亚马逊AWS官方博客
通过 Amazon Forecast 建立 MLOps 体系,实现 AI 赋能的预测自动化
本文探索了如何创建无服务器架构的机器学习运营(MLOps)管道,并借此开发及可视化由Amazon Forecast构建的预测模型。由于机器学习(ML)工作负载需要规模伸缩,因此我们需要打破不同相关方之间的孤岛,最终获取业务价值。MLOps模型能够保证数据科学、生产与运营团队最大程度利用自动化工作流进行无缝协作,保证顺利部署预测模型并持续对其实施有效监控。
与软件开发中的DevOps模型类似,机器学习中的MLOps模型亦有助于跨机器学习工具与框架构建代码与集成。您可以对数据管道进行自动化、运营以及监控,且完全无需重写自定义代码或者重新设计现有基础设施。MLOps帮助我们扩展了现有分布式存储与处理基础设施,让机器学习模型的大规模部署与管理更加简单易行。此外,MLOps还能够立足单一中央位置跟踪并可视化组织内所有模型随时间漂移的情况,同时实现自动数据验证策略。
MLOps通过持续集成、持续部署与持续训练,将DevOps与机器学习领域的最佳实践充分结合起来,帮助我们简化生产环境中机器学习解决方案的生命周期。关于更多详细信息,请参阅《机器学习Lens:AWS良好架构框架》白皮书。
在以下各节中,我们将了解如何利用MLOps管道(包括Amazon Forecast、AWS Lambda以及AWS Step Functions)构建、训练及部署时间序列预测模型。为了对所生成的预测结果进行可视化,大家还需要使用AWS提供的无服务器分析服务,例如Amazon Athena与Amazon QuickSight。
解决方案架构
在本节中,我们将部署MLOps架构,将其作为蓝图以自动执行Amazon Forecast的使用与部署。这里提供的架构与示例代码可帮助大家为时间序列数据构建MLOps管道,进而生成预测以定义未来业务策略、切实满足客户需求。
您可以使用AWS托管服务构建这套无服务器架构,意味着您可以直接创建机器学习管道,且无需分神于基础设施管理工作。这不仅降低了数据集的迭代难度,同时也使您得以通过特征与超参数调优实现性能优化。
下图所示,为我们在本文中将要使用的各组件。

在上图中,我们使用一套Step Functions工作流进行无服务器MLOps管道部署,其中各Lambda函数将被整合起来以编排Amazon Forecast的各设置步骤,最终将结果导出至Amazon Simple Storage Service (Amazon S3)。
这套架构中包含以下组件:
- 时间序列数据集已被上传至Amazon S3云存储下的
/train目录(前缀)当中。 - 文件上传将触发 Lambda,由 Lambda 启动由Step Functions状态机构建的MLOps管道。
- 该状态机将一系列 Lambda 函数组合在一起,用于在Amazon Forecast中构建、训练及部署机器学习模型。我们将在下一节中讨论关于状态机Lambda组件的更多详细信息。
- 在日志分析方面,状态机使用Amazon CloudWatch捕捉各项Forecast指标。这里,当源Amazon S3存储桶的
/forecast目录中存在最终预测结果时,我们将使用Amazon Simple Notification Service (Amazon SNS) 发送邮件通知。这条机器学习管道还将在/history目录中保存所有旧有预测结果。 - 最后,我们使用Athena与QuickSight提供当前预测的可视化表示。
在本文中,我们将使用UCI机器学习repo中的“个人家庭用电量”数据集。这套时间序列数据集汇总了各客户家庭的每小时用电情况,外加工作日的用电量峰值。您可以根据需要替换样本数据,以用于支持其他用例。
现在,大家已经对解决方案的基本架构有所了解,接下来可以探索状态机中各Lambda组件的具体情况了。
使用Step Functions构建MLOps管道
在上一节中,我们提到Step Functions状态机是整个MLOps管道自动化架构的核心。下图所示,为使用状态机部署的工作流。

