亚马逊AWS官方博客
开始在 Amazon Web Services 上使用 R
本博文由 Summit Consulting 的主管数据科学家 David Kretch 特约发表。
随着 R 工作负载增加且消耗的资源越来越多,出于成本、速度和弹性原因,从本地计算环境迁移到 Amazon Web Services (AWS) 上可扩展的完全托管型云服务成为极其宝贵的能力。在这个包含两部分的博文系列中,第一部分将讨论 R 的基本知识和 AWS 上 R 的常见工作负载对。在第二部分“使用 R 和 Amazon Web Services 进行文档分析”中,我们将深入探讨如何使用 AWS 服务构建端到端文档处理应用程序。
R 的背景
R 是统计员、科学家和数据分析师常用的编程语言。它的大型用户社区已开发出数千个可免费使用的软件包,包括用于数据操作、数据可视化、专门的统计估算程序、机器学习,访问美国人口普查数据或 Spotify 等公共数据 API、轻松开发基于数据的 Web 应用程序等很多其他领域的软件包。同时还提供说明如何有效使用 R 的高质量免费在线手册和其他文档。
R 生态系统中其中一个最常见的软件包集为 Tidyverse,它是转换和使用“有序”数据的库集合。它们旨在让用户能够以数据接收时的任何形式(例如 CSV、API 等)提取数据,并使用数据操作的声明性“语法”将数据轻松转换为分析所需的形状。Tidyverse 非常适合大量数据分析任务,它在 R 持续广受欢迎中起到重要作用。
R 生态系统的另一个重要部分是开发环境 RStudio。RStudio 设计用于数据科学。除了提供编辑器和调试器之外,RStudio 还可让用户使用内置的数据查看器查看内存数据结构,该数据查看器可让我们像电子表格一样排序和筛选、查看我们制作的任何图表、查看我们的数据库连接等等。IDE 背后的公司(也称为 RStudio)赞助了很多 R 开发项目(包括 Tidyverse)、举办了很多会议,并且提供了 R 服务器软件的免费和付费版本,包括将 R 应用程序作为 Web 应用程序托管的软件。
AWS 上的 R 的使用案例
大数据处理
随着数据分析朝着更大的数据集发展,过去可能习惯于在笔记本电脑上运行本地分析的 R 用户将因为计算、内存和成本限制而遇到障碍。通过将工作流移动到 AWS,R 用户可以克服这些障碍。R 通常用于估算需要大量计算能力和时间(数小时甚至数天)来构建的复杂统计模型。使用根据工作负载定制的 Amazon Elastic Compute Cloud (Amazon EC2) 实例或者 Amazon Elastic Kubernetes Service (Amazon EKS)、Amazon Elastic Container Service (Amazon ECS)、AWS Fargate 或 AWS Batch 上运行的容器,AWS 托管型计算服务可以帮助加快模型开发。
对于大数据问题,R 可能会受到本地可用内存的限制;内存增强型实例类型可为此提供帮助。默认情况下,R 会处理内存中的数据,因此,使用具有更多内存的实例会使问题易于解决,而无需对代码进行更改。很多问题也会并行存在,在 R 对并行处理的支持下,修改代码以使用 R 的并行处理软件包可使用户利用具有大量核心的实例类型。开发人员可以在 AWS 的 R 类型(内存优化型)和 C 类型(计算优化型)实例之间选择一种与您计算和内存工作负载需求密切匹配的实例类型。
通常,数据科学家只是在部分时间处理这些大问题,运行永久性 Amazon EC2 实例或容器不会产生成本效益。AWS Batch 非常适合这些工作负载类型,它将负责启动实例、运行作业,然后在作业完成时关闭实例。由于您只需在实例运行时付费,当您没有积极使用实例时,您不必为强大的机器付费,并且也不受固定、静态的处理能力限制。
数据库
数据库是数据科学团队的宝贵资源;它们为数据集提供单一的真实数据来源,并且提供很高的读取和写入性能。我们可以通过 Amazon Relational Database Service (Amazon RDS) 利用 PostgreSQL 等常见数据库,同时让 AWS 负责底层实例和数据库维护。很多情况下,R 只需少许修改即可与这些服务交互;R 内的 Tidyverse 软件包可使您编写代码,无论它将在哪里运行,并且还能使您重新定义代码,以对来源于数据库的数据执行操作。
