亚马逊AWS官方博客
Drop 如何使用 Amazon EMR for Spark 实现成本减半,并将处理速度提升5.4倍
本文为Drop公司软件工程师Michael Chau与AWS大数据专家解决方案架构师Leonardo Gomez的特约投稿。援引他们的表述,“Drop公司的使命是提高消费者的使用体验,保证每一次使用都能获得奖励。通过Drop的个性化商务平台,我们能够在适当的时间提供正确的品牌选项,帮助会员提高生活质量。在机器学习的支持下,我们将消费者与200多家合作品牌相匹配,借此实现两大核心目标:通过采购获取积分,并将积分兑换为即时奖励。Drop公司位于多伦多,但一直保持着覆盖全球的经营理念,目前已经为北美超过300万会员提供更高级的购物体验。请访问www.joindrop.com以了解更多详细信息。”
内容摘要
在Drop公司,我们的数据湖基础设施是支撑数据驱动的产品及业务决策的重要基础。其中一大关键特性,在于它能够处理大量原始数据并生成符合我们数据湖标准文件格式与分区结构的加工后数据集。正是凭借着这些加工后数据集,我们的商务智能、实验分析与机器学习(ML)系统才有机会发挥作用。
本文将详细介绍我们如何设计并实现数据湖中的批处理ETL管道、如何使用Amazon EMR,以及如何在既有架构的基础上通过多种方式进行迭代。通过不懈的努力,我们得以将Apache Spark的运行时长由数小时缩短至数分钟,并节约了超过50% 的运营成本。
构建管道
Drop的数据湖不仅是企业内整体数据基础设施的中心与单一事实来源,同时也作为下游商务智能、实验分析与机器学习系统发挥作用的前提与基础。我们这套数据湖的职责是从各类来源处摄取大量原始数据,生成可靠的加工后数据集,以供下游系统通过Amazon Simple Storage Service(Amazon S3)进行访问。为此,我们建立起数据湖的批处理ETL管道以遵循Lambda架构处理模型,同时配合Apache Spark与Amazon EMR以将原始数据导入至我们的Amazon S3湖当中,最终将其转换为列式数据集。在这套管道的设计与实施过程中,我们始终遵循以下核心指导原则与注意事项:
- 保证技术栈尽可能简单。
- 使用基础设施即代码。
- 使用瞬态资源。
保证技术栈尽可能简单
我们的目标是使用现有且经过验证的AWS技术,同时配合切实具备重大成效的服务,保证整体技术栈尽可能简单。Drop的业务体系在本质上就是AWS服务的集合,而我们则凭借自身积累下的实践经验将Amazon生态系统带来的最新功能与其他服务中的固有优势相结合,在AWS技术主干的支撑下建立起对全新业务功能的快速原型化能力。
在保持技术栈简单性的努力中,我们还会着力限制由开源Apache Hadoop技术带来的运营成本与复杂性因素。在业务建立之初,我们的工程团队对这些技术的实践经验比较有限,因此我们有意识地进行了取舍,尽可能选择经过验证的全托管服务以减少技术栈中其他元素的比重。我们将Amazon EMR集成为业务数据管道中的组成部分,确保在充分使用相关功能的同时,回避由该服务带来的维护压力。以此为基础,我们即可减少生产集群维护所带来的种种技术性开销。
使用基础设施即代码
我们使用Apache Airflow管理并调度整个数据湖管道的日常运营。在Airflow的帮助下,我们能够通过Airflow有向无环图(DAG)以代码形式构建起完整的工作流程与基础架构。这一关键决策还极大简化了我们的工程开发与部署流程,同时也让我们得以对数据基础架构中的各个层面实现全面的版本控制。
使用瞬态资源
为了降低运营成本,我们还做出一项关键决策,即使用瞬态资源来构建数据处理管道。以这一设计思路为基础,我们的管道将根据运营需求启动必要的EMR集群,并在工作完成后关闭这些集群。我们还可以使用Amazon Elastic Compute Cloud(Amazon EC2)竞价实例与按需实例,尽量减少因闲置资源带来的成本。这种方法大大降低了集群资源浪费所带来的非必要支出。
批处理ETL管道概述
下图所示,为我们的批处理ETL管道架构。

整个管道涵盖以下操作步骤:
