在近日全球规模最大的语义评测比赛 SemEval 2020中,语义理解框架ERNIE斩获了包括视觉媒体的关键文本片段挖掘、多语攻击性语言检测和混合语种的情感分析等在内的5项世界冠军。它所提出的知识增强语义表示模型,以及2.0版本构建的持续学习语义理解框架,在中英文等多个任务上超越业界最好模型。尤其在多项中文NLP任务中,ERNIE的结果都能与 BERT 持平或有所提升。
ERNIE(Enhanced Representation through Knowledge Integration)旨在使用纯文本捕获语义模式的基础之上,进一步通过知识增强的方式,结合语义中的知识关系来提供更加丰富的结构化表现。
ERNIE 1.0在发布之初,针对BERT(Pre-training of Deep Bidirectional Transformers for Language Understanding )以字为单位的建模方式无法学习到知识单元的完整语义表示等问题,提出使用知识实体来学习完整概念的语义表示,并引入多源的数据语料进行训;ERNIE 2.0则提出了一个预训练框架,通过连续学习(Continual Learning)方式,使用多个不同的任务顺序训练一个模型,这样,下个任务就会利用到前面任务的学习成果,不断积累新的知识。面对新任务,可以直接使用历史任务学习到的参数来初始化模型,以获取更好的训练效果。
Amazon SageMaker 是亚马逊云计算(Amazon Web Service)的一项完全托管的机器学习平台服务,算法工程师和数据科学家可以基于此平台快速构建、训练和部署机器学习 (ML) 模型,而无需关注底层资源的管理和运维工作。它作为一个工具集,提供了用于机器学习的端到端的所有组件,包括数据标记、数据处理、算法设计、模型训练、训练调试、超参调优、模型部署、模型监控等,使得机器学习变得更为简单和轻松;同时,它依托于AWS强大的底层资源,提供了高性能CPU、GPU、弹性推理加速卡等丰富的计算资源和充足的算力,使得模型研发和部署更为轻松和高效。
ERNIE是基于开源深度学习平台——飞桨(PaddlePaddle)来设计和实现的,本系列博客会重点介绍如何通过Amazon SageMaker来实现基于此类第三方框架和自定义算法的模型预训练、增量训练和推理部署等机器学习任务,实现的技术细节和操作方法同样适用于其他类似的使用场景。
本文首先会重点介绍在Amazon SageMaker中使用ERNIE来进行模型预训练(pretraining)任务的方法。
Amazon SageMaker模型训练介绍
Amazon SageMaker为机器学习任务提供了基础算力和操作平台,在该平台上启动模型训练任务,包括如下过程:从Amazon SageMaker的计算集群中启用指定算力的机器实例,实例加载包含了算法和框架在内的容器镜像,并且加载存放于外部存储(如S3)的训练、验证、测试等数据集,启动训练脚本,完成模型迭代,保存模型等。而用户仅需做好相应参数配置,即可通过控制台点击或API调用方式完成。
训练任务的核心在于选择包含算法和框架在内的容器镜像,关于训练镜像的来源,您既可以选择由Amazon SageMaker提供的多种内置算法镜像,也可以选择基于Amazon SageMaker内置框架(TensorFlow、Apache MXNet、PyTorch、Scikit-learn、XGBoost、Chainer)镜像,结合您自己的代码来完成训练。如果您需要使用自己的训练代码,并基于其他第三方框架或自带框架来完成模型训练,也可以通过自带容器的方法基于Amazon SageMaker来实现。
本文会针对最后一种情况,重点介绍在Amazon SageMaker上如何基于PaddlePaddle框架,结合自定义算法来完成ERNIE模型的预训练任务。该方法同样适用于其他自定义框架和算法的类似任务的实现。
通过自带容器方法实现自定义算法的模型预训练
关于ERNIE模型的预训练任务请参见此链接中的“预训练 (ERNIE 1.0)”章节。
如果您在本地机器运行该预训练任务,需要完成以下两项工作:
- 本地安装PaddlePaddle框架
- 本地执行训练脚本
