亚马逊AWS官方博客
基于 AWS 无服务器架构的大语言模型应用构建 (工程篇)
基于 AWS 无服务器架构的大语言模型应用构建,分为上下篇两部分,此为下篇(工程篇),我们会从工程实现角度介绍如何借助 AWS 无服务器架构实现构建知识问答机器人场景。在上篇(理论篇)中,重点介绍了此应用构建时涉及到的技术背景和理论知识。
大语言模型应用场景研究
本篇以构建知识问答机器人场景为例,来展示大语言模型在实际应用时的思路和做法。
引入知识库
当构建者开始着手在业务场景中设计知识问答机器人时,常常预期机器人可以在公开域(Open-Domain)和私域(Closed-Domain)两个场景下均能表现良好。大语言模型是通过巨大的语料库训练出来的模型,掌握了不少知识,那么为什么我们还需要知识库呢?这常常是因为知识问答机器人除了闲聊,还需要提供专业知识的任务,而这些专业知识,大语言模型不太可能完全通过公开数据集学习的到。同时考虑到知识问答机器人在私域领域下需要提供权威的回答,并且有时需要提供依据(比如链接)等。比如以下场景:
- 游戏行业,解答玩家关于游戏的人物道具特性、玩法规则等;
- 手机或者电器行业,解答用户的配置详情,功能限制,使用方法等;
- 其他通用的场景:回答公司内部的 IT/行政/HR 的知识,比如怎么报销,怎么设置打印机,怎么请假,怎么使用内部系统等。
再结合一个亚马逊云科技最新发布的服务 AWS Clean Rooms 为例,提问“AWS Clean Rooms 的收费规则是什么?”这是一个比较细节深入的专业性问题,我们看下某主流大语言模型的回答,特点是,回答冗长,没有抓住重点信息。
当我们通过某种方式引入知识库相关内容时,如下述示例:

再次以相同的问题进行提问,可以看到回答精炼了也精准了不少,因为在知识库的加持下,不相关的知识被过滤掉了。

这种设计还有一个亮点,就是工程实现十分轻便。当有知识需要更新时,直接更新目标知识库即可,不需要因为知识的修正反复对大语言模型进行训练/微调。
概念流程图
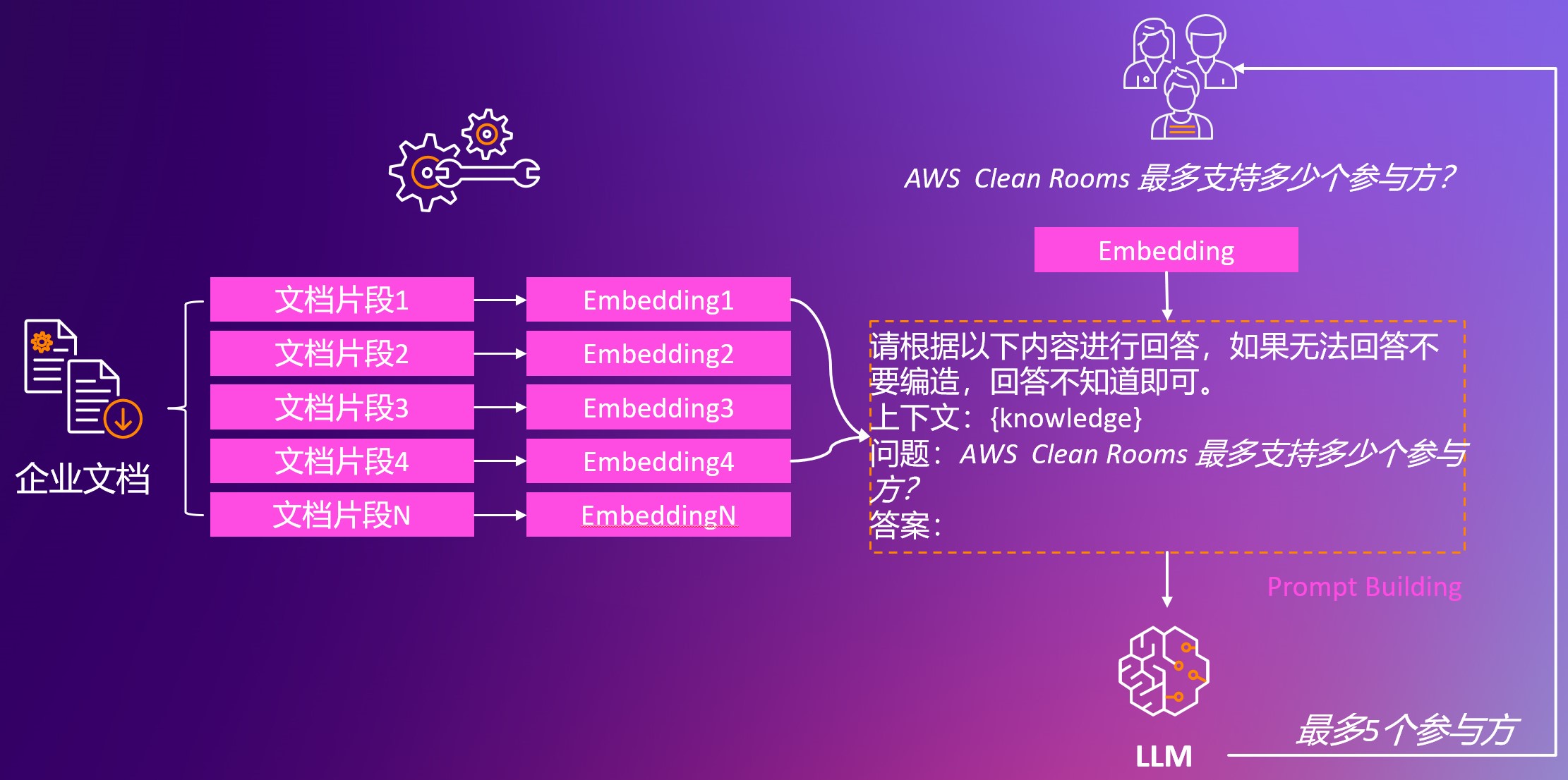
在这个知识问答机器人场景概念流程图中,我们总体分成左侧离线部分和右侧在线流程部分。左侧的离线部分,企业文档被切分成文档片段,通过对文本进行向量化的模型处理,所有的知识被向量化,此时倒排索引自动构建,无需额外处理,再通过向量数据库索引起来,供后续在线流程中进行向量检索召回。
向量化(Embedding)
Embedding 的过程,是把数据集合映射到向量空间,进而把数据进行向量化的过程。Embedding 的目标,就是找到一组合适的向量,来刻画现有的数据集合,以通过距离比较的方式来找到最相似的数据。
下图为该方案下的将文本通过向量化模型向量映射的效果展示:

右侧的在线流程部分,会对用户的输入向量化,进行向量检索,同时可以结合 OpenSearch BM25 的倒排检索结果,再把多路召回的结果作为 context 融合到 prompt 中,最后输入到大语言模型。大语言模型经过整合再回复给用户。以上就是大语言模型和知识库结合的一个流程展示。
通用需求观察
该场景在实际业务模式下,有通用的需求观察,我们总结为以下几点:
1. 交互形式为会话风格,支持一定程度的上下文多轮对话。不仅作为单纯的搜索,需要有对知识进行一定总结的能力。
2. 生成内容具备一定的规范和风格,比如文明礼貌,价值观正确,符合现实,长度适中,多语言支撑能力。
3. 性能稳定,能够支撑线上业务,成本可控,方便不断迭代。
3.1 成本可控:基础设施能够随着调用量进行弹性伸缩 ;私有化部署大语言模型对商业大语言模型的 API 进行替代。
3.2 方便迭代,因为真实用户输入和反馈的收集对问答机器人的回答效果有很大帮助,比如对这些用户输入做一些打标,基于用户反馈去调整知识库。
大语言模型应用构建
架构图
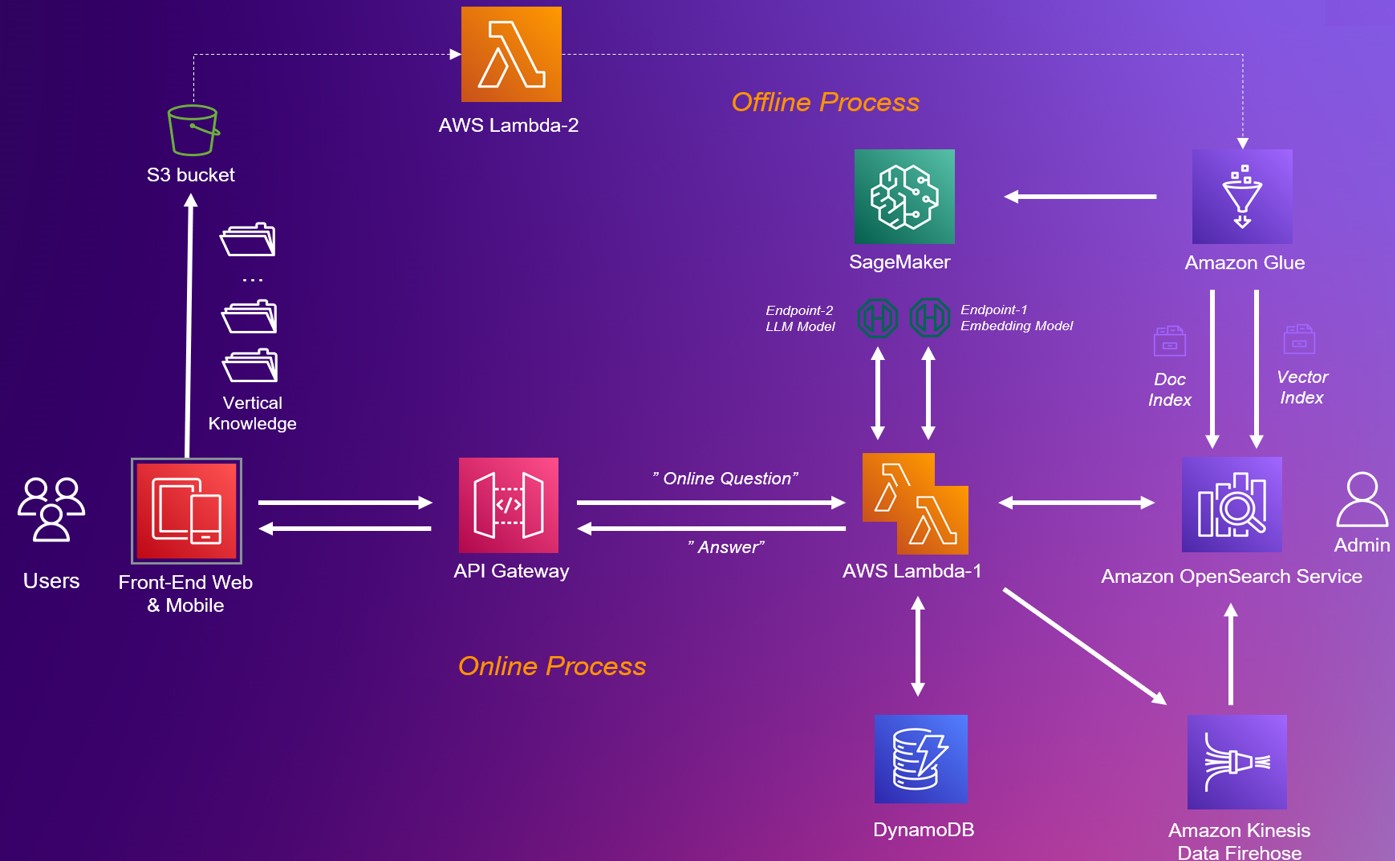
无服务架构设计
无服务架构的优势简单总结为四点:不需要预置资源、自动扩展能力、按用量付费、原生高可用和安全性。
服务和功能介绍
Amazon Glue
Amazon Glue 是一项无服务器数据集成服务。此架构下主要利用了 Amazon Glue for Python Shell 功能来运行作业,作业使用的底层无服务器资源可根据数据规模动态调整。当知识库文档上传至 S3 后,S3 的 event notification 功能通过触发 lambda 函数来触发 Glue 作业的运行,该 Glue 作业会调用 embedding 模型,将知识库的知识向量化后存入向量数据库中,此方案中的向量数据库由 Amazon OpenSearch 支持。
AWS Lambda
函数即服务(Function-as-a-Service),用户在前端发出请求,lambda 会根据用户的输入进行多路召回,包括语义向量召回,倒排召回等,再整合到 prompt 给到 LLM,最后反馈给客户。
Amazon OpenSearch
Amazon OpenSearch 是一项托管服务,可满足客户的分析和搜索业务需求。在此方案中提供三方面的价值:
支撑 KNN 的检索能力
k 最近邻(k-NN)是一种非参数的惰性学习分类技术,用于根据与其最相似的点对数据点进行分类。它使用测试数据对未分类的数据点进行“有根据的猜测”。k-NN 模型不做任何假设,它是纯数据驱动的,这就是它是非参数的原因。该算法也不进行任何泛化,因此在使用该模型时涉及的训练很少。这就是为什么它被称为惰性学习模型。适用于 Amazon OpenSearch 的 k-NN 让您可以在向量空间中搜索点,并通过欧氏距离或余弦相似度找到这些点的“最近邻”。
支撑基于 BM25 的倒排检索和精准匹配检索
OpenSearch 使用称为 BM-25 的概率排名框架来计算相关性分数。如果一个独特的关键字在文档中出现得更频繁,BM-25 会为该文档分配更高的相关性分数。
OpenSearch 提供通过多样的 Query 类型,特别是 Match_phrase 来实现精准匹配:分词结果必须在 text 字段分词中都包含 ,⽽且顺序必须相同,⽽且必须都是连续的。
支撑日志检索,构建排查能力
从 OpenSearch Discover 入口可以轻松查看每条记录的返回,包括用户 query 内容,LLM 构建的 Prompt 项目,召回的知识内容等。对于回答不理想的场景也可以轻松定位到是哪个环节有待改善。

