亚马逊AWS官方博客
利用 AWS Step Function 自动扩展 Redshift 集群
谈到公有云如何帮助我们降低总体拥有成本,人们首先想到的会是:
1. 按需获取资源,按使用时间付费。
2. 通过使用托管化的服务,降低运维成本。
以上两点都非常正确,然而,托管化的服务充其量只能简化某个单独服务的运维工作,而在实际的运维场景中,我们时常会遇到更复杂的运维工作流,这些工作流通常会涉及到对多个系统组件的操作,并且需要有严格的先后流程控制、故障回滚及错误告警等功能。如果以人工的操作来执行这类工作流,操作步骤繁复不说,更有可能由于某个环节的人工操作失误,导致系统出现意外的故障。
为此,AWS 云上提供了相关的工作流调度服务 Step Function,帮助我们把这类工作自动化,降低运维负担及人为引入的故障率。当然,Step Function 并不仅仅局限于运维工作的自动化,事实上,AWS Step Functions 让您能够使用可视工作流轻松协调分布式应用程序和微服务的组件。通过使用每个都能执行离散函数的单独组件构建应用程序,让您能够快速扩展和更改应用程序。
本文以一个实际客户的应用场景出发,来介绍如何使用 Step Function 服务,自动化执行一个拥有多个步骤的工作流。