为将该任务从本地机器迁移到Amazon SageMaker,我们需要针对这两项工作进行如下调整:
- 本地安装PaddlePaddle框架 -> 构建适配于SageMaker Container的PaddlePaddle容器
1)Amazon SageMaker是基于容器机制来实现机器学习任务的,对于自带框架和算法的场景,需要自行构建包含目标框架及相关依赖项在内的容器,并推送到Amazon Elastic Container Registry(ECR)镜像注册表中,供SageMaker进行拉取和调用。
2)在本文示例中,该部分工作的工程目录如下,该工程可以部署在SageMaker Jupyter Notebook(推荐)或其他计算资源上。
/<for-docker-directory>/
├── ernie
│ ├── …
├── Dockerfile
├── requirements.txt
└── docker-actions.ipynb
说明:
- ernie:为源码中ernie框架实现代码,文件目录中的内容也进行了一些调整,主要包括:
- 将根目录下的config文件夹拷贝到此目录下;
- 为适配接口的调用,修正pretrain_args.py、train.py和pretraining.py三个文件中的部分代码,具体细节请见下文描述。
- Dockerfile:Docker描述文件
- requirements.txt:为源码工程根目录下依赖项描述文件,这里的requirements.txt去掉paddlepaddle-gpu==1.6.3.post107一项;
- docker-actions.ipynb:容器打包和上传代码,以笔记本方式调用。
3)编写Dockerfile,本文示例的Dockerfile及说明如下:
# 拉取预安装 PaddlePaddle 的镜像,具体镜像参考https://www.paddlepaddle.org.cn/documentation/docs/zh/1.7/install/install_Docker.html#docker
FROM paddlepaddle/paddle:1.6.3-gpu-cuda10.0-cudnn7
# 标记维护者信息
MAINTAINER Amazon AI <sage-learner@amazon.com>
# 拷贝requirements.txt到容器代码目录
COPY requirements.txt /opt/ml/code/requirements.txt
# 安装依赖项
RUN pip install -r /opt/ml/code/requirements.txt
# 安装 SageMaker Container
RUN pip install sagemaker-containers==2.6.1
# 将git工程中的ernie文件夹拷贝到容器的/opt/ml/code目录下
COPY ernie /opt/ml/code
# 定义train.py为训练任务脚本
ENV SAGEMAKER_PROGRAM train.py
说明:
- SageMaker Container作为一个库,它可以运行脚本、训练算法或部署与 Amazon SageMaker 兼容的模型,它定义了您的安装代码、数据等资源在容器中的存储位置,您需要通过Dockerfile将要运行的代码保存在SageMaker 容器所期望的位置(/opt/ml/code),具体内容请参见:
https://docs.thinkwithwp.com/zh_cn/sagemaker/latest/dg/amazon-sagemaker-containers.html,https://github.com/aws/sagemaker-containers;
- ernie目录也按照SageMaker Container目录要求拷贝到/opt/ml/code;
- 设置环境变量SAGEMAKER_PROGRAM,定义train.py为训练任务脚本。
4)执行docker-actions.ipynb内的容器打包和上传代码:
# 设置权限并构建容器
!chmod +x train.py
!docker build -t pd-ernie-pretrain:v1 .
