amazon S3,以防发生灾难性的人为错误。但是,使用 DynamoDB 时间点恢复功能,我们便拥有了更好的原生灾难恢复机制。此外,对于数据管道,我们仍然负责着与集群本身相关的运维操作,即使这些集群只是短暂存在的。一个常见的挑战是如何让我们的集群与最新版本的 Amazon EMR 保持同步,以减少软件重大缺陷的影响。另一个不够高效的地方是需要为每个 DynamoDB 表启动一个 EMR 集群。
我决定回退一步,先列出我想在下一次迭代中拥有的功能:
- 使用 AWS Glue 而不是 EMR 导出表。
- AWS Glue 提供无服务器 ETL 环境,我不必关心底层基础设施。这可以最大限度地减少操作任务,比如与 EMR 发布标签保持一致。
- 使用适用于 AWS Glue 和 Amazon Athena 等服务的工作流程解决方案。
- 在第一次迭代中,工作流程分布在各种服务中。除非您对整个数据管道了然于心,否则很难直观了解管道的进展情况。
- 能够选择不同导出格式。
- 作为数据工程师,我青睐 Apache Parquet。但是,客户可能倾向于其他格式。
- 将导出的数据添加到 Athena。
- 我发现数据越容易查询,此数据被用到的可能性就越大。
架构概览
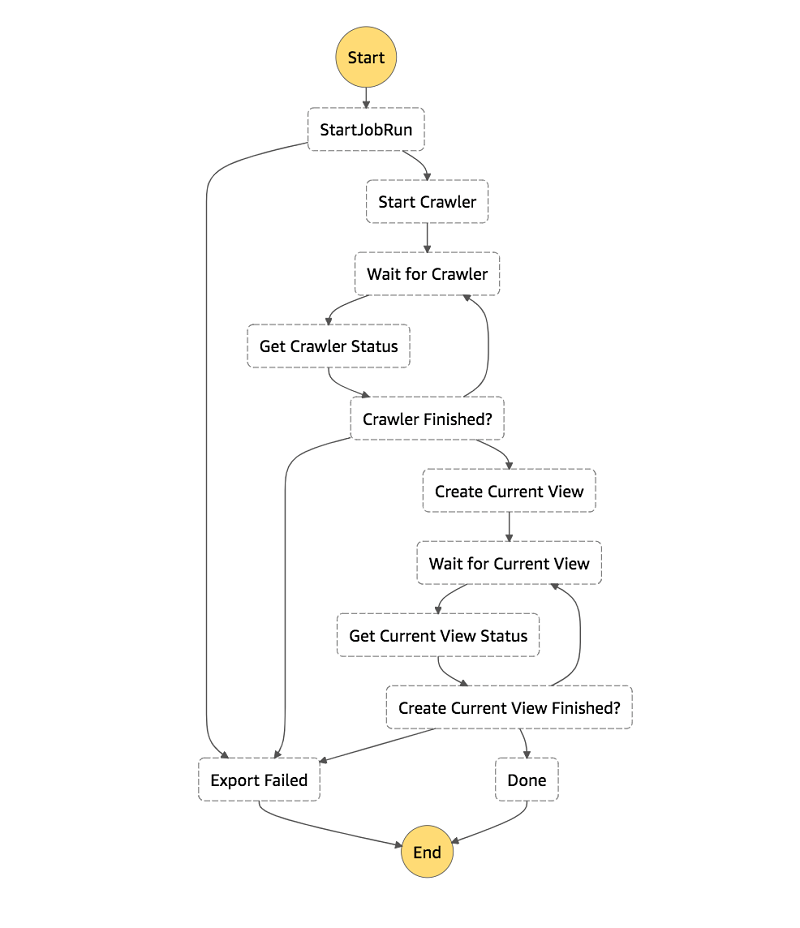
我们从全局来看这个架构:
- 我们使用 AWS Step Functions 作为工作流程引擎。
- 每个步骤要么是内置的 Step Functions 状态,要么是服务集成,或者是简单的用 Python 语言开发的 AWS Lambda。例如,GlueStartJobRun 按文档中所述使用同步作业运行服务集成。
- 我们获得整个管道的直观表示。
- 新开发人员可以快速上手。
- Amazon CloudWatch Events 中禁止启动的事件会触发一个 Step Functions 状态机,其 JSON 格式的事件数据中包含以下内容:
- AWS Glue 作业名称
- 导出目标位置
- DynamoDB 表名称
- 所需的读取百分比
- AWS Glue 爬网程序名称
- AWS Glue 以您的首选格式将 DynamoDB 表作为 snapshots_your_table_name 导出到 S3。数据按 snapshot_timestamp 进行分区
- AWS Glue 爬网程序在 AWS Glue Data Catalog 中添加或更新数据的架构和分区。
- 最后,我们创建一个仅包含最新导出快照数据的 Athena 视图。
一个简单的 AWS Glue ETL 作业
我创建的 AWS Glue ETL 作业脚本接受 DynamoDB 表名、读取吞吐量、导出文件名和格式作为参数。AWS Glue 在后台扫描 DynamoDB 表。AWS Glue 确保每个顶级属性都会被置于架构中,不管属性有多稀疏(详见 DynamoDB 文档)。
脚本如下:
脚本代码很简短。我们创建了 dynamodb 连接类型的 DynamicFrameReader,并传入表名和所需的最大读取吞吐量消耗。我们将该数据帧传递至 DynamicFrameWriter,后者将全表数据以指定的格式写入 S3。
Athena 视图