场景介绍
用户使用 DMS 服务将 Aurora 中的数据持续导入到 Redshift 中做后续的分析,随着数据量的增加,需要调整 Redshift 集群的大小来扩展存储的容量,由于 Redshift 集群在调整大小的过程中处于只读的模式,此时 DMS 服务对 Redshift 的增量写入会失败,比较好的做法是先停止 DMS 任务,等到 Redshift 集群调整完毕后再启动,除了通过人力定期观察 Redshift 磁盘的使用量,并在合适的时候调整 Redshift 集群的方式之外,有没有一种无人值守的方式来帮助我们实现自动化的运维工作呢?
下面我们就介绍一种通过 AWS 服务实现上述需求的解决方案,整个方案除了可以保证完全自动化之外,还拥有如下好处:
1. 没有用到 1 台 EC2 实例,完全 Serverless 化,用户无需维护各个组件的可用性,扩展性和相关软件版本。
2. 与 EC2 按时间收费不同,架构中的 Serverless 服务使用按次调用收费,由于不会经常性调整 Redshift 集群大小,各个组件的调用次数有限,相比需要24小时开机运行的 EC2 来说,成本成倍数下降。
3. 由于 AWS 的部分服务提供每个月一定量的免费额度,进一步降低了整个方案的成本,具体如下:
- CloudWatch 每个月前 10 个 Alarm 免费。
- SNS 每个月前 100 万次调用免费。
- Lambda 每个月前 100 万次调用免费。
- Step Function 每个月前 4000 次状态流程转换免费。
我们可以看到,通过更多地使用 AWS 提供的 Serverless 服务,不仅提高了整个系统的自动化程度,降低运维成本,并且在调用不频繁的场景中,能够实现整个方案零成本。
下面我们来看一下整个解决方案的架构设计:
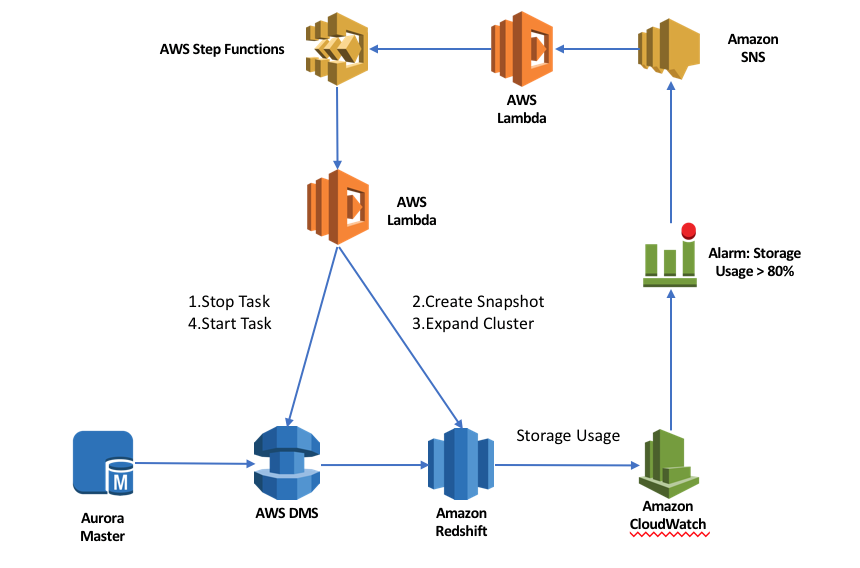
下面是整个方案的工作流程:
1. AWS DMS 实时将 Aurora 的增量数据同步到 Redshift 集群中。
2. CloudWatch 监控 Redshift 的磁盘使用量,并且当使用量超过80%的时候触发告警。
3. SNS 接收告警产生的信息并触发 Lambda 函数。
4. Lambda 函数启动 AWS Step Function 状态机,开始工作流处理。
5. 状态机通过调用 Lambda 函数实现每个状态的处理工作。
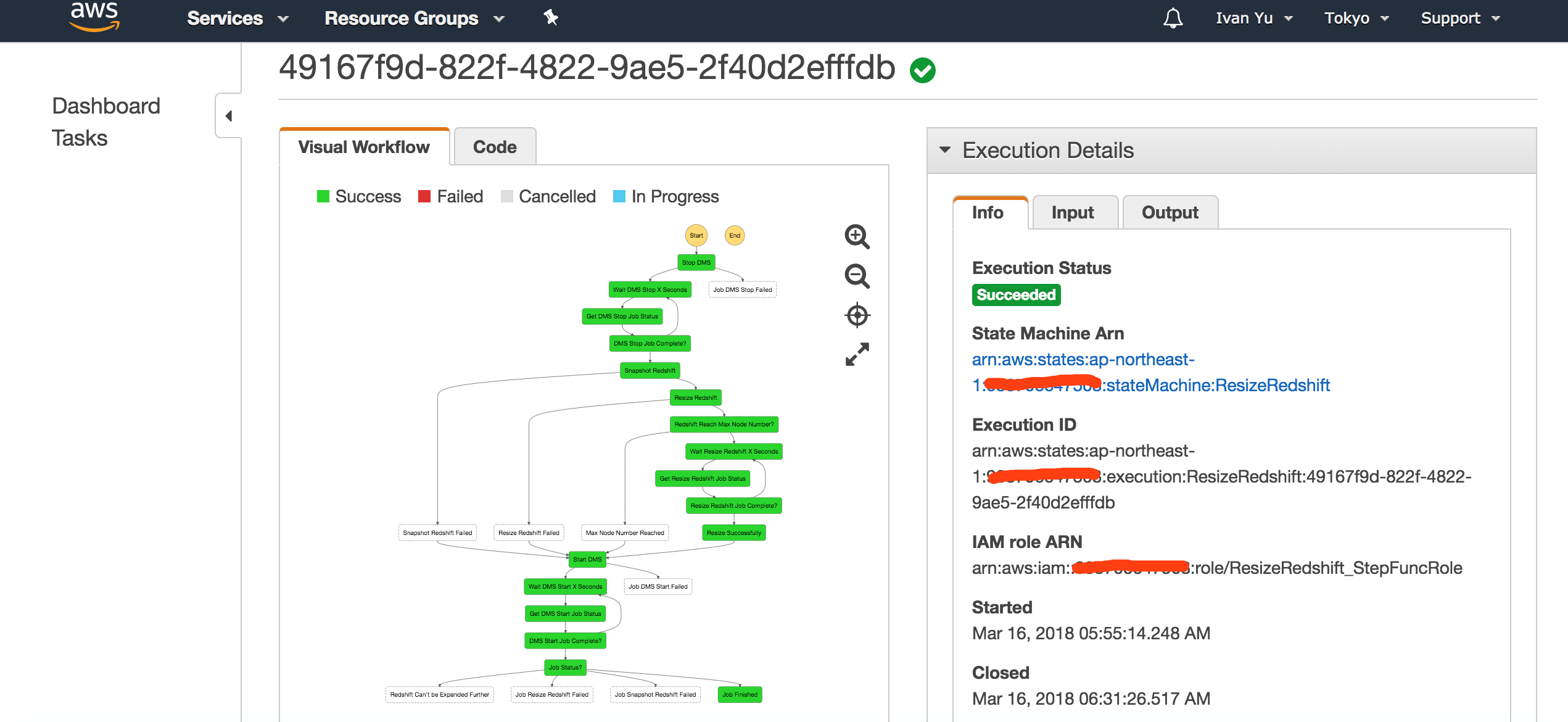