# 获取ECR login
!$(aws ecr get-login --no-include-email --region us-west-2)
# 容器打标签
!docker tag pd-ernie-pretrain:v1 <your-aws-account>.dkr.ecr.<region>.amazonaws.com/<
repository>:pd-ernie-pretrain
# 将容器推送到ECR
!docker push "<your-aws-account>.dkr.ecr.<region>.amazonaws.com/<
repository>:pd-ernie-pretrain"
这样,在您AWS账号ECR服务的指定存储库中就包含了一个集成PaddlePaddle框架和ERNIE工程的模型训练容器。请记住该容器在存储库中的名称”<your-aws-account>.dkr.ecr.<region>.amazonaws.com/<repository>:pd-ernie-pretrain”,供Amazon SageMaker后续调用。
- 本地执行训练脚本 -> 通过API方式在 Amazon SageMaker上启动训练任务
本地执行训练ERNIE预训练的脚本为script/zh_task/pretrain.sh,其中核心的训练命令为:
python ./ernie/train.py --use_cuda True \
--is_distributed False\
--use_fast_executor True \
--weight_sharing True \
--in_tokens true \
--batch_size 8192 \
--vocab_path ./config/vocab.txt \
--train_filelist ./data/train_filelist \
--valid_filelist ./data/valid_filelist \
--validation_steps 100 \
--num_train_steps 1000000 \
--checkpoints ./checkpoints \
--save_steps 10000 \
--ernie_config_path ./config/ernie_config.json \
--learning_rate 1e-4 \
--use_fp16 false \
--weight_decay 0.01 \
--max_seq_len 512 \
--skip_steps 10
该命令形式也是我们在本地机器上执行训练任务的常规方式,现在我们一起看一看如何将该命令转化为API参数在Amazon SageMaker上启动训练任务。
该命令的参数主要包括3个部分:基础配置项(如use_cuda)、输入数据路径(如vocab_path)以及算法超参(如learning_rate)。其中输入数据路径又分为基础配置数据路径(vocab_path、ernie_config_path)和数据集路径(train_filelist、valid_filelist)。在使用Amazon SageMaker进行模型训练过程中,最佳实践是将数据集存放于外部的存储服务中,如Amazon Simple Storage Service (S3)、Amazon Elastic File System (EFS)、Amazon FSx,通知SageMaker拉取相应数据集进行计算任务。因此,这里的train_filelist和valid_filelist不会通过此参数传递方式将一个本地路径输入至训练脚本,而是通过SageMaker的data channel方式指定S3中的数据集的位置。去掉train_filelist和valid_filelist两个参数后,将剩余参数构造如下_hyperparameters的字典对象:
_hyperparameters = {
"use_cuda": True,
"is_distributed":False,
"use_fast_executor":True,
"weight_sharing":True,
"in_tokens":True,
"batch_size":8192,
"vocab_path":"./config/vocab.txt",
"num_train_steps":10000,
"checkpoints":"./checkpoints",
"save_steps":1000,
"ernie_config_path":"./config/ernie_config.json",
"learning_rate":"0.0001",
"use_fp16":False,
"weight_decay":0.01,
"max_seq_len":512,
"skip_steps":10,
"validation_steps": 100
}
对于train_filelist和valid_filelist两个文件列表文件,我们首先看一下data路径下的数据组成:
ERNIE/data/
├── demo_train_set.gz
├── demo_valid_set.gz
├── train_filelist
└── valid_filelist
其中demo_train_set.gz和demo_valid_set.gz为编码后的数据文件,train_filelist为数据文件列表描述:
./data/demo_train_set.gz 1.1
在本文示例中,我们扩展数据集及并修正文件列表如下:
ERNIE/data/
├── demo_train_set.gz
├── demo_train_set2.gz
├── demo_train_set3.gz
├── demo_train_set4.gz
├── demo_train_set5.gz
├── demo_valid_set.gz
├── demo_valid_set2.gz
├── train_filelist
└── valid_filelist
train_filelist:
demo_train_set.gz 1.1
demo_train_set2.gz 1.1
demo_train_set3.gz 1.1
demo_train_set4.gz 1.1
demo_train_set5.gz 1.1
valid_filelist:
demo_valid_set.gz 1.1
demo_valid_set2.gz 1.1
修正后,将数据集文件及文件列表上传至S3:
<your-s3-bucket>/ernie/
├── train
│ ├── demo_train_set.gz
│ ├── demo_train_set2.gz
│ ├── demo_train_set3.gz
│ ├── demo_train_set4.gz
│ ├── demo_train_set5.gz
│ ├── train_filelist
├── valid
│ ├── demo_valid_set.gz
│ ├── demo_valid_set2.gz
└─ ├── valid_filelist
上传后,我们构建一个数据通道字典,描述对应数据集在s3的存储位置:
_train_data = 's3://{}/{}/{}'.format(bucket, folder, 'train')
_valid_data = 's3://{}/{}/{}'.format(bucket, folder, 'valid')
_data_channels = {'train': sagemaker.session.s3_input(_train_data),
'valid': sagemaker.session.s3_input(_valid_data)}
SageMaker收到此data_channel后会自动从s3对应位置拉取数据,下载到容器/opt/ml/data/<channel_name>/路径下,这里的<channel_name>对应的是字典两个key:train和valid。
因此,为指导训练脚本从/opt/ml/data/<channel_name>/路径下读取训练数据,需要对pretrain_args.py、train.py和pretraining.py进行一些修正(源工程是基于参数中的–train_filelist和–valid_filelist路径进行数据读取的),修正方式如下:
pretrain_args.py
data_g.add_arg("train_filelist", str, "", "Path to training filelist.")
