亚马逊AWS官方博客
Annalect 如何使用 Amazon Redshift 构建事件日志数据分析解决方案
Original URL:https://thinkwithwp.com/blogs/big-data/how-annalect-built-an-event-log-data-analytics-solution-using-amazon-redshift/
以近乎实时的方式将事件日志数据提取到数据仓库并进行分析,是一件极具挑战的事情。数据的提取必须快速、高效。数据仓库必须能够快速扩展以处理传入的数据量。在数据仓库中存储海量不频繁访问的历史数据,会带来难以接受的高成本。而如果将不频繁访问的数据存储在数据仓库之外,加载时间又令人无法接受。
在 Annalect,我们找到了将鱼和熊掌兼而得之的方法。在本文中,我们将介绍如何在 AWS 上构建一个解决方案,以管理、增强和分析来自我们广告技术合作伙伴的事件日志数据。我们使用 Amazon S3 作为存储,使用 Amazon EC2 和 AWS Batch 进行计算,使用AWS Glue Data Catalog、Amazon Redshift 以及 Amazon Redshift Spectrum 进行分析。该架构高度可扩展、按需分配底层基础设施,被证明是面向我们数据分析用户的高性能、高性价比的解决方案。
架构概览
2016 年中,我们当时借助 Amazon RedShift 和本地表来提供事件级广告技术数据集的 SQL 访问,从而帮助分析师和建模人员改进广告购买策略。我们保存选定数据源六个月内的历史数据,这相当于大约 2300 亿个事件。到 2017 年初,此数据集膨胀至超过 3850 亿个事件,为此我们增加了 Amazon Redshift 的规模以满足要求。着眼未来,我们希望能够支持更多数据,不管是历史数据的丰富度还是数据源种类。与此同时,我们希望能够保持或提高查询性能,但最好能够不增加成本。
由于我们当时已经在使用 Amazon Redshift 作为我们的数据仓库,因此我们特意考察了下 Redshift Spectrum。Redshift Spectrum 是 Amazon Redshift 的一个功能特性,可以直接查询存储在 Amazon S3 中的数据。它使用与 Amazon Redshift 相同的 SQL 功能,但不需要将数据加载到存储在 Amazon Redshift 集群中的磁盘上的 Amazon Redshift 表中。
借助 Redshift Spectrum,表的存储与集群的计算资源分开,从而让两者都可以独立扩展。我们可以在 S3 中保存大型数据表,而非在本地 Amazon Redshift 存储中保存,从而减少了 Amazon Redshift 集群的规模,降低了成本。使用外部 Redshift Spectrum 表的查询借助 Redshift Spectrum 的计算资源(独立于 Amazon Redshift 集群)来扫描 S3 中的数据。AWS 根据扫描的数据量,对查询实行分级计价的收费政策。为确保查询效率,我们使用 AWS Batch 将 S3 中存储的数据转换为 Parquet 格式的文件。
结果是我们建立了一个十分高效、基本上无服务器的分析环境,在此环境中,数据始终可通过 Redshift Spectrum 进行查询。虽然我们仍然管理了一些始终在运行的 Amazon Redshift 集群,但我们认为整体架构“基本上是无服务器的”。这是因为,与我们通过 Redshift Spectrum 进行分析以及通过 AWS Batch 进行数据准备而使用的计算能力相比,这个始终运行的集群的规模极小。
Amazon Redshift 集群专用于为分析师执行分析任务,分析师不再需要花费时间加载作业。这是因为不再需要花费时间将数据拷贝到 Amazon Redshift 中的本地表,同时数据准备工作是在 Amazon Redshift 之外完成的。
借助 Redshift Spectrum 的革命性发展,加上表数据存储在 S3 中,到 2018 年初,我们向分析师交付的数据量提高了一个量级。同时我们的成本仍然维持在 2017 年的水平。使用 Redshift Spectrum 为我们节约了大量的成本。现在,我们可以为更多数据源保存最长 36 个月的历史数据,也就是数万亿个事件。
我们的数据管理基础设施称为增强事件级数据环境 (EELDE),采用了如下所示的架构。
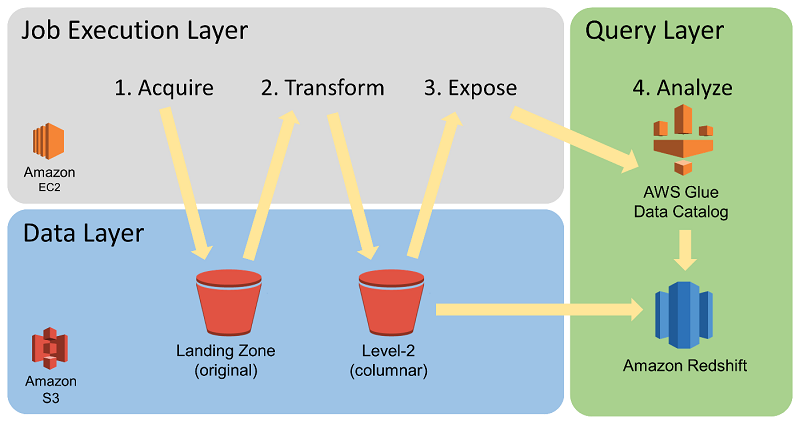