6. 状态机工作流主要包含4个步骤,如下图所示:
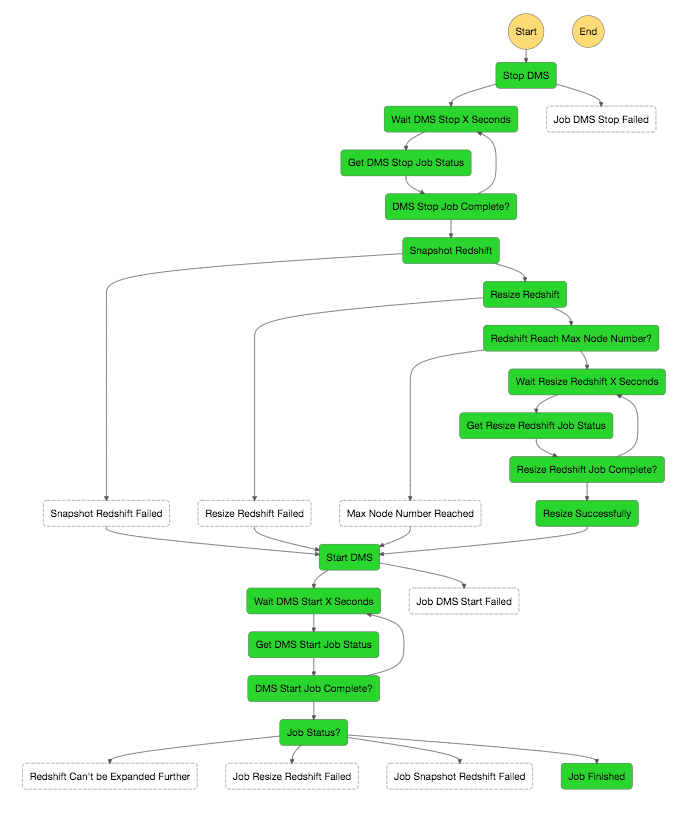
我们来看一下这个 Step Function 的状态机,整个流程十分直观,当状态机启动后,首先会停止正在进行增量备份的 DMS 任务,之后对 DMS 任务的目标 Redshift 集群做一个 Snapshot 快照,然后调整Redshift 集群的大小,最后重新启动 DMS 任务。
相关代码下载:
https://github.com/iwasnobody/RedshiftResize
下面介绍详细的配置过程。
第一步 准备工作:
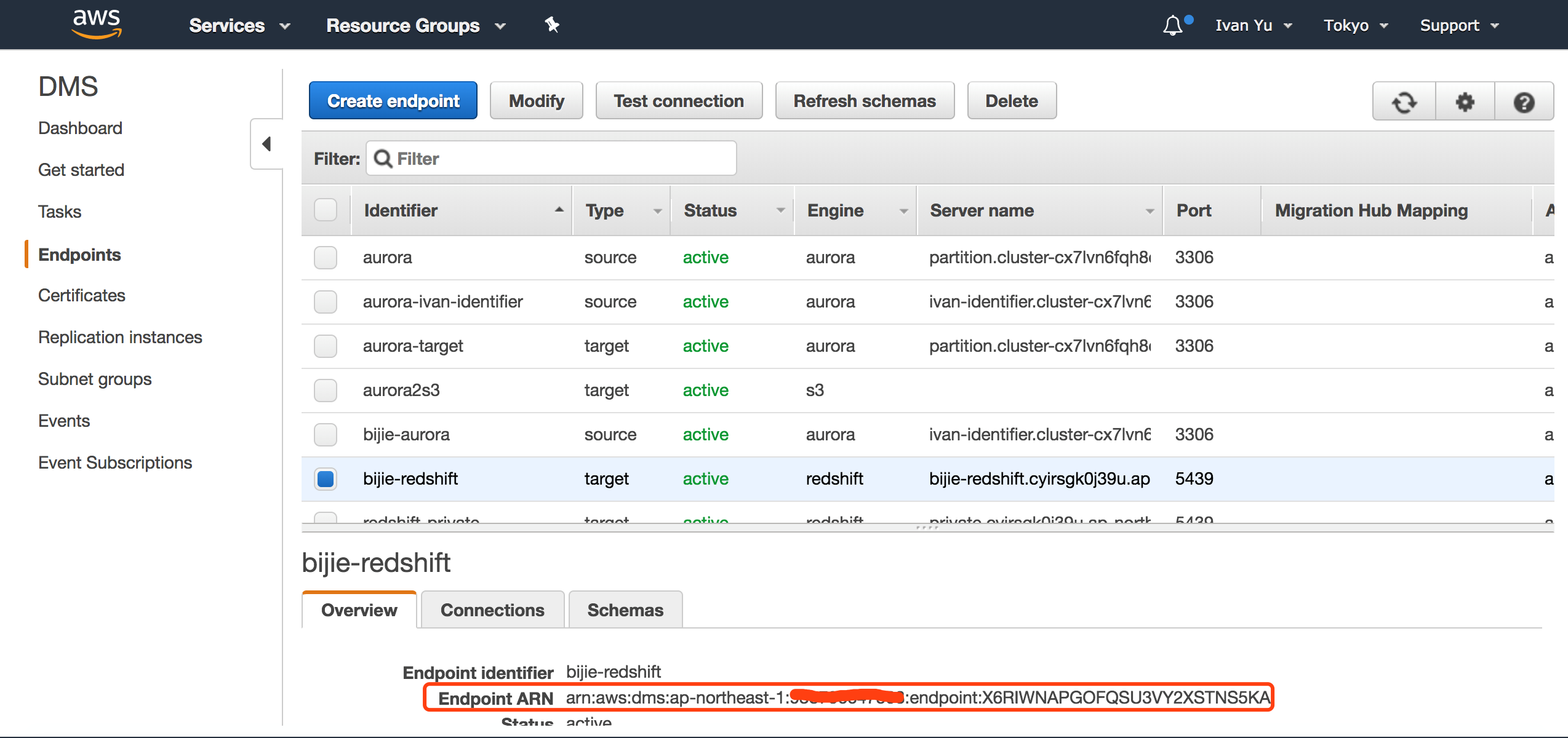
1.获取 DMS 服务中,作为同步任务目标的 Redshift 的 Endpoints ARN。
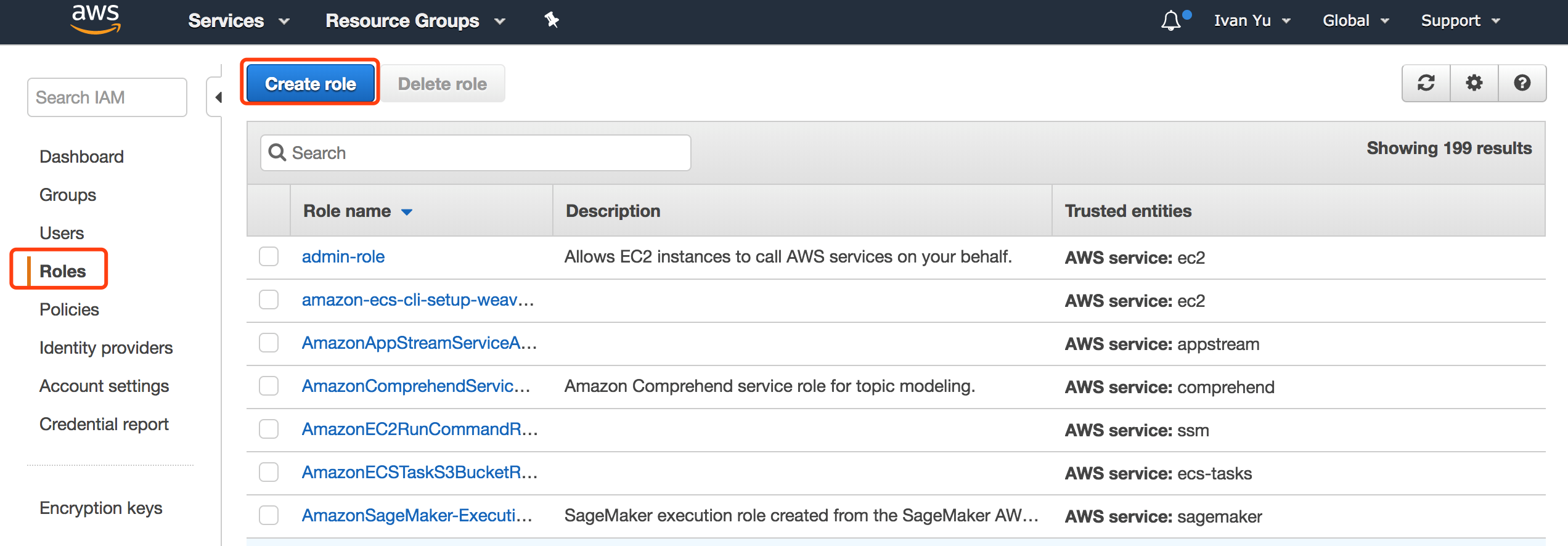
2.创建 Role 供 Step Function 及相关的 Lambda 使用。
首先创建 LambdaAccessStepFuncRole,使得相关 Lambda 能够触发 Step Function 执行任务。