- Lambda架构数据模型的一大核心要求,在于同时对批处理与流式数据源进行访问。批处理ETL管道主要使用AWS Database Migration Service(AWS DMS)从我们的Amazon Relational Database Service(Amazon RDS)PostgreSQL数据库中以批量与流式方式摄取数据。管道使用Airflow获取全面的批处理快照,从而实现对AWS DMS任务的全面迁移;同时使用当前正在复制的AWS DMS任务获取流数据,保证以1分钟延迟来实现变更数据捕捉(CDC)。来自批自理与流格式的数据都将被存储在我们的Amazon S3湖内,并通过AWS Glue爬取程序在AWS Glue数据目录中进行分类。
- 批处理ETL管道Apache Airflow DAG将运行一系列任务,首先是将我们Lambda架构Spark应用程序上传至Amazon S3,启动一套EMR集群,最后按照Amazon EMR的操作步骤运行Spark应用程序。根据数据集的具体特性,我们还需要分配必要的Amazon EMR资源以生成加工后数据集。如果希望以Apache Parquet格式生成结果数据集,我们还需要为集群分配充足的CPU与内存资源。
- 在完成所有Amazon EMR步骤之后,集群将被终止,并通过AWS Glue爬取程序对新生产的数据集进行爬取,借此更新数据目录中数据集的元数据。现在,输出数据集已经准备就绪,可供消费者系统通过Amazon S3访问或者使用Amazon Athena/Amazon Redshift Spectrum执行查询。
EMR管道的演进
我们的工程技术团队会对批处理ETL管道的架构进行持续迭代,借此不断降低其运行时间与运营成本。以下几项迭代与功能增强方法,给下游系统以及依赖此管道的最终用户带来极为重大的影响。
从AWS Glue迁移至Amazon EMR
在初次迭代的批处理ETL管道中,我们使用AWS Glue(而非AWS EMR)处理我们的Spark应用程序,这是因为在初始阶段我们的内部Hadoop使用经验还非常有限。凭借着“ETL即服务”与“简化资源分配”等特性,AWS Glue成为初期最理想的解决方案。AWS Glue也不负所望,成功带来了符合预期的结果;但随着我们不断积累到更多Hadoop经验,我们意识到使用Amazon EMR能够进一步改善管道性能并显著降低运营成本。
我们在从AWS Glue向Amazon EMR的迁移中采用无缝化方式,且只需要对EMR集群配置以及使用AWS Glue库的Spark应用程序做出小幅修改。以此为基础,我们获得了下列运营优势:
- 更快的集群引导速度以及更长的资源供应持续时间。我们发现,AWS Glue集群的冷启动需要10到12分钟,而EMR集群的冷启动时长为7到8分钟。
- 在使用同等资源的情况下,EMR集群的运营成本可降低达80%。我们将标准AWS Glue工作节点类型(成本为每DPU-小时 0.44美元)的资源水平,与m5.xlarge Amazon EMR实例类型直接对应起来,后者在使用竞价型实例时每实例每小时使用成本仅为0.085美元。
文件committers
在最初的分区策略当中,我们曾尝试使用Spark的动态写入分区功能来减少每次运行所对应的文件写入数量。具体请参见以下代码:
sparkSession.conf.set(“spark.sql.sources.partitionOverwriteMode”, “dynamic”)
这项策略无法很好地在我们的管道性能中得到体现,这也让我们很快体会到使用云对象存储时所面临的种种局限性及考量因素。为此,我们调整了Spark应用程序的文件写入策略,将其全面覆盖现有目录,并使用Amazon EMR EMRFS S3优化型committer以实现可观的性能提升。在数据集规模接近TB级别的情况下,这款经过优化的文件committer能够将运行时长由数小时减少至半个小时以内!需要强调的是,Amazon EMR 5.30.0中还包含另一项优化,有助于实现动态partitionOverwriteMode。
将Amazon EMR升级至5.28+版本
我们的数据集通常超过数十亿行,因此经常需要将数十万个流文件与大型批处理文件进行比较与处理。在输入数据源确定的前提下,执行此类Spark操作往往会带来极高的数据查询与处理成本。
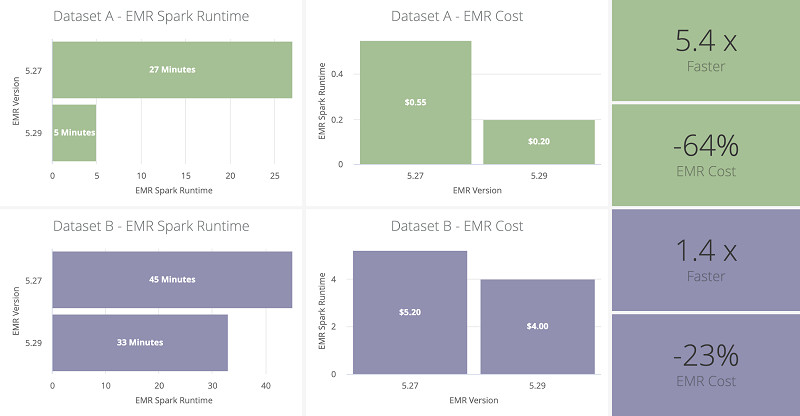