Amazon SageMaker
Amazon SageMaker 是一个端到端的机器学习平台,SageMaker 支持您的模型开发全流程,从数据准备,数据处理,算法构建,模型训练,超参调优,模型部署与监控等环节,SageMaker 都提供了相应的功能帮助算法工程师们专注于业务和模型本身,提高开发效率。
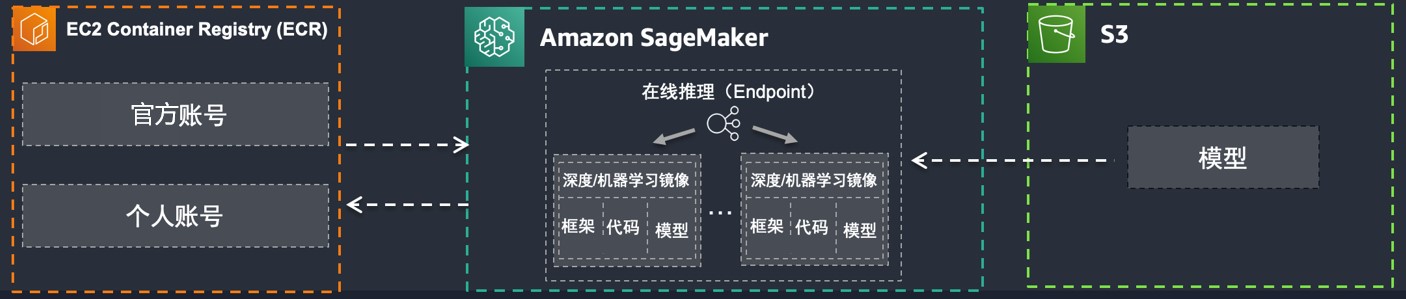
SageMaker 与 Hugging Face 深度合作,通过 JumpStart 一站式的 Portal 平台提供众多模型的一键集成和部署服务,SageMaker 使用流行的开源库维护深度学习容器(DLC),用于在 AWS 基础设施上托管大型模型,例如 GPT、T5、OPT、BLOOM 和 Stable Diffusion。借助这些 DLC,您可以使用 DeepSpeed、Accelerate 和 FasterTransformer 等第三方库,使用模型并行技术对模型参数进行分区,以利用多个 GPU 的内存进行推理。