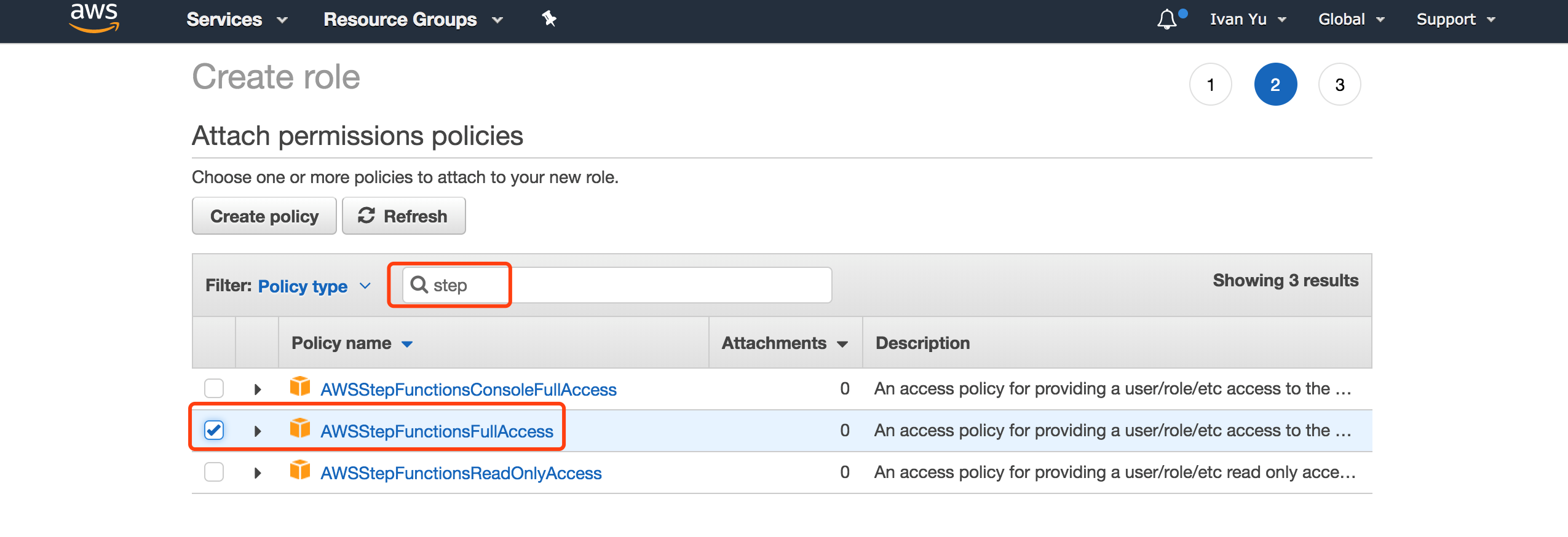

通过相同的方式创建 ResizeRedshift_DMSRole,使得相关 Lambda 能够启停 DMS 任务,调整 Redshift 集群大小。

其中,DMSFullAccess 不是系统内置的 Policy,需要自己创建,下面是该 Policy 的具体设置,即:允许对 DMS 的所有相关操作。

通过相同的方式创建 ResizeRedshift_StepFuncRole,使得 Step Function 能够在执行的某个阶段调用 Lambda 执行相关任务。


