亚马逊AWS官方博客
DMS宝典-轻松迈出数据库上云第一步
近期AWS在 BJS和ZHY region推出了AWS Database Migration Service 服务(以下简称DMS),它可以帮助我们在很多场景完成数据库迁移:
- 可以将数据迁入或迁出Amazon EC2 上建立的数据库或Amazon RDS
- 支持同构或异构数据库的迁移
- 支持7*24小时online的数据库迁移
- 可以进行跨region、跨账号的数据库数据迁移
当ZHY推出aurora数据库后,很多客户希望从现有数据库迁移到aurora,而DMS的推出,恰逢其时,为客户提供了一个数据库迁移的利器。那么接下来,我将通过一个使用DMS迁移BJS region中 Oracle数据库的数据到ZHY region中aurora数据库的案例,让大家更好地了解DMS服务。
基本原理
对于数据库迁移来说,大致可以分为两个阶段:
1 在目标数据库上生成schema,如果是同构数据库迁移,这一步骤相对简单,如果是异构数据库迁移,则会复杂很多,因为异构数据库迁移涉及数据库引擎变化,不同数据库的数据对象定义有所不同,甚至可能出现部分源数据库的数据对象在目标数据库中不支持的现象。我们的AWS Schema Conversion Tool(以下简称SCT)可以帮助我们自动对schema进行转换,对于复杂的异构数据库迁移,我们可以通过SCT产生基础脚本,DBA再进行人工加工,最终在目标数据库生成schema。
2 将数据迁移到目标数据库, DMS可以支持全量加载和变更捕获复制,也就说既可以只将历史数据迁移,也可以在两个数据库之间完成持续增量数据同步。在此过程中, DMS 会自动管理支持您的迁移服务器的基础设施的所有部分,包括硬件和软件、软件修补和错误报告。
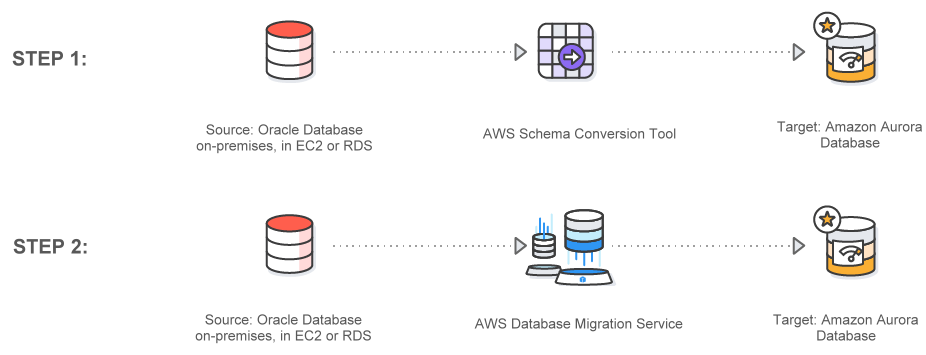
下图阐明了 AWS DMS 的主要组件:

- Replication instance是 DMS 使用复制软件自动配置的服务器。DMS 提供了自动故障转移。如果您的主复制服务器因任何原因发生故障,则备份复制服务器可接管运行,这可以保证replication task不会因为Replication instance的宕机而失败
- 为源和目标数据库创建endpoint,并保证Replication instance可以连接两个endpoint
- 创建replication task,将选定的数据从源数据库复制到目标数据库
迁移流程
使用DMS完成对一个7*24 小时online数据库最小停机时间迁移的大致流程如下:
前期准备
- 生成目标数据库
- 在源和目标数据库上生成专门用于迁移的数据库用户并授权
- 对于CDC任务,需要参考文档,在源数据库上做相应设置,譬如开启归档,补充日志等
- 生成复制实例,设置 网络环境, 保证复制实例可以连接到源数据库和目标数据库
- 生成两个数据库的endpoint , 测试复制实例可以连接
- 如果字符集有不兼容问题,考虑在迁移前对源数据库数据进行处理
- SCT 会帮助我们转换schema, 但DBA手工干预依然重要
生成启动DMS 任务
- 创建 full load and CDC DMS 任务
- 如果数据量巨大, 考虑拆分成多个任务并行处理
- 必要时考虑在目标数据库 删除 PK/UK/index 来加速full load 任务
- Full Load任务期间在目标数据库需要禁用外键检查并disable 所有trigger以避免数据同步异常
- Full load任务结束后生成约束和index 以加速CDC任务,但确保triggers继续处于disabled状态
- 通过 CDC 任务 完成持续变更捕获复制,在源和目标数据库之间同步数据,等待切换窗口
切换过程
- 目标数据库端验证所有数据库对象均已生成
- 应用端测试验证功能流程可以在目标数据库上顺利完成
- 考虑回退选项,是否需要保留从目标数据库切换回源数据库的可能
- 验证源、目标两个数据库中关键数据一致
- 在业务低谷期,将源数据库置为只读,等待CDC 任务 的replicate lag 变为0
- 在目标数据库处理 Sequences 并 enable triggers
- 切换数据库,将应用指向目标数据库
- 数据库切换后的检验,监控
迁移案例
所谓“纸上得来终觉浅,绝知此事要躬行”,我们用一个案例来演示如果使用DMS跨region迁移异构数据库,让大家对DMS有一个直观的认识。本案例中源数据库是我在BJS region中EC2上创建的 Oracle数据库,目标数据库则是ZHY region中的aurora RDS数据库。
1 环境准备
1.1 源数据库
在源数据库上创建专用于DMS 任务的用户 dmsadmin 并授权。当然您可以用现有用户执行DMS任务,但是使用专用用户可以让您轻松地将DMS任务产生的数据变更和正常业务产生的数据变更区分开来,而且也更容易对用户进行管理。
如果您要使用CDC任务不要忘了按照文档对源数据库做额外设置,譬如开启补充日志。登陆源数据库执行:
create user dmsadmin identified by dmsadmin;
grant DBA to dmsadmin;
alter database force logging;
alter database add supplemental log data;
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (PRIMARY KEY) COLUMNS;
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA (UNIQUE) COLUMNS;
select name,log_mode,supplemental_log_data_min,supplemental_log_data_pk,supplemental_log_data_pk,force_logging from v$database;
最后的查询输出应类似:

1.2 目标数据库
在目标数据库上生成专用于AWS DMS任务的用户dmsadmin并授权。登陆目标数据库并执行:
create user dmsadmin identified by ‘dmsadmin’;
GRANT ALTER, CREATE, DROP, INDEX, INSERT, UPDATE, DELETE, SELECT,SHOW VIEW,REFERENCES,CREATE VIEW,TRIGGER,CREATE ROUTINE,ALTER ROUTINE,EXECUTE ON *.* TO dmsadmin;
flush privileges ;
show grants for dmsadmin;

2 转换Schema
接下来我们将是用SCT来转换schema,请遵循官方文档,根据自己的平台下载安装最新的SCT https://docs.thinkwithwp.com/zh_cn/SchemaConversionTool/latest/userguide/CHAP_Installing.html
而后打开SCT,创建一个新的project,命名为oracle to aurora,并选择源数据库引擎为oracle,目标数据库引擎为aurora mysql

连接源oracle数据库,输入服务器地址,端口、SID等连接信息,用新建立的DMS任务专用用户名,密码登录,测试连接通过后点击OK

同样地连接目标aurora数据库,输入服务器地址,端口、SID等连接信息,用新建立的DMS任务专用用户名,密码登录,测试连接通过后点击OK

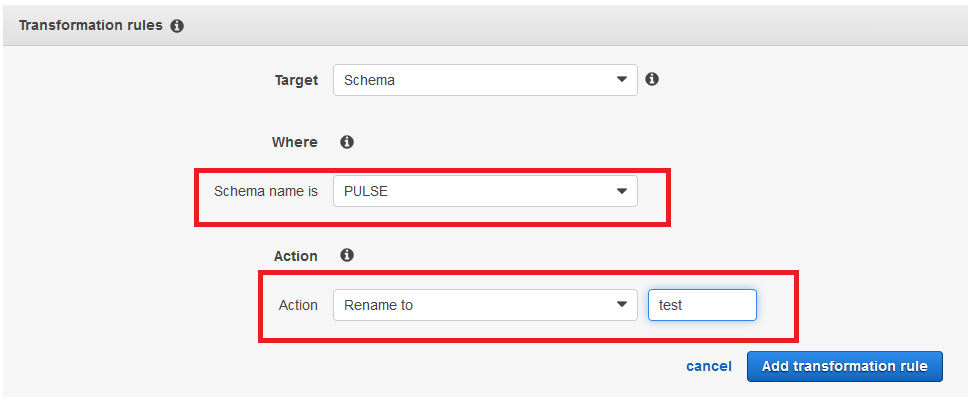
连接后可以看到源和目标数据库的schema信息,点击上方菜单中的settings选择mapping rules添加映射规则,我们模拟一个需求,要将源数据库上的PULSE schema转换为test schema ,先点击add new rule,在弹出的界面中选择类型schema,输入PULSE,然后action选择rename目标填入test,最后点击save,添加一条映射规则。

