亚马逊AWS官方博客
在 Amazon SageMaker notebook 实例上使用 R 编程
Original URL: https://thinkwithwp.com/cn/blogs/machine-learning/coding-with-r-on-amazon-sagemaker-notebook-instances/
不少AWS客户已经开始将流行的开源统计计算与图形软件R全面引入大数据分析与数据科学领域。Amazon SageMaker则是一项全托管服务,可帮助用户快速完成机器学习(ML)模型的构建、训练与部署。Amazon SageMaker消除了机器学习流程中各个步骤带来的繁重负担,显著降低了高质量模型的开发门槛。2019年8月,Amazon SageMaker宣布在所有区域都预装R内核。这项功能开箱即用,且预先安装有reticulate库,负责为Amazon SageMaker Python SDK提供R接口,帮助用户直接从R脚本中调用Python模块。
在本文中,我们将了解如何在Amazon SageMaker notebook实例上使用R实现机器学习模型的训练、部署与预测结果检索。此模型将根据鲍鱼贝壳上的圈纹数量预测鲍鱼的年龄。大家可以使用reticulate工具包实现R与Python对象之间的翻译,Amazon SageMaker则提供无服务器环境,用于机器学习模型的大规模训练与部署。
要完成本篇文章,大家需要对R拥有基本了解,并熟悉以下 tidyverse软件包: dplyr, readr, stringr以及 ggplot2。
创建一个带有R内核的Amazon SageMaker notebook实例
要创建一个预装R内核的Amazon SageMaker notebook实例,我们需要完成以下操作步骤:
我们可以根据需要选择实例类型与存储大小创建一个notebook实例。此外,请注意选择身份与访问管理( Identity and Access Management,简称IAM)角色,保证您能够运行Amazon SageMaker并拥有对项目中使用的Amazon Simple Storage Service(Amazon S3)存储桶的访问权限。另外,大家也可以选择VPC、子网以及Git库(如果需要的话)。关于更多详细信息,请参阅创建IAM角色。
- 在确认notebook的当前状态为
InService后,选择Open Jupyter。
- 在Jupyter环境中,通过New下拉菜单选择R。


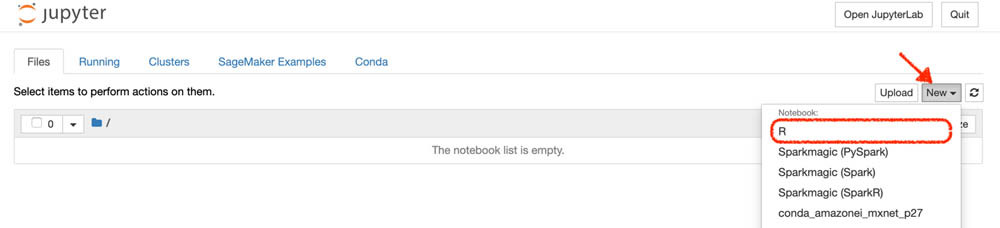
Amazon SageMaker中的R内核使用 IRKernel软件包,并包含140多个标准工具包。关于为Amazon SageMaker Jupyter notebook实例创建自定义R环境的更多信息,请参阅为Amazon SageMaker创建持久自定义R环境。
在创建新notebook时,大家应该会在notebook环境的右上角看到R徽标,徽标下方则为R内核。这表明Amazon SageMaker已经成功为当前notebook启动R内核。
在Amazon SageMaker上通过R实现端到端机器学习
本文中的示例notebook可通过Using R with Amazon SageMaker GitHub repo中获取。
接下来加载reticulate库并导入sagemaker Python模块。详见以下代码:
在模块加载完成后,使用R中的$ 替代了Python中的 .。
创建并访问数据存储
Session类负责通过Amazon SageMaker对以下boto3资源进行操作:
在本用例中,我们为Amazon SageMaker创建一个默认S3存储桶。使用 default_bucket函数创建一个名为sagemaker-<aws-region-name>-<aws account number>的S3存储桶,详见以下代码:
指定IAM角色的ARN,以允许Amazon SageMaker访问该S3存储桶。大家可以选择创建notebook时使用过的同一IAM角色,详见以下代码:
下载并处理数据集
我们的模型使用来自UCI机器学习库的 Abalone数据集。下载相关数据并开始探索性数据分析。使用 tidyverse软件包读取数据、绘制数据并将其转换为适用于Amazon SageMaker的ML格式,详见以下代码。
下表为输出结果。
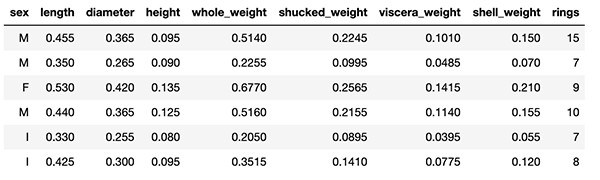
输出结果中的sex属于一种因子数据类型,但其目前属于字符数据类型(F为雌性、M为雄性、I为幼体)。将变量sex转换为一个因子数据类型,并使用以下代码查看数据集的统计摘要:
以下截屏为上述代码片段的输出结果,此代码片段提供了abalone数据框的统计摘要。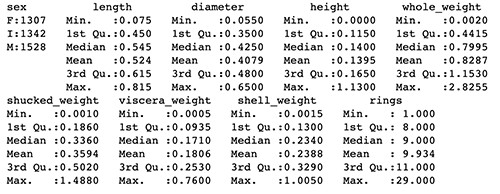
摘要中显示, height的最小值为0。大家可以使用以下代码与库绘制不同性别值的rings (即文章开头提到的贝壳圈数)与 height之间的关系,从而直观了解哪些鲍鱼的 height值为0。
下图为数据绘出的图。

图中显示出多个异常值:2个height为0的幼体鲍鱼,以及数个height远超平均水平的雌性与雄性鲍鱼。要过滤掉这2个height为0的幼体鲍鱼,请使用以下代码:
为模型训练准备数据集
本模型需要3个数据集:训练数据集、测试数据集以及验证数据集。大家需要完成以下操作步骤:
- 将变量sex转换为虚拟变量 (Dummy Variable),而后将目标rings移动至第一列:
Amazon SageMaker算法要求目标位于数据集的第一列。
下表是输出结果。
- 全部数据样本中,有70%被用于进行ML算法训练,其余30%则被进一步拆分成两个部分,一部分用于测试、一部分用于验证:
现在,我们可以将训练与验证数据上传至Amazon S3,从而进行模型训练。请注意,对于CSV文件训练时,XGBoost算法会假定目标变量位于第一列中,且CSV没有列名称。对于CSV文件推理时,该算法则假定CSV输入中不存在列名称。以下代码不会将列名称保存在CSV文件中。
- 以.csv格式将训练与验证数据集写入至本地文件系统当中:
- 将2套数据集上传至S3存储桶中的data“目录”内:
- 为Amazon SageMaker算法定义Amazon S3输入类型:
训练模型
Amazon SageMaker使用容器Docker来进行训练。要训练XGBoost模型,请完成以下操作步骤:
- 在您所用区域的Amazon Elastic Container Registry (Amazon ECR)当中指定训练容器,详见以下代码:
- 定义一个Amazon SageMaker Estimator,它可以训练容器化的任意算法。在创建Estimator时,请使用以下参数:
- image_name – 在训练中使用的容器镜像
- role – Amazon SageMaker服务角色
- train_instance_count – 在训练中使用的EC2实例数量
- train_instance_type – 在训练中使用的EC2实例类型
- train_volume_size – 在训练过程中用于存储输入数据的Amazon Elastic Block Store (Amazon EBS)存储卷的容量大小(单位为GB)
- train_max_run – 训练超时(单位为秒)
- input_mode – 算法支持的输入模式
- output_path – 用于保存训练结果(包括模型工件与输出文件)的Amazon S3位置
- output_kms_key – 用于加密训练输出结果的AWS Key Management Service (AWS KMS)密钥
- base_job_name – 训练作业的名称前缀
- sagemaker_session – 负责管理与Amazon SageMaker API间交互的
Session对象
Python中的None相当于R中的NULL。
- 指定 XGBoost超参数 并进行模型拟合。
- 将训练轮数设置为100,这也是在Amazon SageMaker之外使用XGBoost库时的默认值。
- 根据当前时间戳指定输入数据与作业名称。
在训练完成之后,Amazon SageMaker会将模型的二进制文件(gzip压缩文件)复制至指定的Amazon S3输出位置。使用以下代码以获取完整的Amazon S3路径:
部署模型
Amazon SageMaker为用户提供一个预测入口(Endpoint),我们可以使用HTTPS请求通过安全、简单API调用以完成模型部署。要将训练完成的模型部署在ml.t2.medium实例上,请输入以下代码:
使用模型进行预测
现在,大家可以使用测试数据进行预测。请完成以下操作步骤:
- 通过为预测入口(Endpoint)指定
text/csv与csv_serializer,将以逗号分隔的文本传递为JSON格式,具体参见以下代码: - 删除目标列,并将前500个行数据转换为没有列名称的矩阵:
本文只使用500行数据,以避免超出预测入口(Endpoint)上限。
- 预测并将其转换成以逗号分隔的字符串:
- 将预测出的圈数与测试数据集的列绑定:
下表所示为代码的输出结果,其将predicted_rings添加至abalone_test表当中。请注意,您的实际代码输出可能与此不同,因为步骤2中“为模型训练准备数据集”阶段内的数据集训练/验证/测试拆分属于随机拆分,所以您的拆分结果很可能与本示例有所区别。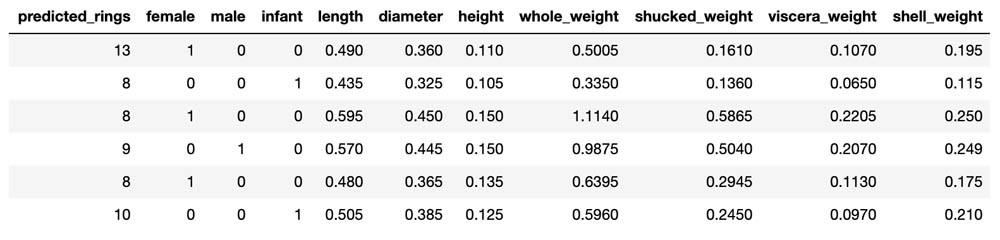
删除预测入口(Endpoint)
在模型使用完成之后,请删除预测入口(Endpoint)以避免产生不必要的部署成本。具体参见以下代码:
总结
本文引导大家完成了一个端到端机器学习项目,全面涵盖数据收集、数据处理、模型训练、将模型部署为端点、使用所部署模型进行推理等各个步骤。关于为Amazon SageMaker Jupyter notebook实例创建自定义R环境的更多信息,请参阅为Amazon SageMaker创建持久自定义R环境。关于Amazon SageMaker上的R notebook示例,请参阅Amazon SageMaker示例GitHub repo。大家也可以参考开发者指南上的《Amazon SageMaker R用户指南》以了解关于通过R使用Amazon SageMaker各项功能的详细信息。此外,也推荐大家访问AWS机器学习博客获取关于Amazon SageMaker以及其他AWS AI与机器学习服务的最新消息及更新内容。