亚马逊AWS官方博客
Amazon Athena 中调用 Amazon Lambda 实现的 UDF 进行数据解密的效率分析
背景介绍
对企业数据进行在线分析是数据分析的重要手段,借助 Amazon Athena 可以使用标准 SQL 直接查询分析存储于 Amazon S3 中的数据,使分析更加便捷。另一方面,数据安全和个人信息保护法的出台,使得企业必须需考虑对个人信息 PII(Personally Identifiable Information)等敏感信息的保护,通过对敏感数据加密或去标识化以及合理的授权来确保敏感数据的使用安全。
在 Athena 中,可以通过 Athena 调用用户自定义函数 UDF 对敏感 PII 数据进行加解密。Athena 虽然来源于 Trino 和 Presto,但是其本身并不支持内置的自定义函数,而是将这些功能外置到 Amazon Lambda 中。这样,可以通过合理授权 Lambda,使得有相应 Lambda 权限的用户可以在 SQL 中调用 UDF 进行解密,查看明文信息,而其他没有权限的用户只能查看加密后的信息,来保护敏感信息的安全。
Athena UDF 执行效率分析
由于 Amazon Athena 和 Amazon Lambda 都运行在亚马逊云科技自己管理的 VPC 中,因此在 Athena 中调用外置的基于 Lambda 的 UDF 进行解密时,待解密字段的内容需要通过网络传输给 Lambda,并接受返回的解密字段。如下图所示:带有 UDF 的 Athena SQL 的执行效率受多方因素的影响,包括数据存储格式和分区,Athena SQL 本身的查询效率,Athena 传输给 Lambda 的数据量,Lambda 并发数量以及 Lamba 本身的执行效率。

上述的这些因素相互依存,相互影响,例如:数据在 S3 中优化的存储格式和数据分布,会提升 Athena SQL 数据扫描和查询的执行效率,但是可能会降低 Lambda 的并发效率,从而导致整体 SQL 效率降低。某些情况下,Lambda 可以通过提高内存的方式提升一定的执行效率,但要防止过度配置。Lambda 本身执行效率可以通过覆写 UserDefinedFunctionHandler 中的 processRows 方法,直接处理 Arrow data,减少对象拷贝。本文中,我们通过对不同条件下的查询效率进行比较分析,希望对其中的机理有更加深刻的认识。
测试数据准备
在本文中,我们会基于亚马逊产品评论数据集,在亚马逊云科技中国宁夏区域创建不同的数据集。为了方便比较测试,我们首先会基于该数据集,准备不同存储方式的包含有待解密字段的源数据。通过在 Athena 中运行相同的 SQL 进行查询分析效率比较。为了构建这些具有加密字段的源数据,我们通过执行 Athena 中的 CTAS(Create Table as Select)语句通过直接调用 UDF 中 Lambda 的加密函数,进行转换存储。如下图所示:
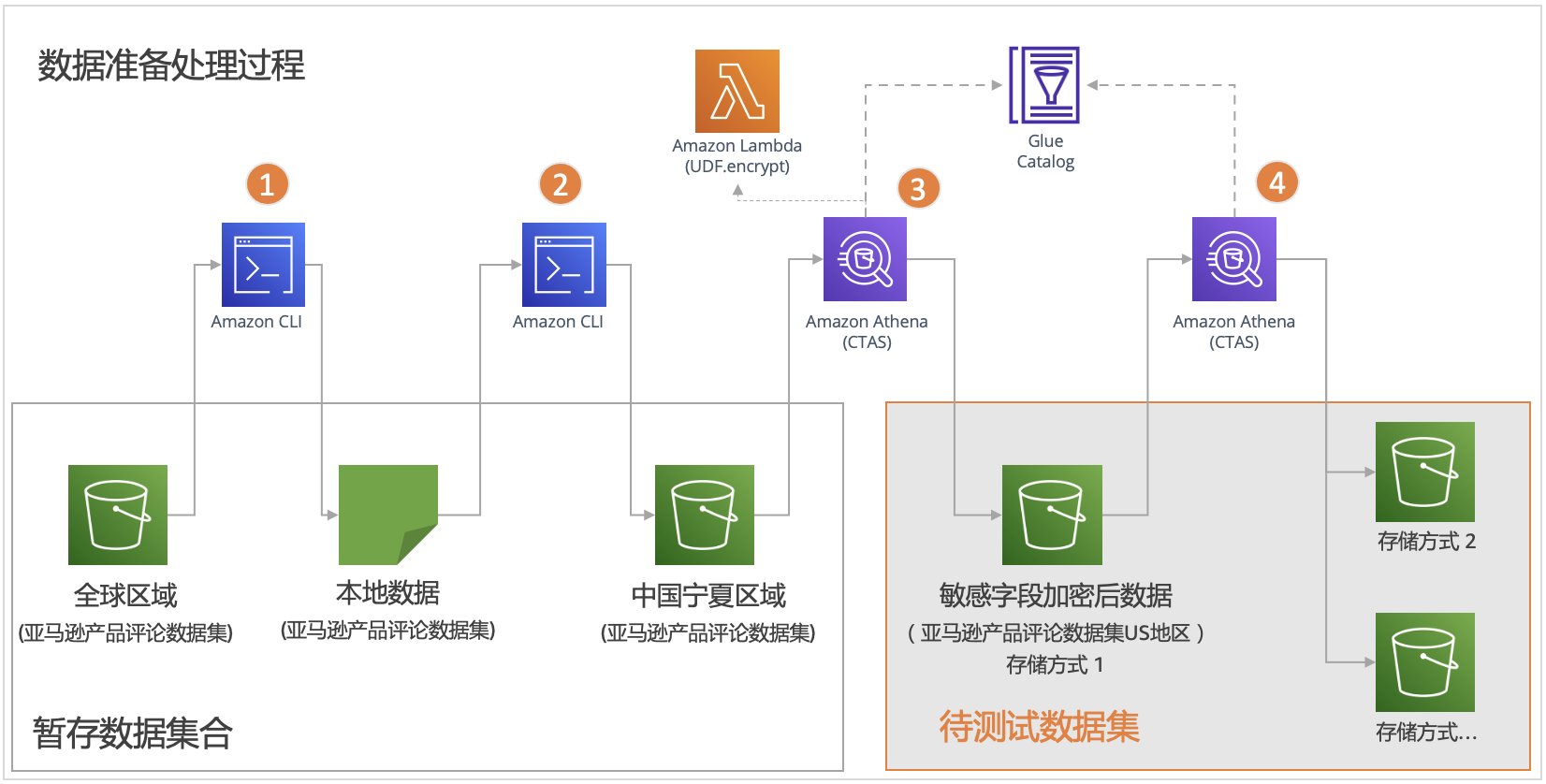
整个数据准备的过程为:
- 将来自于 Global 区域的亚马逊产品评论数据集,通过 aws cli 命令从存储桶
s3://amazon-reviews-pds/tsv下载到本地。 - 将本地的数据通过 aws cli 上传到宁夏区域的存储桶中,通过在 Athena 中运行 DDL SQL 语句在 Glue Data Catalog 中建立相应的数据表。
- 部署 UDF Lambda 函数,并在 Athena SQL 中调用 encrypt 函数,通过 CTAS 语句对字段进行加密后存储,作为新的数据表。
- 对拥有加密字段的数据表,再次通过 Athena 的 CTAS 语句,以指定的格式创建其他的数据表。这些数据表会作为我们测试的基准数据。
原始数据下载和上传
本实验中的测试数据集为亚马逊产品评论数据集,该数据集提供了自 1995 年以来超过 1.55 亿条客户评论数据。 数据的具体格式可以参考:https://s3.amazonaws.com/amazon-reviews-pds/readme.html。 该评论数据集存储在亚马逊云科技的全球区域,我们需要把这些数据拷贝到亚马逊云科技中国区的宁夏区域。
我们首先通过 aws cli 命令将来自于 Global 区域的数据集从存储桶 s3://amazon-reviews-pds/tsv 下载到本地。假设这里用的 Profile 为 global-admin,文件存储格式为 TSV(Tab Separated Values)格式。
在亚马逊云科技中国宁夏区域创建新存储桶 s3://athena-udf-test-bucket-zhanla 来存储实验数据,运行 aws cli 命令,将下载的文件上载到该存储桶的 tsv 文件夹中。假设这里用的 Profile 为 china-admin:
构造并部署 Lambda 作为 Athena 的 UDF
Athena 只支持 Scalar UDF,其对应的 Lambda 函数支持 Java 8 或者 Java 11 的运行时环境。UDF 对应的 Lambda 中的 Handler 需要继承 UserDefinedFunctionHandler,才可以被 Athena 调用。而且,UDF 方法按要求必须全部小写。
我们部署新的 Lambda athena-udf-aes。此函数可以进行 aes 加解密的,拥有两个方法,encrypt 对数据进行加密,decrypt 对数据进行解密,这两个函数都有两个参数,分别为要加密或者解密的内容以及密钥本身。在整个数据准备的过程中,为了不影响实验的主旨,我们暂不考虑数据加解密过程中密钥的安全性,因而在 SQL 中直接传入密钥给 UDF 的 Lambda 函数。实际环境中,密钥可以通过 Lambda 访问 Secrete Manager 或者 Parameter Store 直接获得,以避免密钥泄漏。我们实验的 UDF Lambda 代码如下:
通过 maven 编译后即可部署 Lambda 到中国区宁夏区域,以下为编译上述 java 代码的 pom.xml 文件,其中 aws-athena-federation-sdk.version 的版本号为 2021.33.1,在实际编译中,可能需要根据实际情况进行修改,保证该版本号在 maven 库中存在 https://mvnrepository.com/artifact/com.amazonaws/aws-athena-federation-sdk。
数据预处理
数据预处理的整个执行过程,可以参考如下架构图。我们首先从存储于 S3 中的 TSV 格式的源数据定义表 product_review_tsv,通过 Athena 中的 CTAS(Create Table as Select)语句选择表 product_review_tsv 中的“Marketplace=US”的数据转化为 Parquet 格式的存储表 parquet_us。在这个过程中,我们假设字段“review_headline”为敏感字段,通过调用 UDF 中的 encrypt 函数对该字段 review_headline 进行加密,并生成新的数据字段 review_headline_encrypted,这样测试表 parquet_us 中就包含了待解密字段。此后,我们会基于此表,根据 Partition 和 bucketing 设置的不同,生成其他的数据表,作为本次比较测试中的统一数据源。在 Amazon Athena 中运行同样的 SQL 查询语句进行查询,并对字段进行解密,来比较这些不同存储条件下 SQL 的运行效率。

按照上图的准备过程,我们会得到如下的测试数据表,其数据存储都为 parquest 格式,压缩方式为 SNAPPY,但是数据存储的分区和 Bucketing 设置不同。
| 序号 | 表名 | 存储格式 | 压缩格式 | 分区 Partition |
分桶 Bucketing |
bucket_count |
| “1.0” | parquet_us | review_headline |
review_headline_encrypted |
无 | 无 | 无 |
| 1.1 | parquet_us_partition_year | review_headline |
review_headline_encrypted |
year | 无 | 无 |
| 1.2 | parquet_us_partition_year_bucketed_prodid_xxl | review_headline |
review_headline_encrypted |
year | product_id | 1 |
| 1.3 | parquet_us_partition_year_bucketed_prodid_xl | review_headline |
review_headline_encrypted |
year | product_id | 2 |
| 1.4 | parquet_us_partition_year_bucketed_prodid_l | review_headline |
review_headline_encrypted |
year | product_id | 5 |
| 1.5 | parquet_us_partition_year_bucketed_prodid_m | review_headline |
review_headline_encrypted |
year | product_id | 10 |