在此方案中,SageMaker 主要用于部署和 Host 大语言模型和向量模型,其中也拉取了 DJL/LMI 镜像以便在 SageMaker 上获得优化的加速体验:

其他 AWS 服务
Amazon DynamoDB,NoSQL 键值数据库,用于管理用户 session 内的上下文,请求进来之前会从这里获取以前的会话记录,结果返回前会把这次的会话更新进去。
Amazon Kinesis Data Firehose,用于把整个交互的日志中做 ETL 加载到 Amazon OpenSearch,供后续分析,也方便后续迭代。
方案效果
未引入知识库时,完全依赖大语言模型在公开域的表现问询“AWS MSK(Amazon Managed Streaming for Apache Kafka)与传统的自建比有什么优势?”看到大语言模型不知道 AWS MSK 所代表的含义:

引入知识库之后,我们看到问答机器人可以准确的回答出相关领域问题:

如果您对该方案感兴趣,可以参考 Amazon Open Search+大语言模型的智能问答系统来基于亚马逊云环境快速构建,也欢迎联系我们的客户经理,获取更多专家支持。
引申阅读
基于 AWS 无服务器架构的大语言模型应用构建(理论篇):https://thinkwithwp.com/cn/blogs/china/building-llm-applications-based-on-aws-serverless-architecture-theory/
OpenSearch KNN:https://opensearch.org/docs/latest/search-plugins/knn/index/
Deep learning containers for large model inference:https://docs.thinkwithwp.com/sagemaker/latest/dg/large-model-inference-dlc.html