EELDE 主要提供了四种功能:
- 数据提取
- 数据转换
- 计算密集型增强
- 分析师即席查询环境
下文详细介绍这四种功能。
数据提取
数据提取系统的架构确保了顺畅、快速的下游数据可用性。我们充分考虑了供应商数据源在源内容本身以及不同供应商数据推送习惯方面的固有不一致问题。此外,我们还考虑了数据供应商可能在给定时间传送大量数据文件的问题。下图显示了我们的数据提取过程。

我们在 Amazon S3 中建立了两个存储区域,用来初始保存来自我们供应商的数据。其中着陆区作为一个存储库,用于长期存储未经修改的原始历史日志文件。我们从供应商那里直接提取的日志文件将立即存储于着陆区。数据源存储区用于临时存放供应商推送的日志文件。在我们将数据提取到着陆区时,我们会按照供应商整理和安排传送到数据源存储区的数据文件。
提取过程在 EELDE 的作业执行层执行,作业执行层会自动扩展,可以并行处理多个数据文件。这确保了数据处理和可用性不会因数据量的突增而被延迟。一些突增可能是因需要填充来自新供应商的大型数据集所致。另一些突增可能是由于供应商在发生延迟后一次性传送了积压的大量日志。
供应商日志不论是来自推送还是拉取,我们都会监控着陆区。我们会在发现可能影响下游分析的文件格式变化或数据缺口时发出提醒。我们发现,这种架构和流程为我们提供了必要的控制力、灵活性和敏捷性,从而可以快速响应任何规模的数据量以及数据的任何变化。
数据转换
EELDE 能够以计算高效和成本高效的方式处理、增强和分析大量的事件数据。实现这种能力的一个重要原因,是我们在着陆区对文件进行了初步转换。EELDE 的作业执行层利用 AWS Batch 对原始源数据执行计算密集型的数据转换。这种数据一般为逗号分隔值 (CSV) 或 JSON 格式。AWS Batch 会将它并行转换为列式压缩存储格式,即 Apache Parquet。在下图中,您可以看到 Parquet 存储位置的标签为“Level 2 (columnar)”存储桶。
对于我们的 Parquet 转换作业,我们非常熟悉使用 AWS Batch 运行多个采用本地模式 Apache Spark 的容器。我们的目标是支持高吞吐量的文件转换,每个文件的大小从几 MB 到几 GB 不等。一次 Parquet 转换可能需要数秒到 30 分钟不等的时间。
AWS Batch 提供了资源隔离和作业管理功能,能够直接运行数百个独立的数据转换作业。此外,它也消除了在 Amazon EMR 中同时运行多个任务的一些挑战。而对于更大型的数据集,EMR 可以为每个作业所提供的并行计算能力,更有吸引力。
下图显示了数据转换和分类过程。

我们按照日期将 Parquet 格式存储的大型事件数据表进行分区。按照日期对数据进行分区非常重要,它提供了一种高效的方式来访问给定分析处理所需要的数据,从而优化了查询成本和查询性能。将文件转换为 Parquet 格式后,它们将作为 AWS Glue Data Catalog 中的表分区暴露。虽然数据存储格式进行了转换,但数据仍然保留了所有原始字段,这对于支持即席分析十分重要。
一旦完成了Parquet 转换和 AWS Glue Data Catalog 管理过程,就可以使用 Redshift Spectrum 通过 SQL 查询访问数据。Redshift Spectrum 使用 AWS Glue Data Catalog 来引用存储在 S3 中的外部表,从而让您可以通过 Amazon Redshift 集群查询这些表。借助 Parquet 等列式存储格式,提高了使用 Redshift Spectrum 执行查询的速度和性价比。
计算密集型增强
在执行分析作业前,作业执行层还可能会运行其他计算密集型的数据转换,从而增强日志,以支持更多高级类型的分析。事件级日志合并和事件属性增强就是两个例子。
虽然这些增强任务可能有不同的计算要求,但都可以使用 Redshift Spectrum 来收集相关的数据集,然后在作业执行层中处理。结果也同样通过 Redshift Spectrum 对外可见。这样就能够以较低的成本,在可接受的时间内完成大型数据集的复杂增强任务。
分析师即席查询环境
我们的环境为分析师提供了完成关键分析所需的数据集和 SQL 查询环境。在 EELDE 中,数据按照广告技术供应商和系统的坐席或账户作为独立的外部 schema 组织。来自广告公司的分析师和数据学家根据项目需求获得特定 schema 访问权限。