| 1.6 | parquet_us_partition_year_bucketed_prodid_s | review_headline |
review_headline_encrypted |
year | product_id | 30 |
首先,在 Athena 的 SQL 编辑器中运行如下语句,从而在 Glue Data Catalog 中生成数据库 product_review,同时,基于存储桶 s3://athena-udf-test-bucket-zhanla/tsv 中的数据,创建表 product_reviews_tsv。
接下来,如下所示,我们基于表 product_reviews_tsv 创建表 parquet_us,并存储于 s3://athena-udf-test-bucket-zhanla/parquet-us/中。该过程将数据格式从 tsv 格式转换到 parquest 格式(只选取 marketplace = ‘US’的数据),并通过 SNAPPY 算法进行了压缩。
运行如下语句,基于表 parquet_us 创建新表 parquet_us_partition_year,并在创建的过程中,指定分区键 year。
类似地,我们基于表 parquet_us 创建表 parquet_us_partition_year_bucketed_prodid_xxl。在创建的过程中,指定分区键 year,同时指定 Bucketing 字段 product_id,且 bucket_count 为 1。
综上,采用类似的方法,我们创建 7 个表,根据设定的 bucket_count 不同,所得到的 year=2015 分区中的数据文件大小也不同,如下表所示:
| 序号 | 表名 | 存储路径 | 分区 Partition |
分桶 Bucketing |
bucket_count | 被查询Bucket中文件 平均大小 (year=2015) |
| “1.0” | parquet_us | s3://athena-udf-test-bucket-zhanla-us-east-1/parquet-us/ | 无 | 无 | 无 | 1.8G |
| 1.1 | parquet_us_partition_year | s3://athena-udf-test-bucket-zhanla-us-east-1/parquet-us-partition-year/ | year | 无 | 无 | 350M |
| 1.2 | parquet_us_partition_year_bucketed_prodid_xxl | s3://athena-udf-test-bucket-zhanla-us-east-1/parquet-us-partition-year-bucketed-prodid-xxl/ | year | product_id | 1 | 5.2G |
| 1.3 | parquet_us_partition_year_bucketed_prodid_xl | s3://athena-udf-test-bucket-zhanla-us-east-1/parquet-us-partition-year-bucketed-prodid-xl/ | year | product_id | 2 | 2.1G |
| 1.4 | parquet_us_partition_year_bucketed_prodid_l | s3://athena-udf-test-bucket-zhanla-us-east-1/parquet-us-partition-year-bucketed-prodid-l/ | year | product_id | 5 | 1G |
| 1.5 | parquet_us_partition_year_bucketed_prodid_m | s3://athena-udf-test-bucket-zhanla-us-east-1/parquet-us-partition-year-bucketed-prodid-m/ | year | product_id | 10 | 350M |
| 1.6 | parquet_us_partition_year_bucketed_prodid_s | s3://athena-udf-test-bucket-zhanla-us-east-1/parquet-us-partition-year-bucketed-prodid-s/ | year | product_id | 30 | 100M |
Athena SQL 执行计划
Amazon Athena 在执行 SQL 的过程中,会对 UDF 调用过程,进行一定程度的优化。通过关键字 EXPLAIN 来查看执行计划。例如,我们对如下的 SQL 语句查看执行计划:
输出结果输出如下图所示:

可以看到,SQL 的执行计划,已经进行了优化。减少 Amazon Athen 和 Amazon Lambda 之间的数据传输,是优化目标之一。上述的执行计划中,ScanFiler Project 描述了在 Athena 中通过条件 filterPredicate = (("customer_id" = CAST('51374126' AS varchar)) AND ("year" > BIGINT '2012')), 进行数据扫描过滤后,按照批次 Batch 将数据传输给 decrypt 函数进行解密,而不是首先扫描满足 year>2012 条件的数据,全部传给 Lambda 解密后,再按照条件 customer_id='51374126'进行过滤选取。
虽然 Athen 会对 SQL 进行优化,但是在复杂的 SQL 中,其内部的优化机制不一定能够达到最优,因此在包含有 UDF 函数的 Athen SQL,可以通过查看执行计划,进行优化。其中,防止 Amazon Athen 和 Amazon Lambda 之间不必要数据传输,是提升 SQL 执行的效率的一个重要原则。理论上,对 Lambda 的调用,在整个执行计划中越晚执行,效率越高。
查询效率比较
我们基于前面创建的 7 个表,分别对包含 UDF 和不包含 UDF 函数情况下的执行效率进行比较,为了具有更好的可比性,返回字段保持相近。另外,对于含有 UDF 的 SQL 语句,统计指标还包括了 Lambda 的调用次数,最大并发以及平均执行时间。
- 查询一: Athena SQL 不包含 UDF 的查询,返回字段为:
customer_id,product_id,review_headline和review_headline_plaintext,review_headline_encrypted,查询条件year=2015并且product_id = 'B00L9B7IKE'。这里review_headline_plaintext的实际内容为字段review_headline。下面查询语句中${tablename}需要改成实际的表名。
- 查询二:Athena SQL 包含 UDF 的查询,返回字段为:
customer_id,product_id,review_headline,review_headline_plaintext和review_headline_encrypted, 查询条件为year=2015并且product_id = 'B00L9B7IKE'。这里review_headline_plaintext的实际内容为字段review_headline_encrypted经过 UDF 解密后的结果。同样,下面查询语句中${tablename}需要改成实际的表名。
我们在测试的执行过程中,对每一个数据表的查询,按照如下的方式,进行指标采集。
- 查询数据的扫描量:Athena 执行后返回的扫描信息,由于查询条件以及查询字段一致,所以数据的存储方式,决定了数据查询中的扫描量。理论上,查询过程中的扫描量越大,查询会越慢。
- 不包含 UDF 的执行时间:连续执行上述“查询一”中的 SQL 10 次,去掉最长时间和最短时间后取平均值。由于查询一没有调用 UDF,因此理论上,如果查询条件和数据存储的 Partition 以及 Bucketing 越吻合,扫描量越低,查询效率越高。
- 包含 UDF 的执行时间:连续执行上述的“查询二”中的 SQL 10 次,去掉最长时间和最短时间后取平均值。整个查询执行的效率,除了和数据扫描效率有关,还和调用 UDF 的并发效率和 UDF 本身执行效率有关。
- Lambda 最大并发数量:在“查询二”中,不间断断连续执行该 SQL 约三分钟,取 Cloud Watch 中
Lambda Concurrent Executions指标的中间一分钟的平均值。 - Lambda 调用次数:在“查询二”中,不间断连续执行该 SQL 约三分钟,取 Cloud Watch 中
Lambda Invocations指标的中间一分钟调用次数。 - Lambda 平均执行时间:在“查询二”中,不间断连续执行该 SQL 约三分钟,取 Cloud Watch 中
Lambda Duration指标的中间一分钟 Lambda 平均执行时间。
按照上面的方法,Lambda 配置为 3072MB 内存配置时,测试结果如下:
| 序号 | 表名 | 分区 Partition |
bucket_count (Bucketing=product_id) |
查询Bucket文件 平均大小 |
查询的 扫描数据量 |
不包含UDF 执行时间(秒) |
包含UDF 执行时间(秒) (Lambda 3072MB) |
Lambda 最大并发数量 |
Lambda调用次数 | Lambda 平均执行时间(ms) |