如上图所示,来自Step Functions工作流的各Lambda函数具体如下(这些步骤还凸显出Lambda函数与Amazon S3中所保存的params.json文件内参数间的映射):
- Create-Dataset – 创建一个Forecast数据集。关于此数据集的信息将帮助Forecast理解如何消费数据以训练模型。
- Create-DatasetGroup – 创建一个数据集组。
- Import-Data – 将您的数据导入至数据集组内的某一数据集中。
- Create-Predictor – 使用参数文件指定的预测范围创建预测器。
- Create-Forecast – 创建预测并启动一项指向Amazon S3的导出作业,包括在参数文件中指定的分位数。
- Update-Resources – 创建必要的Athena资源,并将导出的预测结果转换为与输入数据集相同的格式。
- Notify Success – 当作业完成时,通过向Amazon SNS发出消息发送一条邮件提醒。
- Strategy-Choice – 根据参数文件,检查Forecast各资源是否被删除。
- Delete-Forecast – 删除预测结果并保留导出数据。
- Delete-Predictor – 删除预测器。
- Delete-ImportJob – 在Forecast中删除
Import-Data作业。
在Amazon Forecast当中,数据集组属于一种抽象,其中包含特定预测集合所使用的全部数据集。不同数据集组之间不共享信息。要尝试使用各种替代方案,您可以创建一套新的数据集组并在对应的数据集中做出变更。关于更多详细信息,请参阅数据集与数据集组。在本用例中,工作流会面向数据集组导出一套目标时间序列数据集。
完成上述步骤后,工作流将触发预测器训练作业。预测器的实质是一套经过预测训练的模型,负责基于时间序列数据执行预测。关于更多详细信息,请参阅预测器。
在预测器训练完成后,工作流会使用该预测器触发创建预测结果。在预测创建期间,Amazon Forecast会首先托管预测模型、执行推理,而后在完整的数据集上训练该模型。关于更多详细信息,请参阅Forecasts。
在预测结果成功导出之后,状态机将通知邮件发送至部署过程中指定的地址处。预测结果导出完成后,Update-Resources步骤将重新格式导出的数据,以便Athena与QuickSight能够轻松使用这些结果。
大家可以替换Lambda函数中各个步骤的算法与数据集,借此重复使用MLOps管道以构建、训练以及部署更多其他机器学习模型。
先决条件
在部署这套架构之前,大家需要首先完成以下准备工作:
- 安装Git。
- 在您的系统上安装AWS Serverless Application Model (AWS SAM) CLI。关于更多操作说明,请参阅安装AWS SAM CLI。请使用以下代码,保证您安装的是最新版本:
向您的AWS账户部署示例架构
为了简化部署流程,本文将通过AWS CloudFormation提供完整的基础设施即代码架构方案,您可以在Forecast Visualization Automation Blogpost GitHub repo上轻松获取相关代码。另外,我们还将使用AWS SAM部署这套解决方案。
- 克隆这套Git repo,详见以下代码:


大家可以通过Forecast Visualization Automation Blogpost GitHub repo获取相关代码。
- 导航至刚刚创建完成的
amazon-forecast-samples/ml_ops/visualization_blog目录,并输入以下代码以启动解决方案部署:

在这一部分,AWS SAM将构建一套CloudFormation模板变更集。几秒之后,AWS SAM会提示您部署CloudFormation栈。
- 为栈部署提供参数。本文使用以下参数;您也可以直接使用默认参数:


AWS SAM创建一套AWS CloudFormation变更集,并要求确认。
- 输入
Y。
关于变更集的更多详细信息,请参阅使用变更集更新栈。
在成功部署之后,大家将看到以下输出结果:
- 在AWS CloudFormation控制台的Outputs选项卡上记录
ForecastBucketName的值,我们将在测试步骤中使用该值。

测试示例架构
以下步骤概述了如何测试示例架构。要触发Step Functions工作流,大家需要将两个文件上传至新创建的S3存储桶:参数文件,以及时间序列训练数据集。
- 在克隆GitHub repo所在的同一目录中输入以下代码,将其中的YOURBUCKETNAME 部分替换成我们之前在AWS CloudFormation Outputs选项卡中复制到的值:

以上命令将复制Lambda函数用于配置您Forecast API调用的参数文件。
- 输入以下代码,执行时间序列数据集上传:

- 在Step Functions仪表板中,找到名为DeployStateMachine-<random string>的状态机。
- 选择该状态机以查看工作流的执行情况。