使用Amazon EMR 5.28版本中引入的Amazon EMR runtime for Apache Spark,我们这套管道的整体性能迎来了巨大提升。从Amazon EMR 5.27升级至5.29,无需对现有管道做出任何其他更改,也无需改变任何资源配置,我们的Spark应用程序在总运行时长以及后续Amazon EMR成本方面都降低了超过35%。我们通过两套数据集作为改进测试基准,并通过三轮生产运行对改进效果进行了平均化。
下表总结了基准测试中的各数据集与EMR集群属性。
| 数据库 | 表列数 | 总批处理文件大小 | 总流式文件大小 | 流式文件数量 | EC2实例类型 | EC2实例数量 |
| 数据库A | 约350万 | 约0.5 GB | 约0.2 GB | 约10万个 | m5.xlarge | 10个 |
| 数据库B | 约35亿 | 约500 GB | 约120 GB | 约25万个 | r5.2xlarge | 30个 |
下图所示,为Amazon EMR升级带来的性能基准与指标改善。在计算成本指标时,我们使用了包括Amazon EMR集群引导与资源供应时间在内的多项时间因素。
Amazon EMR步骤并发
在对管道架构进行早期迭代时,我们需要为每套数据集创建一个新的批处理ETL管道,外加与该数据集相匹配的专用EMR集群。为了快速简便地扩展处理能力,我们选择以克隆形式生成新管道。由于我们以基础设施即代码形式编写各管道,且操作与资源分别独立存在,因此为数据集快速生成新管道不算什么难事。但在这里,仍有不少对运营进行改进的空间。
以下截屏所示,为Drop的批处理ETL处理DAG。所有集群均以Drop工程技术团队成员的宠物命名。

管道架构的演进,要求我们根据不同数据集对于Amazon EMR的资源需求对这些数据集进行分组,同时使用Amazon EMR步骤并发机制在公共EMR集群内将它们作为Spark应用程序的Amazon EMR步骤进行并发运行。在以这种方式重构批处理ETL管道之后,我们可以执行以下操作:
- 删除各数据集上单一EMR集群内所关联的EMR集群,借此减少引导与置备时间。
- 在总体上缩短Spark运行时长。
- 使用更少的EMR集群以简化我们的Amazon EMR资源配置。
平均而言,我们的集群在竞价型实例上需要8到10分钟即可完成引导并开始接收请求。通过将多个Spark应用程序迁移至同一公共EMR集群,我们消除了这一瓶颈,并最终降低了总体运行时长与Amazon EMR运营成本。Amazon EMR步骤并发机制还使我们得以通过更少的资源运行更多应用程序。对于体量较小的数据集(1500万行以下),我们发现同时运行多个Spark应用程序并配合更低的资源容量并不会对整体运行时间产生线性影响;而且与以往的架构相比,资源量的减少反而能够带来更短的运行时间。但在运行并发Amazon EMR步骤时,较大的数据集(超过10亿行)并不能延续这种性能提升或收益。因此对于对应较大表的EMR集群,我们仍然需要为其提供更多资源且减少并发步骤。但与原有架构相比,总体来看新的管道体系在成本与运行时间方面仍然更胜一筹。
Amazon EMR实例fleet
通过使用Amazon EMR与Amazon EC2竞价实例,我们虽然能够节约大量成本,但却有可能在EMR集群的可靠性方面有所妥协。由于竞价型实例的供应限制,由此建立的集群往往可用性较差。随时可能出现的节点丢失会带来更长的EMR集群资源供应周期以及更长的Spark运行时间,并直接导致管道出现总体性能下降。
为了提高管道可靠性并预防这些风险,我们开始使用Amazon EMR实例fleet。实例fleet能够有效克服两大难题:通过指定特定EC2竞价实例类型,限制Amazon EMR集群使用的具体实例类型;此外,如果预配置的竞价实例在运行时长方面超过指定的阈值,则将其自动切换为按需实例。在使用实例fleet之前,由于统一组内对实例类型多样化的限制,约有15%的Amazon EMR生产业务会受到竞价实例可用性问题的影响。但在使用实例fleet后,问题彻底消除,而且再也没有出现过集群故障或者超出计划阈值的长时间资源调配问题。
总结
Amazon EMR帮助Drop公司充分发挥数据资产的力量,据此做出更明智的产品与业务决策。我们使用Amazon EMR功能改善数据处理管道的整体性能与成本效率,借此获得了巨大的商业成功,这又反过来敦促我们持续探索管道改进的新方法。最终,我们意识到只有与最新AWS技术以及Amazon EMR功能保持同步,才能不断将业务系统的运营效率提升至新的高点。