第二步 创建 Step Function 中需要调用的 Lambda 函数 ResizeRedshift_StopDMS。

选择之前创建好的 ResizeRedshift_DMSRole。

从 GitHub 上获取 ResizeRedshift_StopDMS.py 代码。
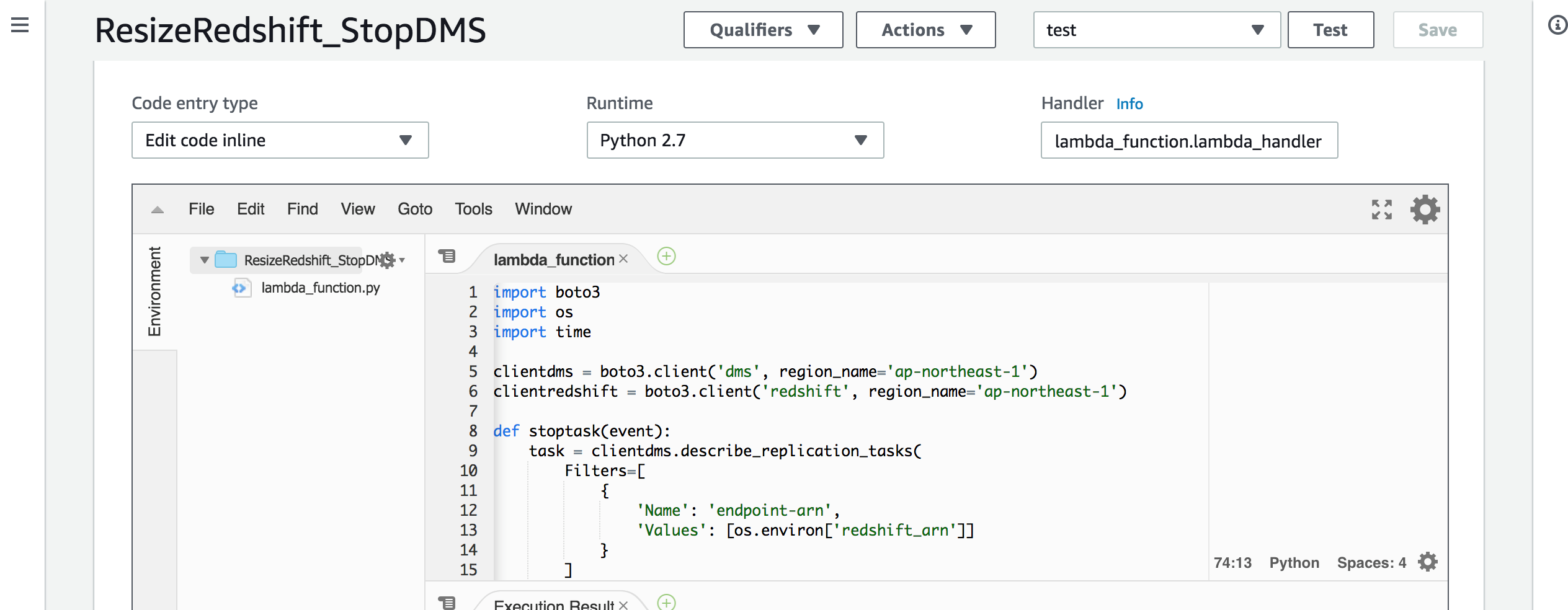
设置 Lambda 执行的环境变量,其中:
redshift_arn 是准备工作中获取的 DMS 任务目标 Redshift 的 Endpoints ARN。
redshift_name 是 DMS 任务的目标 Redshift 集群名称。