文件存储
最后,Amazon Simple Storage Service (Amazon S3) 可使开发人员存储原始输入文件、结果、报告、构件和不想要直接存储在数据库中的任何其他内容。存储在 S3 中的项目可在线访问,使得与协作者分享资源变得容易,但它还提供精细的资源权限,从而仅限那些应当拥有它的人访问。
在 R 中开始使用 AWS
要在 R 中使用 AWS,您可以使用 Paws AWS 软件开发工具包,它是我的同事 Adam Banker 和我一起开发的 R 软件包。Paws 是非正式开发工具包,但它涵盖了与其他语言正式开发工具包相同的大多数功能。您还可以通过 botor 和 reticulate 软件包使用正式的 Python 开发工具包 boto3,但您需要在使用它们之前确保 Python 已安装在您的计算机上。
接下来,我们来讨论如何通过 Paws 软件包使用 AWS。
要安装 Paws,请在 R 中运行以下命令:
要使用 AWS 服务,您可以创建一个客户端并从该客户端访问服务的操作:
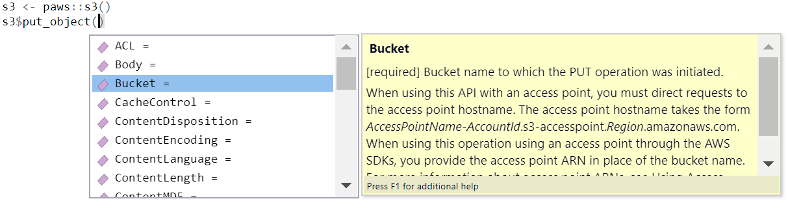
如果您使用 RStudio,其工具提示将向您显示可用的服务、每个服务的操作,并为每个操作显示各个参数的相关文档。下面是可用于 S3 的 put_object 操作的工具提示示例:
您在访问 AWS API 时必须提供凭证和区域。Paws 将使用 AWS 身份验证链搜索凭证和区域:
- 显式提供的访问密钥、密钥、会话令牌、配置文件和/或区域
- R 环境变量
- 操作系统环境变量
.aws/credentials和.aws/config中 AWS 共享的凭证和配置文件- 容器 AWS Identity and Access Management (IAM) 角色
- 实例 IAM 角色
例如,如果您在 Amazon EC2 实例或附加有 IAM 角色的容器中运行 R 和 Paws,Paws 将自动获取 IAM 角色凭证来对 AWS API 请求进行身份验证;此功能部分在 AWS 开源计划的支持下开发。
我们可以通过使用如下环境变量为所有服务显式设置 AWS 凭证和区域:
如果您需要为每个服务提供单独的凭证,您可以在为给定服务创建客户端时执行此操作。例如,如果您通过临时安全凭证使用另一个账户的 S3 存储桶,您可以将它们提供给 S3 客户端,如下所示:
您可以在 Paws 凭证文档中找到有关 AWS 凭证和 Paws 配置的更多详细信息。此外,遵照 AWS 保护 AWS 凭证的建议,包括:不要将密钥嵌入代码中,为不同应用程序使用不同的访问密钥。
连接到数据库
您可以通过设置到数据库的连接来在 R 中使用数据库。然后,您可以引用数据库中的表格,就好像它们是 R 中的数据集一样。此功能由 Tidyverse 中的 dplyr 软件包和 dbplyr 数据库后端提供。
如果您使用适当配置的 RDS 数据库,您可以使用 RDS 服务中的 Paws build_auth_token 函数生成的令牌进行身份验证;该功能是在 AWS 开源计划支持下开发的另一项功能。通过使用 IAM 身份验证令牌,您无需存储密码。一旦连接,您可以像以前一样使用此数据库连接。
使用这些软件包,您可以从 R 内轻松利用运行在 AWS 上的 AWS 资源和数据库。
在第 2 部分“使用 R 和 Amazon Web Services 进行文档分析”中,我们将向您演示如何通过在 AWS 上利用服务来使用这些软件包构建数据工作流,以将 PDF 转换为我们可以使用的数据。

David Kretch
David Kretch 是 Summit Consulting 的主管数据科学家,他为联邦政府和私人企业客户构建了数据分析系统和软件。他还和 Adam Banker 共同编写了 Paws,R 编程语言的 AWS 开发工具包。Adam Banker 是 Smylen 的全堆栈开发人员,对本文也有贡献。
本博文中的内容和意见属于第三方作者,AWS 不对本博文的内容或准确性负责。
精选图片来自 Pixabay。