通过在一个平台上访问不同的数据集,分析师可以获得无法通过分析独立孤岛中的数据所能获得的独有见解。他们可以组合利用源供应商创建新数据集,从而在特定的分析项目中使用,同时满足数据隔离要求。这样有利于支持预测性建模、渠道规划和多来源归因等应用场景。
保持低成本的最佳实践
在此过程中,我们开发了一些适用于 Redshift Spectrum 的最佳实践:
- 使用压缩列式格式。 我们将 Apache Parquet 用于大型事件级表。这样可以减少查询运行时间,降低数据扫描成本和存储成本。我们的大型表一般拥有 40–200 列,而大多数查询一次仅使用 4–8 列。与非列式格式相比,使用 Parquet 通常可以将扫描成本降低 90% 以上。
- 分区表。 我们按照日期对大型事件级表进行分区,然后培训用户在 WHERE 条件语句中使用分区列。这样实现的成本节约与查询所使用的日期比例成正比。例如,假设我们暴露六个月的数据,但某个查询仅涉及一个月的数据。则在此例中,通过使用适当的 WHERE 条件语句可将查询的成本降低六分之五。
- 主动管理表分区。 虽然我们以 Parquet 文件的方式存储了最多 36 个月的历史数据,但默认情况下我们仅以外部表分区的形式暴露最近 6 个月的数据。这样就降低了用户筛选分区列失败时的查询成本。如果用户请求,我们会临时将较早日期的分区添加到必要的表中,以支持需要超过 6 个月数据的查询。这样,我们就可以在需要时支持更长的时间窗。此外,我们通常不会暴露超过正常所需数量的数据,从而保持了较低的成本限制。
- 必要时将外部表迁移到 Amazon Redshift 中。 如果大量查询重复触及同一个外部表,我们往往会在 Amazon Redshift 中创建一个临时的本地表以用于查询。根据查询的数量及其范围,一个不错的办法是将数据加载到具有恰当分配键和筛选键的本地 Amazon Redshift 表中。这样可以消除重复的 Redshift Spectrum 扫描成本。
- 使用 spectrum_scan_size_mb WLM 规则。 通过在在默认 WLM 队列上设置 spectrum_scan_size_mb WLM 规则,大多数用户和作业的有效 Redshift Spectrum 数据扫描限制都为 1TB。对于单次分析或建模查询,需要超出此限制的情况极为罕见。
- 在必要时增加集群以提高并发处理能力。多个 Amazon Redshift 集群可以访问 S3 中的同一个外部表。如果许多用户同时运行针对外部表的查询,则我们可以选择增加更多的集群。借助 Redshift Spectrum 以及我们为我们的环境创建的管理工具,可以轻松完成此任务。
- 使用短期性 Amazon Redshift 集群。 对于某些计划的生产作业,我们使用短期性的 Amazon Redshift 集群,并通过外部 schema 提供必要的数据。借助 Redshift Spectrum 可以避免漫长的数据加载时间,从而可以做到在数小时内启动一个 Amazon Redshift 集群,然后每天终止它。与为项目配备始终运行的集群相比,这样可以节约 80-90% 的成本。同时它还避免了与其他查询活动的竞争,因为短期性集群专用于该项目。
小结
通过建立使用 Amazon S3 进行存储以及使用 Redshift Spectrum 进行分析的数据仓库策略,我们将支持的数据集规模提高了一个量级。此外,我们提高了快速提取大量数据、同时保持快速性能并且不增加成本的能力。现在,我们的分析师和建模人员可以执行更深入的分析以完善广告购买战略和结果。
其他阅读资源
如果您认为此博文有帮助,请务必读一读 Using Amazon Redshift Spectrum, Amazon Athena, and AWS Glue with Node.js in Production 和 How I built a data warehouse using Amazon Redshift and AWS services in record time。
关于作者
 Eric Kamm 是 Annalect 的高级工程师和架构师。过去二十年来,他长期从事大型 ETL 工作流的创建和管理工作,为分析师和建模人员团队提供数据和计算环境。他热爱云技术,因为它们可以加快项目规划和实施的速度,同时提高可靠性和运营效率。
Eric Kamm 是 Annalect 的高级工程师和架构师。过去二十年来,他长期从事大型 ETL 工作流的创建和管理工作,为分析师和建模人员团队提供数据和计算环境。他热爱云技术,因为它们可以加快项目规划和实施的速度,同时提高可靠性和运营效率。