| 1 | parquet_us | 无 | 无 | 1.8G | 9.56G | 2.42 | 3.87 | 28 | 3519 | 5.4 |
| 1.1 | parquet_us_partition_year | Year | 无 | 350M | 2.73G | 2.91 | 3.45 | 14 | 1321 | 8.5 |
| 1.2 | parquet_us_partition_year_bucketed_prodid_xxl | Year | 1 | 5.2G | 1.37G | 2.85 | 3.84 | 11 | 780 | 10.4 |
| 1.3 | parquet_us_partition_year_bucketed_prodid_xl | Year | 2 | 2.1G | 578.78M | 2.48 | 3.88 | 10 | 364 | 20.77 |
| 1.4 | parquet_us_partition_year_bucketed_prodid_l | Year | 5 | 1G | 287.69M | 2.38 | 3.44 | 6 | 155 | 39.04 |
| 1.5 | parquet_us_partition_year_bucketed_prodid_m | Year | 10 | 350M | 97.32M | 2.24 | 4.58 | 3 | 577 | 12.56 |
| 1.6 | parquet_us_partition_year_bucketed_prodid_s | Year | 30 | 100M | 30.48M | 2.16 | 6.19 | 2 | 763 | 8.13 |
按照上面的方法,Lambda 配置为 512MB 内存配置时,测试结果如下:
| 序号 | 表名 | 分区 Partition |
bucket_count (Bucketing=product_id) |
查询Bucket文件 平均大小 |
查询的 扫描数据量 |
不包含UDF 执行时间(秒) |
包含UDF 执行时间(秒) (Lambda 512MB) |
Lambda 最大并发数量 |
Lambda调用次数 | Lambda 平均执行时间(ms) |
| 1 | parquet_us | 无 | 无 | 1.8G | 9.56G | 2.42 | 4.05 | 76 | 3858 | 60 |
| 1.1 | parquet_us_partition_year | Year | 无 | 350M | 2.73G | 2.91 | 3.91 | 21 | 1200 | 19.55 |
| 1.2 | parquet_us_partition_year_bucketed_prodid_xxl | Year | 1 | 5.2G | 1.37G | 2.85 | 4.38 | 16 | 700 | 28.4 |
| 1.3 | parquet_us_partition_year_bucketed_prodid_xl | Year | 2 | 2.1G | 578.78M | 2.48 | 4.13 | 10 | 364 | 66.87 |
| 1.4 | parquet_us_partition_year_bucketed_prodid_l | Year | 5 | 1G | 287.69M | 2.38 | 4.1 | 10 | 133 | 343 |
| 1.5 | parquet_us_partition_year_bucketed_prodid_m | Year | 10 | 350M | 97.32M | 2.24 | 4.82 | 4 | 503 | 37.6 |
| 1.6 | parquet_us_partition_year_bucketed_prodid_s | Year | 30 | 100M | 30.48M | 2.16 | 7.05 | 3 | 783 | 19.05 |
我们通过统计图的方式,针对上述两个表,来展现和分析不同的数据存储方式下,SQL 查询的执行效率对比:
- 数据扫描量分析:SQL 查询的扫描数据量和数据存储的 Partition 和 Bucketing 设置相关,如下图所示,由于我们实验的查询条件为
Year和product_id,因此,当数据存储按照 Year 进行分区,并按照product_id进行 Bucketing,且 Bucketing 数量越大时,扫描效率越高。当然,如果 Bucketing 数量太大会导致读取文件效率下降,以及访问 S3 的 API 调用会增多。