Amazon 大多数团队的应用程序都包含多个 DynamoDB 表,我自己的团队也是如此。我们当前的应用程序使用了五个主表。理想情况下,在导出工作流程结束时,您可以在一致的表视图中编写简单明了的查询。但是,每个导出的表都按表导出时的时间戳进行分区。这使得跨一个或多个表进行查询非常麻烦,因为您必须向查询中的每个表引用添加 WHERE snapshot_timestamp = 条件 子句。此外,每个表可能会在任何给定日期具有不同的 snapshot_timestamp 值!
此导出工作流程的最后一步会创建一个 Athena 视图,该视图可为您添加 WHERE 子句。这意味着您可以与 DynamoDB 导出数据进行交互,就好像导出的 DynamoDB 表是一个正常视图一样。
设置基础设施
我创建的 AWS CloudFormation 栈分为两个堆栈。公共堆栈包含共享的基础设施,每个 AWS 区域只需要创建一个。表堆栈的设计方式是,您可以在任何给定的 AWS 区域中为每个表-格式组合创建一个表堆栈。它包含导出和转换 DynamoDB 表所需的 CloudWatch 事件逻辑和 AWS Glue 组件。
创建公共堆栈
公共堆栈包含大部分基础设施。其中包括 Step Functions 状态机和 Lambda 函数,用于触发和检查异步作业的状态。此外,它还包括导出堆栈使用的 IAM 角色以及用于存储导出的 S3 存储桶。
要创建公共堆栈,请执行以下操作:
- 选择此启动堆栈
- 选择我确认 AWS CloudFormation 可能创建具有自定义名称的 IAM 资源。
- 选择创建堆栈。
创建表导出堆栈
如果您没有要导出的 DynamoDB 表,请按照原博文进行操作。从“处理评论堆栈”部分分开始往后执行,直到将这两个项目添加到表中。或者,您可以随意将此 CloudFormation 堆栈指向您最喜欢的同时使用预置吞吐量的 DynamoDB 表。目前不支持使用按需吞吐量的表。
由于此架构的大部分都是可以共享的,因此表导出堆栈中没有多少内容。此堆栈定义了 CloudWatch 事件,用于触发 Step Functions 状态机并在 JSON 格式的事件消息中包含所有必要元数据。此外,它还包含用于导出表的 AWS Glue ETL 作业和用于更新 AWS Glue Data Catalog 中元数据的 AWS Glue 爬网程序。
从技术上讲,您可以在公共堆栈中定义 AWS Glue ETL 作业,因为它已经被参数化。但是,AWS Glue 作业并发运行的默认限制为 3 项作业。这是一个软限制,但是使用这种架构,您可以在申请提高并发限制数之前最多导出 25 个表。
要创建表导出堆栈,请执行以下操作:
- 选择此启动堆栈
- 从列表中选择输出格式。Athena 原生支持所有可用格式。
- 输入 DynamoDB 表名称。
- 输入作业应从表的当前预置吞吐量中消耗的读取容量单位 (RCU) 的百分比。该百分比表示为 0.1(含)到 1.0(含)之间的浮点数。默认值为 0.25 (25%)。
例如:假设您的表的 RCU 设置为 100,并使用默认值 0.25 (25%),然后 AWS Glue 作业在运行时消耗 25 个 RCU。
- 选择创建。
启动状态机执行
为了演示相关工作原理,我们手动运行 DynamoDB 导出任务状态机,需要将 CloudWatch 事件的 JSON 参数传递给 Step Functions。
从 CloudWatch Events 获取事件 JSON 参数
要获取事件 JSON 参数,请执行以下操作:
- 在 AWS 管理控制台中打开 CloudWatch。
- 在事件下的左列中,选择规则。