第三步 创建 Step Function 状态机。
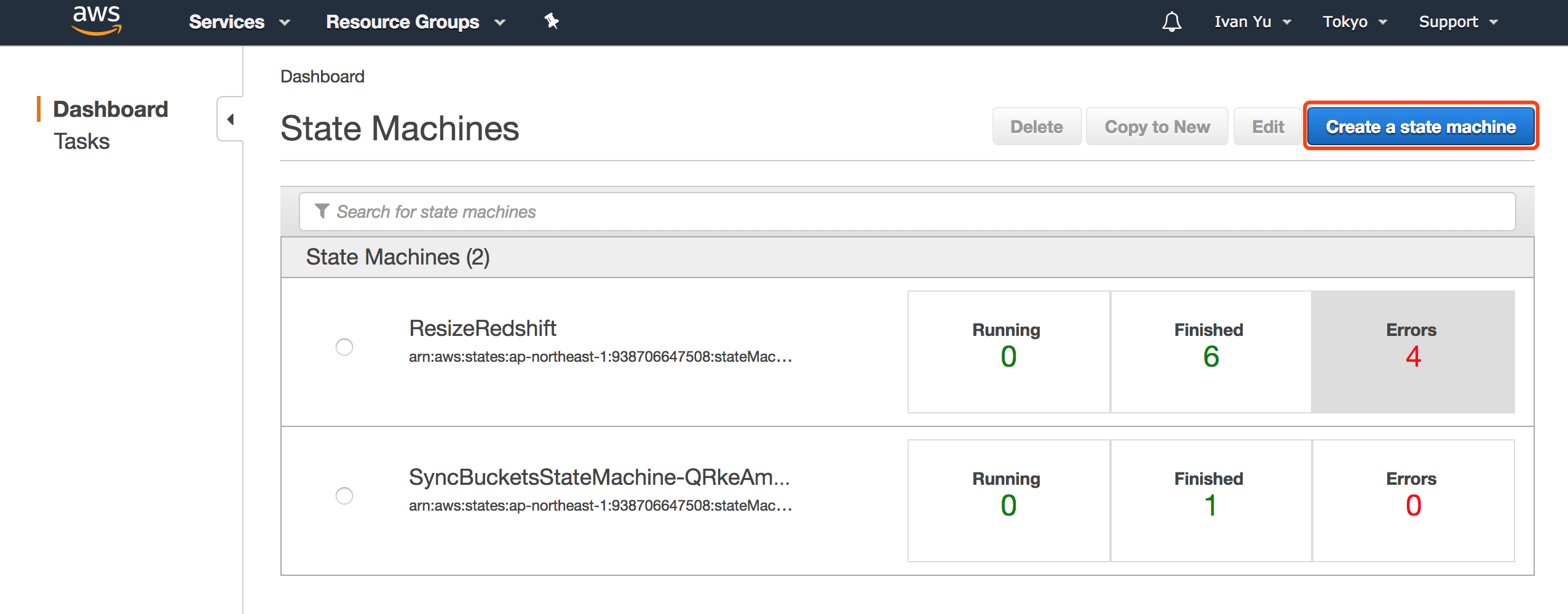
选择之前创建好的 ResizeRedshift_StepFuncRole。

从 GitHub 上获取 StepFunction 代码,注意需要将代码中的 Lambda Arn 改写成上面创建好的 ResizeRedshift_StopDMS Lambda 函数的 Arn。

创建触发 Step Function 状态机的 Lambda 函数 TriggerStepFunc,选择之前创建的 LambdaAccessStepFuncRole。