添加规则后,在左侧源数据库schema列表里选择要导出的schema,右键引出菜单,然后单击covert schema

转换schema后,在右侧目标数据库schema列表里会出现新的test schema,我们点击test右键引出菜单,有两个选择,一种是直接apply to database,完全依赖SCT完成schema转换,在目标数据库上直接生成schema;另一种是选择save as SQL将SCT转换的结果保存为SQL脚本,而后在此基础上进行人工干预,生成最终SQL脚本并运行该脚本在目标数据库上创建schema。对于异构大型数据库迁移,如果涉及一些源数据库的对象在目标数据库上不支持,那么DBA的人工干预就是必不可少的,建议大家在目标数据库上生成schema之前,务必人工review脚本。

3 生成复制实例和endpoint
3.1 生成子网组
接下来我们将生成DMS相关资源,首先按文档为IAM用户赋予相应权限https://docs.thinkwithwp.com/zh_cn/dms/latest/userguide/CHAP_Security.IAMPermissions.html ,使用IAM用户登陆AWS console并进入DMS主页,在左侧列表中选择subnet groups创建子网组,在您的VPC内选择子网,请确保选择的子网至少覆盖两个可用区。

3.2 生成复制实例
接下来在左侧列表选择replication instances创建复制实例,请注意如下设置:
1 实例类型,复制实例对抽取数据的处理发生在内存中。但是,大型事务可能需要部分缓冲到磁盘上。缓存事务和日志文件也会写入磁盘。目前可选的实例类型有 T2、C4 和 R4 Amazon EC2 实例类型,T2实例类型用于测试环境,DMS 在执行异构迁移和复制时可能会占用大量 CPU,C4实例类型很适合,如果源数据库有很大吞吐量,则会消耗更多内存,此时R4实例类型优化的内存会很有帮助。如果选择的复制实例资源不足会导致DMS任务缓慢,甚至极端的时候可能导致任务失败。
2 多可用区部署,选择多可用区选项时,复制实例使用多可用区部署提供高可用性和故障转移支持。在多可用区部署中, DMS 自动在不同可用区中预置和维护复制实例的同步备用副本。复制实例崩溃不会导致DMS任务失败
3 网络设置,不仅仅是复制实例所在的网络设置,包括源数据库和目标数据库所在的网络也需要进行妥善设置,确保复制实例可以连接源和目标数据库
4 维护设置,AWS DMS 会在您指定的运维窗口期定期对 AWS DMS 资源譬如复制实例或复制实例的操作系统 (OS)进行更新。维护会暂停DMS任务,维护后继续任务。



3.3 生成源和目标数据库的endpoint
在左侧列表中选择endpoint,生成源和目标数据库的endpoint,首先选择endpoint type是source还是target,而后分别输入endpoint的名称,数据库引擎,数据库服务器地址,端口等连接信息以及是否用SSL连接,用新建的dmsadmin用户登录。
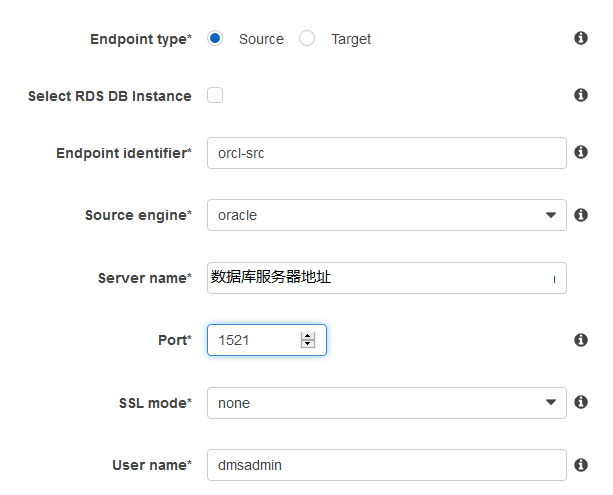
最后用我们创建的复制实例测试连接,连接通过后创建endpoint,如果您面对连接测试失败,请检查连接信息是否正确,另外请查看您的网络设置。