- 整体查询效率分析:在“查询一”(SQL 中不包含 UDF)中, 如下图所示,数据的 Partition 和 Bucketing 有效地降低了数据的扫描量,因而也减少了 SQL 整体查询时间,但是和没有 Partition 定义的情况相比,查询效率在有 Partition 但没有设定 Bucketing 或者 bucket_count=1 的时候偏低,原因可能是 Partition 数据分布不均衡,我们所查询的 Partition(
Year=2015)里面,数据较其他的 Partition 数据更多。在“查询二”(SQL 中包含 UDF)中,当 Lambda 内存配置增加(从 512MB 增加到 3072MB)时,可以一定程度提高查询效率。从整体查询的效率来看,在没有 Bucketing 或者通过 bucket_count 设定使得查询文件平均大小为 1G 的时候整体查询效率最好。因为,文件太小虽然会使得 SQL 扫描效率提升,但是在调用 UDF 的效率反而可能会降低。

- Lambda 执行效率分析:如下图所示,相对于内存配置为 512MB 的 Lambda,内存配置为 3072MB 的 Lambda 在执行的过程中以更少的并发和更短的执行时间完成数据的解密,但是总体提升有限,这是因为我们所处理的数据加解密是一个计算密集型任务。但是,当通过提升 bucket_count,使得 Athena 对数据本身扫描和查询效率提高的同时,也导致了 Lambda 并发减少,Lambda 平均执行时间加长。这是因为,数据更加集中,Athena 在调用 Lambda 的时候,将大量数据传输给同一个 Lambda 处理,导致 Lambda 执行效率下降,最终导致整体的 SQL 查询效率下降。

总结和结论
Athena 虽然来源于 Trino 和 Presto, 但是不支持内置的自定义函数,而是将这些功能外置到 Lambda。这导致 UDF 比一般的数据库内置函数重得多,尤其是对于简单的计算更是如此。由于 Lambda 在 Lambda 自身的环境中运行,因此,调用外置的 UDF 不但导致进程间通信和运行上下文切换的负担,还会产生网络传输的额外开销,在数据量大的情况下可能会成为瓶颈。在本次实验中,我们看到,在 Athena SQL 中调用基于 Lambda 的 UDF,其执行效率收到各种条件的制约,这些条件相互依存,需要综合考虑。
- 本实验中,用于查询的 S3 中的源数据采用 Parquet 格式保存,并对部分源数据进行了 Partition 和 Bucketing 的设定。Partition 和 Bucketing 本身对查询文件扫描量影响较大。建立合适的 Partition 和 Bucketing 键,可以有效提高数据查询的效率,减少扫描数据量。由于 Amazon Athena 本身按照扫描的数据进行付费,这样在提升 SQL 性能的同时,还可以减少扫描数据量,以节省费用。
- 文件的大小会对 Athena 的性能产生影响,在测试过程中,在查询语句无论是包含 UDF,还是未包含 UDF。1G 大小的文件似乎效率更高。由于查询引擎一般会用单独的阅读器来完成对某个文件的读取,太大的文件会影响查询引擎本身的并行效率。对于太小的文件(通常小于 128MB), 执行引擎可能会花费额外的时间来处理打开 S3 文件、列出目录、获取对象元数据、设置数据传输、读取文件头、读取压缩的开销字典等操作,这反而也可能会降低了整体的效率。
- Athena 在调用 UDF 时,需要把数据通过网络传输给 Lambda,这意味着在数十亿行上运行 UDF 并不明智。一般情况下,Athena 会对 SQL 语句进行优化,来减少网络传输,我们也可以通过 EXPLAIN 命令查看执行计划,在此基础上,理解查询计划,并对 SQL 进行主动优化也很有必要。总体来说,在查询计划中尽可能晚(查询语句外层)使用 UDF 可以减少网络传输,提高 SQL 的运行效率。
- Athena 调用 Lambda 的方式和数量完全是由 Athena 自行管理的。实际上每次调用 Lambda 的时候, Athena 可能会将一批数据传递给 Lambda。在我们的实验中,数据的过度集中会引起 UDF Lambda 并发的减少,导致 Athena 把大批量数据,传给同一个 Lambda,从而使得整体运行时间反而可能更长。由于加解密本身更依赖于计算资源,更多的并发,意味着同时启动更多的 Lambda,获得更多的计算资源,更好的执行效率。
- 同样的数据分布,对于内存分配低的 Lambda,Athena 往往会引起更多的并发。通过适度增加 Lambda 内存,可以增强 Lambda 的运行效率,减少整个查询语句运行的时间,然而,就我们实验场景,由于加解密更依赖于计算资源,因而太多的内存提升并不会提升整个查询的效率。
- 由于在 Athena 中 UDF 是通过 Lambda 实现的,所以初次调用会有冷启动的问题,速度较慢。在本次实验中,我们通过去掉异常值的方式,结合多次采样的平均时间,来提升测试准确率。另外,Lambda 本身的执行效率可以通过覆写 UserDefinedFunctionHandler 中的 processRows 方法,直接处理 Arrow data,减少对象拷贝,来提升效率。