data_g.add_arg("valid_filelist", str, "", "Path to valid filelist.")
修改为
data_g.add_arg("train_filelist", str, os.environ['SM_CHANNEL_TRAIN'] + "/train_filelist", "Path to training filelist.")
data_g.add_arg("valid_filelist", str, os.environ['SM_CHANNEL_VALID'] + "/valid_filelist", "Path to valid filelist.")
其中环境变量os.environ[‘SM_CHANNEL_TRAIN’]即/opt/ml/data/train,os.environ[‘SM_CHANNEL_VALID’]即/opt/ml/data/valid,对应数据集在容器中存储的路径
Pretraining.py
class ErnieDataReader(object):
def __init__(self,
filelist,
vocab_path,
batch_size=4096,
in_tokens=True,
max_seq_len=512,
shuffle_files=True,
random_seed=1,
epoch=100,
voc_size=0,
is_test=False,
generate_neg_sample=False):
增加一个参数data_tag
修改为
class ErnieDataReader(object):
def __init__(self,
data_tag,
filelist,
vocab_path,
batch_size=4096,
in_tokens=True,
max_seq_len=512,
shuffle_files=True,
random_seed=1,
epoch=100,
voc_size=0,
is_test=False,
generate_neg_sample=False):
类内实现增加变量:
方法data_generator增加:
def data_generator(self):
"""
data_generator
"""
def wrapper():
def reader():
for epoch in range(self.epoch):
self.current_epoch = epoch + 1
files = self.files
#during training, data are sliced by trainers
if self.shuffle_files:
start = epoch * self.total_file
end = start + self.total_file
files = [file_ for index, file_ in enumerate(self.files[start:end]) \
if index % self.trainer_nums == self.trainer_id]
for index, file_ in enumerate(files):
file_, mask_word_prob = file_.strip().split("\t")
mask_word = (np.random.random() < float(mask_word_prob))
self.current_file_index = (index + 1) * self.trainer_nums
self.current_file = file_
############ Modify - Start ############
env_str = 'SM_CHANNEL_' + self.data_tag.upper()
file_ = os.environ[env_str] + '/' + file_
############ Modify – End ############
if mask_word:
self.mask_type = "mask_word"
else:
self.mask_type = "mask_char"
train.py修正
方法predict_wrapper:
filelist = args.test_filelist if args.do_test else args.valid_filelist
############ Modify - Start ############
tag = 'test' if args.do_test else 'valid
data_reader = ErnieDataReader(
tag,
filelist,
vocab_path=args.vocab_path,
batch_size=args.batch_size,
voc_size=ernie_config['vocab_size'],
shuffle_files=False,
epoch=1,
max_seq_len=args.max_seq_len,
is_test=True)
############ Modify – End ############
方法train
############ Modify - Start ############
data_reader = ErnieDataReader(
data_tag = 'train',
filelist=args.train_filelist,
batch_size=args.batch_size,
vocab_path=args.vocab_path,
voc_size=ernie_config['vocab_size'],
epoch=args.epoch,
max_seq_len=args.max_seq_len,
generate_neg_sample=args.generate_neg_sample)
############ Modify – End ############
在训练完成后,由于Amazon SageMaker会自动回收启动的计算资源,因此需要将模型保存至环境变量“SM_MODEL_DIR”对应的目录(/opt/ml/model/)下,SageMaker会在回收资源之前自动将该目录下的模型文件上传至s3的指定目录中。
代码修改如下所示:
train.py
在方法train中,添加:
def train(args):
…
fluid.io.save_inference_model(dirname=os.environ['SM_MODEL_DIR'],
feeded_var_names=['1','2','3','4'],
target_vars=[next_sent_acc],
executor=exe,
main_program=train_program)
在模型训练的过程中,为观察训练指标的变化,可通过API参数设置指标提取方式,SageMaker会自动过滤指标数值,写入到Amazon CloudWatch监控平台中,您可以在训练过程中及结束后观察指标的变化情况。
指标字典列表配置示例如下:
_metric_definitions = [{'Name': 'Training-loss' , 'Regex': 'loss: ([0-9\.]+)'}]
准备好上述相应参数对象后,即可通过API启动SageMaker训练任务,该部分工作推荐在SageMaker Jupyter Notebook中完成:
# 导入Sagemaker库及Python SDK
import sagemaker as sage
from sagemaker import get_execution_role
import boto3
# 获取会话及相关信息
sess = sage.Session()
client = boto3.client('sts')
account = client.get_caller_identity()['Account']
role = get_execution_role()
# 获取s3存储桶及路径
bucket = sess.default_bucket()
folder = 'ernie'
# 获取区域代码
my_session = boto3.session.Session()