4 生成并运行DMS任务
现在万事俱备只欠东风,我们来创建DMS任务迁移数据,在启动full load DMS任务前,请务必确保目标数据库的外键约束检查被关闭以及trigger被disable,因为在full load任务加载数据时,不能保证父表数据会先于子表加载,如果此时开启外键约束可能会报错,同样地在数据迁移阶段启动trigger也可能导致数据异常。
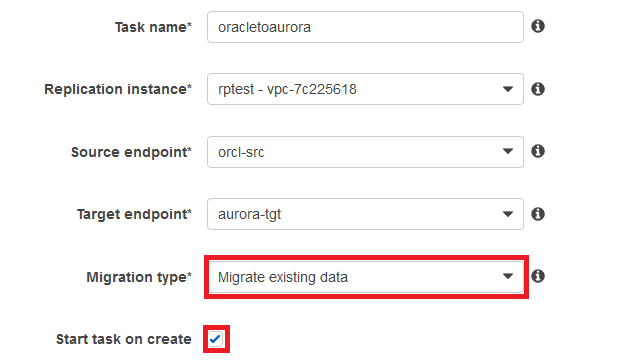
在左侧列表中选择tasks,然后点击create task。此前我们已经创建了复制实例,源和目标endpoint,现在我们需要给task命名,并作出设置:
1 任务类型 DMS支持三种任务类型,在这里我们选择Migrate existing data and replicate ongoing changes
- Migrate existing data: 在 API 中称为full-load,选择该选项, DMS 将仅迁移现有数据。不捕获对源数据的变更,也不会将这些变更应用于目标。如果您的停机窗口足够长或者要搭建测试环境时可以选择此项
- Migrate existing data and replicate ongoing changes: 在 API 中称为full-load-and-cdc,选择该选项, DMS 可在迁移您的现有数据时捕获变更。在初始加载数据后,AWS DMS会继续捕获和应用变更。最终,源数据库和目标数据库将保持同步,从而实现停机时间最少的迁移。
- Replicate data changes only: 在 API 中称为cdc ,仅捕获并复制变更
2 是否创建任务后立刻启动,如果选择,任务创建成功后会立刻启动
3 CDC stop mode:指定CDC任务是否停止以及停止的时间,停止的时间可以指定源上的提交时间或复制实例上的服务器时间,这里我们不指定停止时间
4 target table preparation mode:3种对目标表的准备模式,我们这里选择Do nothing
- Do nothing – 不更改目标表的数据和元数据。如果前期已经在目标数据库上生成了schema,而且没有冲突数据,选择此项
- Drop tables on target – drop表并在其位置创建新表。但注意AWS DMS 不会创建二级索引、非主键约束或列数据默认值。
- truncate – truncate表,但保留表的结构。譬如初始加载曾经失败,再次加载时可以选择此项
5 stop task after full load complete:这里选择Don’t stop,初始加载后立刻开始CDC任务,但是如果是大型系统,有时候我们会为了加速初始加载删除二级索引甚至主键和唯一约束,那么初始加载后可以暂停任务,重新生成主键/唯一约束和二级索引,这些可以用来加速后续的CDC任务,因为约束和索引有助于定位后续变更的行。
- Don’t stop– 不停止任务,初始加载后立刻开始CDC任务
- Stop before applying cached changes–初始化加载开始后的变更会缓存,初始加载完成后应用这些缓存的变更再停止任务
- Stop after applying cached changes– 初始加载完成后不应用缓存的变更就停止任务