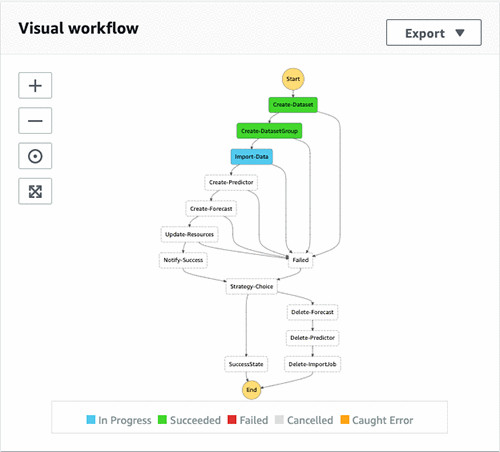
如以上截屏所示,全部成功执行的步骤(Lambda函数)都处于绿色框体当中,蓝色框体表示步骤仍在进行当中,而所有无颜色框体则代表正等待执行的步骤。完成整个工作流中的所有步骤最多可能需要2个小时。
在工作流成功完成之后,您可以前往Amazon S3控制台并找到包含以下目录的Amazon S3存储桶:

参数文件params.json 中保存有从Lambda函数中调用Forecast API的属性。这些参数配置中包含的信息包括预测类型、预测器设置以及数据集设置,此外还有预测域、频率以及维度。关于API操作的更多详细信息,请参阅Amazon Forecast Service。
现在,您的数据已经存在于Amazon S3当中,大家可以对结果进行可视化处理了。
使用Athena与QuickSight分析预测数据
要完成整个预测管道,我们还需要对数据进行查询与可视化。Athena是一项交互式查询服务,可使用标准SQL轻松分析Amazon S3中的数据。QuickSight则是一项基于云的快速商务智能服务,可通过数据可视化轻松帮助您获取洞见。要开始分析数据,您首先需要使用Athena作为数据源并将数据摄取至QuickSight当中。
如果您刚刚接触AWS,请设置QuickSight以创建一个QuickSight账户。如果您已经拥有AWS账户,请订阅QuickSight服务以创建相应的新账户。
如果这是您第一次在QuickSight上使用Athena,则需要向QuickSight授权权限以使用Athena查询Amazon S3。关于更多详细信息,请参阅配合Amazon QuickSight使用Athena时的权限不足问题。
- 在QuickSight控制台上,选择New Analysis。
- 选择New Data Set。
- 选择Athena。
- 在New Athena data source窗口中的Data source name部分,输入一项名称,例如
Utility Prediction. - 选择Validate connection。
- 选择Create data source。

这时次显示Choose your table 窗口。
- 选择Use custom SQL。

- 在Enter custom SQL query窗口中,输入您的查询名称,例如
Query to merge Forecast result with training data。 - 在查询文本框中输入以下代码:



现在,您可以选择将数据导入SPICE或者直接对数据执行查询了。
- 选择任一选项,而后选择Visualize。
您将在 Fields list之下看到以下字段:
- item_id
- target_value
- timestamp
- type
导出的预测结果将包含以下字段:
- item_id
- date
- 要求的分位数 (P10, P50, P90)
其中的type字段包含预测窗口的分位数类型(P10, P50, P90) ,而history字段将作为训练数据的分位数。这一过程将通过自定义查询完成,以确保在历史数据与导出的预测结果之间保持统一的历史界线。
大家可以使用CreateForecast API可选参数调用ForecastType,借此实现分位数自定义。在本文的用例中,您可以在Amazon S3中的params.json文件下完成这项配置。
- 在X axis部分,选择timestamp。
- 在Value部分,选择target_value。
- 在Color部分,选择type。
在参数当中,我们指定了72小时范围。要对结果进行可视化,大家需要以每小时一次的频率对时间戳字段进行聚合。
- 在timestamp下拉菜单中,选择Aggregate与Hour。


以下截屏所示,为您的最终预测结果。图中所示为分位数P10、P50m以及P90的预测结果,以及与之对应的概率预测。

总结
每个组织都能够从更准确的预测当中受益,从而更好地预测产品需求、优化计划与供应链动态等等。预测需求是一项艰巨的任务,而机器学习技术能够显著缩小预测与现实之间的差距。
本文向大家展示了如何创建可重复、基于AI的自动预测生成流程。大家还了解到如何使用无服务器技术建立机器学习运营管道,并使用托管分析服务通过数据查询与可视化以提取重要洞见。
大家也可以使用Forecast进行更多运营操作。关于能耗预测的更多详细信息,请参阅使用Amazon Forecast进行准确的能耗预测。关于分位数的更多详细信息,请参阅Amazon Forecast现已支持以您选定的分位数生成预测。如果本文对您有所帮助或者启发,请在评论区中分享您的感受与疑问。您也可以直接使用并扩展GitHub repo中提供的代码。