region = my_session.region_name
# 获取存放在ECR中的容器镜像名称
ecr_image = account + ".dkr.ecr." + region + ".amazonaws.com/sm-byo:pd-ernie-pretrain"
from sagemaker.estimator import Estimator
# 输入参数字典
_hyperparameters = {"use_cuda": True,
"is_distributed":False,
"use_fast_executor":True,
"weight_sharing":True,
"in_tokens":True,
"batch_size":8192,
"vocab_path":"./config/vocab.txt",
"num_train_steps":30,
"checkpoints":"./checkpoints",
"save_steps":10,
"ernie_config_path":"./config/ernie_config.json",
"learning_rate":"0.0001",
"use_fp16":False,
"weight_decay":0.01,
"max_seq_len":512,
"skip_steps":5,
"validation_steps": 20}
# 指标提取列表
_metric_definitions = [{'Name': 'Training-loss','Regex': 'loss: ([0-9\.]+)'}]
# 构建SageMaker Estimator
estimator = Estimator(image_name=ecr_image, # 容器镜像
role=role,# 角色
train_instance_type='ml.p3.2xlarge', # 当前训练机型
train_instance_count=1, # 训练机器数量
hyperparameters = _hyperparameters, # 参数传递
metric_definitions = _metric_definitions, # 指标提取
output_path = 's3://{}/{}/'.format(bucket,folder)) # 输出模型存放在s3的路径
# 输入数据在s3路径,构建数据通道字典
train_data = 's3://{}/{}/{}'.format(bucket, folder, 'train')
valid_data = 's3://{}/{}/{}'.format(bucket, folder, 'valid')
data_channels = {'train': sage.session.s3_input(train_data),
'valid': sage.session.s3_input(valid_data)}
# 启动训练
estimator.fit(inputs=data_channels, logs=True)
说明
本示例选用单台ml.p3.2xlarge机型承载训练任务,该机器包含单张Nvidia V100 显卡、8核CPU、61GB内存。更多计算实例类型请参见:https://thinkwithwp.com/cn/sagemaker/pricing/instance-types/
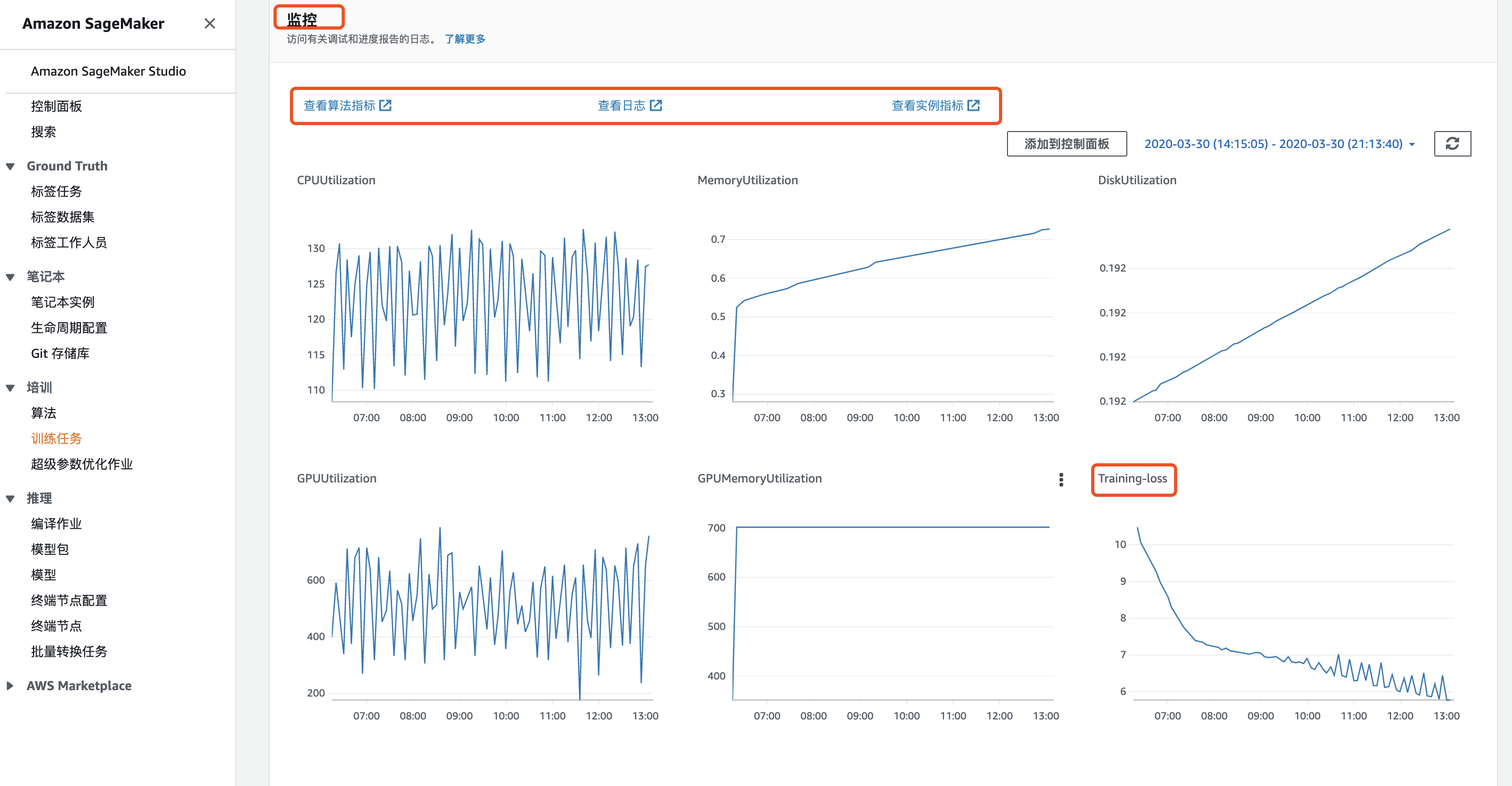
训练过程中,可以通过Amazon CloudWatch实时可视化观察指标变化情况,点击SageMaker控制台对应的训练任务:

下拉至监控界面,可以点击查看算法指标、输出日志和实例指标。图中框选的Trainig-loss即为手动输出至Amazon CloudWatch的指标对象。

训练任务结束后,SageMaker自动将模型文件保存至S3指定路径上,用于后续部署或迭代。

以上就是基于Amazon SageMaker通过自带容器方法实现自定义算法的模型预训练任务的基本介绍,该方法同样适用于基于其他第三方或自带框架的自定义任务的实现,关于通过自带容器方式实现模型优化和部署,敬请关注该系列博客的后续内容。
本篇作者