6 Include LOB columns in replication,Limited LOB mode 速度更快,但会将 LOB 截断为最大 LOB 大小参数的值,从而造成数据丢失
- Don’t include LOB columns -从迁移操作中排除 LOB 列
- Full LOB mode – 迁移整个 LOB,而不管大小如何。AWS DMS 以块的形式分段迁移 LOB,块的大小受最大 LOB 大小参数的控制。此模式比受限 LOB 模式的速度要慢
- Limited LOB mode – 将 LOB 截断为最大 LOB 大小参数的值。此模式比使用完整 LOB 模式的速度要快
7 Enable validation 启用数据验证,确定是否准确地将数据从源迁移到目标。
8 Enable logging 启用日志记录,可以从Amazon CloudWatch监控任务,请务必开启日志记录,这对我们监视,调优,troubleshooting DMS任务有巨大的帮助。
9 在table mappings部分可以设置加载数据范围和映射信息,点击添加selection rule,选择要加载的数据,指定schema,action选择include
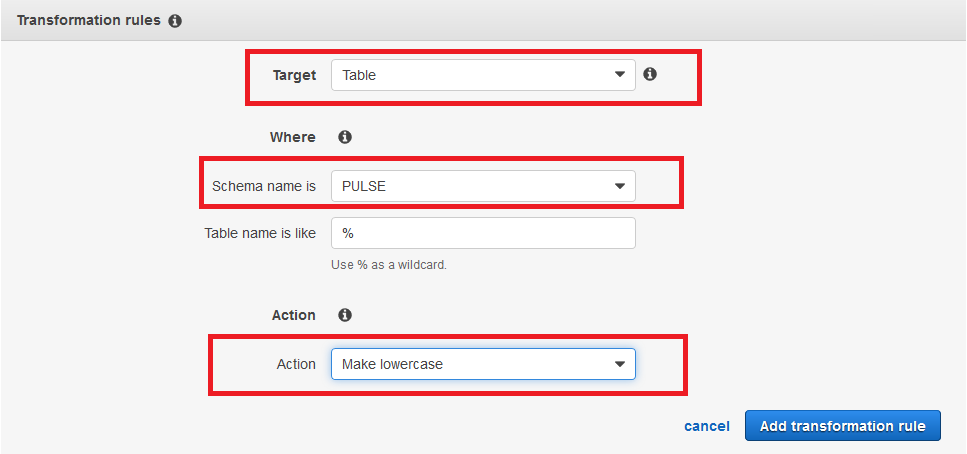
10 添加transformation rule,譬如我们选择要加载的schema通过action下拉菜单选择rename to,可以将源数据库的schema转换到新的schema;再比如ORACLE数据字典内存储的表名列名等信息都是大写,那么可以在这里指定转为小写,选择target为table或column。完成以上设定后最后点击创建任务。

5 DMS任务的监控
因为我们选择了start task on create,故而任务创建后自动开始运行,执行full load,可以通过console看到任务的status先是starting,而后是running,full load结束后变为load completed,从下面详细信息部分,选择table statistics页签,可以看到我们有3张表要加载,三张表的full load rows和total部分值一样,说明历史数据已经全部加载完毕,我们可以通过select count(*)语句对源数据库和目标数据库对应表的行数进行进一步检测。

另外,因为我们选择了logging enabled,通过选择logs页签,可以看到cloudwatch的链接,点击可以看到DMS运行日志,今后我们如果要监控,调优乃至troubleshooting DMS 任务,这里是首先要查看的部分。

在full load加载完毕后,根据我们前面的选择,DMS自动进入CDC阶段,我们在源数据库端对EMP表执行了一系列的增删改查,可以看到table statistics部分中,对EMP表上发生后续变更的数量有所记录,我们同样可以进一步通过SQL语句在源和目标数据库分别进行验证,数据也完全一致,这样就可以证明CDC任务运行正常。
至此,我们的跨region,异构数据库迁移已经完成了大部分,接下来我们需要和应用团队商定一个切换窗口期,遵照前面我们提到的切换流程,将应用程序切换到目标数据库,整个数据库迁移工作就大功告成了。

总结
本文介绍了DMS任务的基本原理,数据库迁移的大致流程,并用一个跨region异构数据库迁移的案例让大家对DMS有了一个直观的认识,相信大家也发现了DMS是一款安全、便捷而高效的迁移数据库利器,希望大家充分利用DMS,轻松迈出数据库上云的第一步。
当然,数据库迁移是一个庞大而复杂的工程,尤其将数据库迁移上公有云,除了数据库知识更需要了解公有云上网络,存储,虚拟化等一系列知识。但是,我们不应该仅仅将数据库上云看做一个复杂的任务,更应该把它当做一个优化我们数据库的契机,关于如何选择合适的云端数据库,如何迁移非关系型数据库上云等话题,限于篇幅本篇blog这里没有涉及,敬请期待我们后续的blog。
参考资料
《AWS Schema Conversion Tool用户指南》 https://docs.thinkwithwp.com/zh_cn/SchemaConversionTool/latest/userguide/CHAP_Installing.html
《AWS Database Migration Service用户指南》https://docs.thinkwithwp.com/zh_cn/dms/latest/userguide/Welcome.html