- 从列表中选择您的规则。它以 AWSBigDataBlog- 为前缀。
- 对于操作,选择编辑。

- 从目标的配置输入部分复制事件的 JSON 参数。

- 选择取消退出编辑模式。
开始执行状态机
要开始执行状态机,请执行以下步骤:
1. 在控制台中打开 Step Functions。
2. 选择 DynamoDBExportAndAthenaLoad 状态机。

3. 选择开始执行。

4. 将 JSON 格式的有效负载粘贴到输入

5. 选择开始执行。
可以采用以下几种方法追踪执行过程。在进入和退出执行步骤时,系统会向执行事件历史记录列表添加条目。如果需要调试,这是查看传递到每个步骤的状态(Lambda speak 中的事件)的绝佳方法。
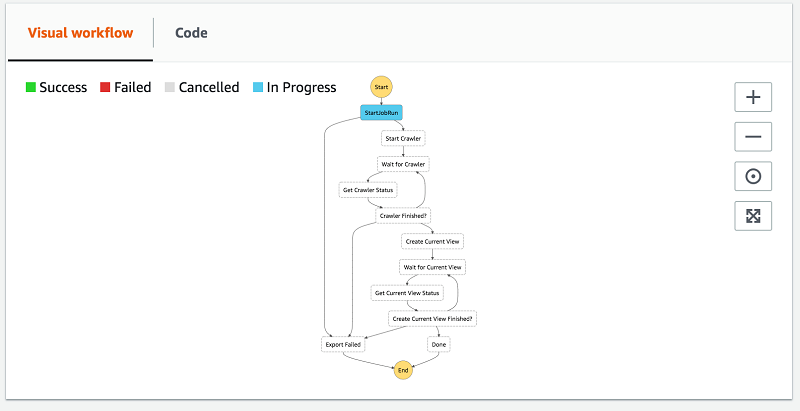
您还可以展开可视化工作流程。这是一个非常棒的概要视图,可供了解工作流程的进展情况。
工作流程完成后,您会在 AWS Glue Data Catalog 中的 dynamodb_exports 数据库下看到两个新表。DynamoDB 快照表名称以 snapshots_ 为前缀。该架构针对 AWS Glue Data Catalog 进行了格式设置(小写和连字符转换为下划线)。您还有一个视图表,其表名称也应用于相同的中 AWS Glue Data Catalog 格式设置,但没有 snapshots_ 前缀。
查询您的数据
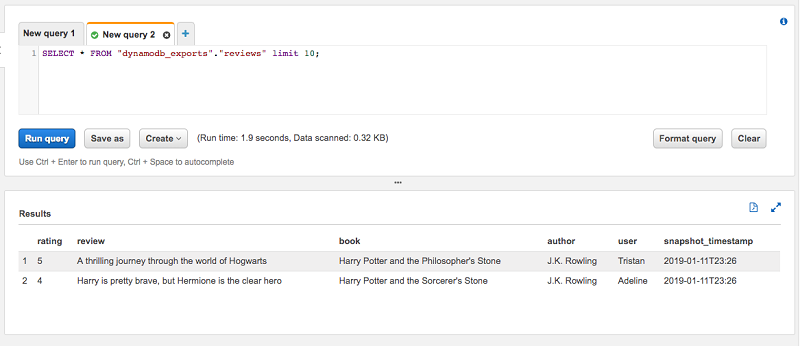
为了展示表最新快照单独视图表的用途,我将使用上一篇博文中的“评论”表。该表包含两个项目。我还会运行两次导出工作流程。正如您在预览表时所看到的,总共有四个项目。那是因为每个快照包含两个项目。
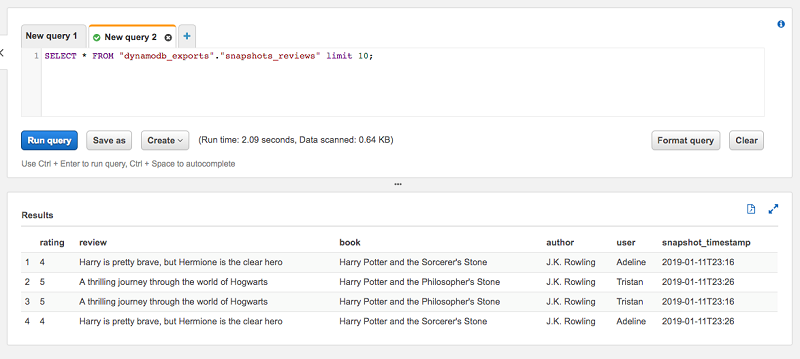
在这些项目中,最新的 snapshot_timestamp 是 2019-01-11T23:26。当我针对视图表评论运行相同的预览查询时,我们看到结果只有两个项目,这符合我们的预期。该视图负责指定 where snapshot_timestamp=… 子句,因此您无需指定。
总结
在本文中,我向您演示了如何使用 AWS Glue 的 DynamoDB 集成和 AWS Step Functions 创建工作流程,将您的 DynamoDB 表数据已 Parquet 格式导出到 S3 中。我还演示了如何为每个表的最新快照创建 Athena 视图,从而为您导出的 DynamoDB 表提供一致的视图。
关于作者
 Joe Feeney 是 Amazon Go 的一名软件工程师,负责一些机密任务,他对此非常满意。他玩《马里奥赛车》特别较真,经常让他的家人很没面子。
Joe Feeney 是 Amazon Go 的一名软件工程师,负责一些机密任务,他对此非常满意。他玩《马里奥赛车》特别较真,经常让他的家人很没面子。