- Athena 有一些内置的标准函数,这些函数在 Athena 的运行环境中执行,因而效率更高,所以应优先考虑,只有当这些内置的标准函数无法满足需求时,考虑外置的 Lambda 定义的 UDF。另外,在 Athena 的 SQL 当中,不仅仅可以在查询的 SELECT 中使用 UDF,还可以在 FILTER 子句中使用,甚至在同一查询中调用多个 UDF。需要注意的是, 区域级的 Lambda 配额适用于 Athena UDF,所以在 Athena 中调用基于 Lambda 的 UDF,同样需要考虑配额的限制。
参考文档:
- Creating a table from query results(CTAS)
https://docs.thinkwithwp.com/athena/latest/ug/ctas.html
- How can I set the number or size of files when I run a CTAS query in Athena?
https://thinkwithwp.com/premiumsupport/knowledge-center/set-file-number-size-ctas-athena/
- Top 10 Performance Tuning Tips for Amazon Athena
https://thinkwithwp.com/cn/blogs/big-data/top-10-performance-tuning-tips-for-amazon-athena/
- Bucketing vs partitioning
https://docs.thinkwithwp.com/athena/latest/ug/bucketing-vs-partitioning.html
- Building Lambda functions with Java
https://docs.thinkwithwp.com/lambda/latest/dg/lambda-java.html
- Querying with User Defined Functions
https://docs.thinkwithwp.com/athena/latest/ug/querying-udf.html
- Querying with User Defined Functions – Considerations and Limitations
https://docs.thinkwithwp.com/athena/latest/ug/querying-udf.html
- Example IAM permissions policies to allow Amazon Athena User Defined Functions(UDF)
https://docs.thinkwithwp.com/athena/latest/ug/udf-iam-access.html
- Operating Lambda: Performance optimization – Part 1
https://thinkwithwp.com/blogs/compute/operating-lambda-performance-optimization-part-1/
- Operating Lambda: Performance optimization – Part 2
https://thinkwithwp.com/blogs/compute/operating-lambda-performance-optimization-part-2/
- Caching data and configuration settings with Amazon Lambda extensions
- Functions in Amazon Athena
https://docs.thinkwithwp.com/athena/latest/ug/functions.html
- Using EXPLAIN and EXPLAIN ANALYZE in Athena
https://docs.thinkwithwp.com/athena/latest/ug/athena-explain-statement.html
- Understanding Athena EXPLAIN statement results
https://docs.thinkwithwp.com/athena/latest/ug/athena-explain-statement-understanding.html