从 GitHub 上获取 TriggerStepFunc 代码。

设置 Lambda 执行的环境变量,其中:
StepFuncArn 为 Step Function ResizeRedshift 的 Arn。

第四步 创建 SNS Topic,用于触发刚刚创建的 TriggerStepFunc Lambda 函数。


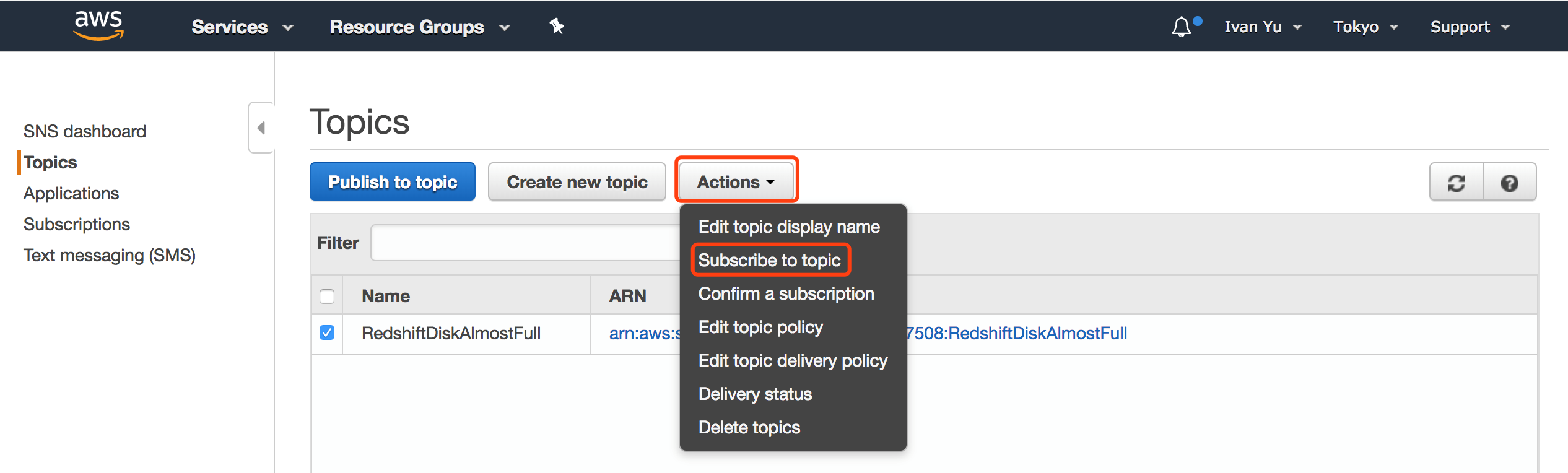

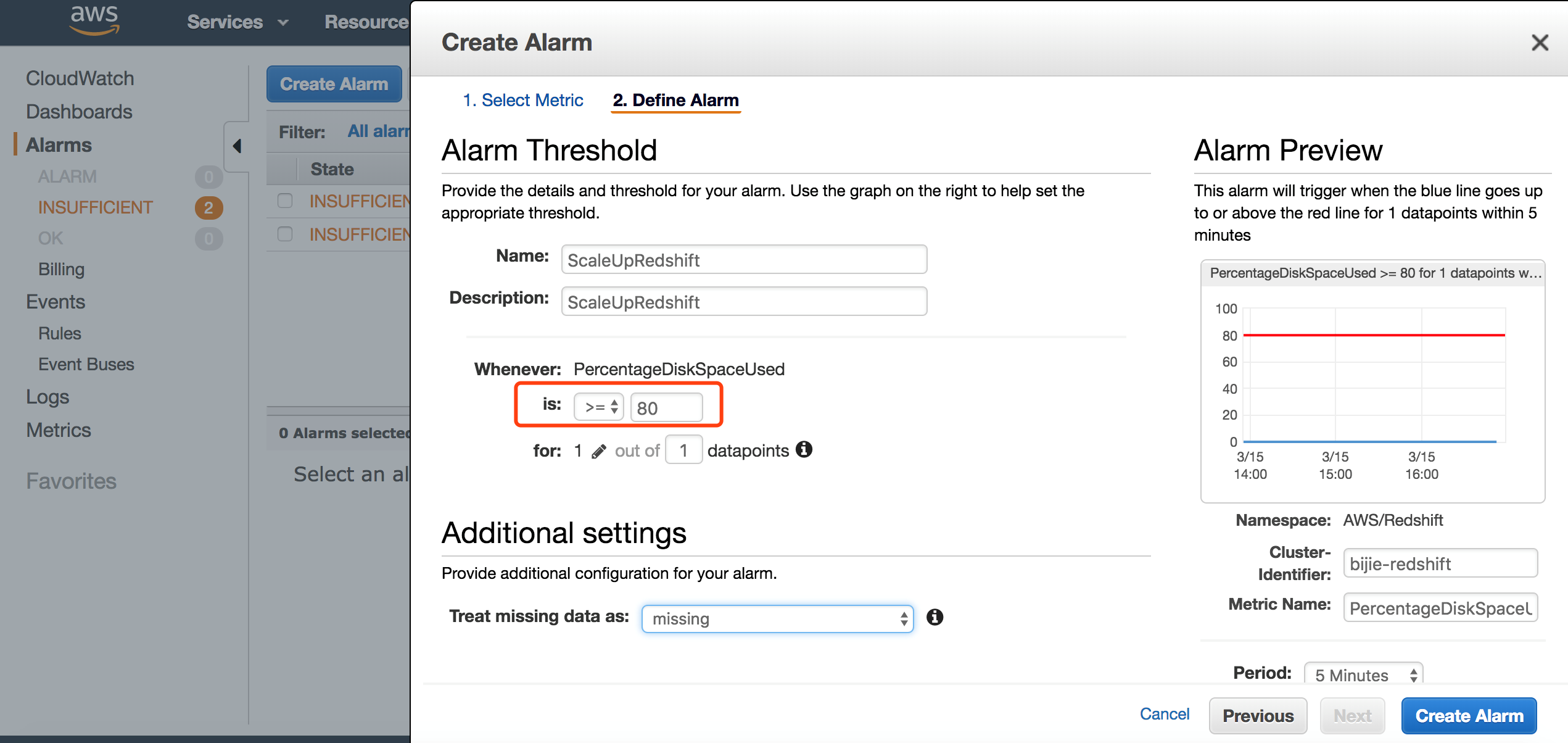
第五步 在 CloudWatch 中创建 Redshift 存储容量的告警。

选择相关 Redshift 集群的 PercentageDiskSpaceUsed。

这里配置当已使用存储大于80%时,触发告警。
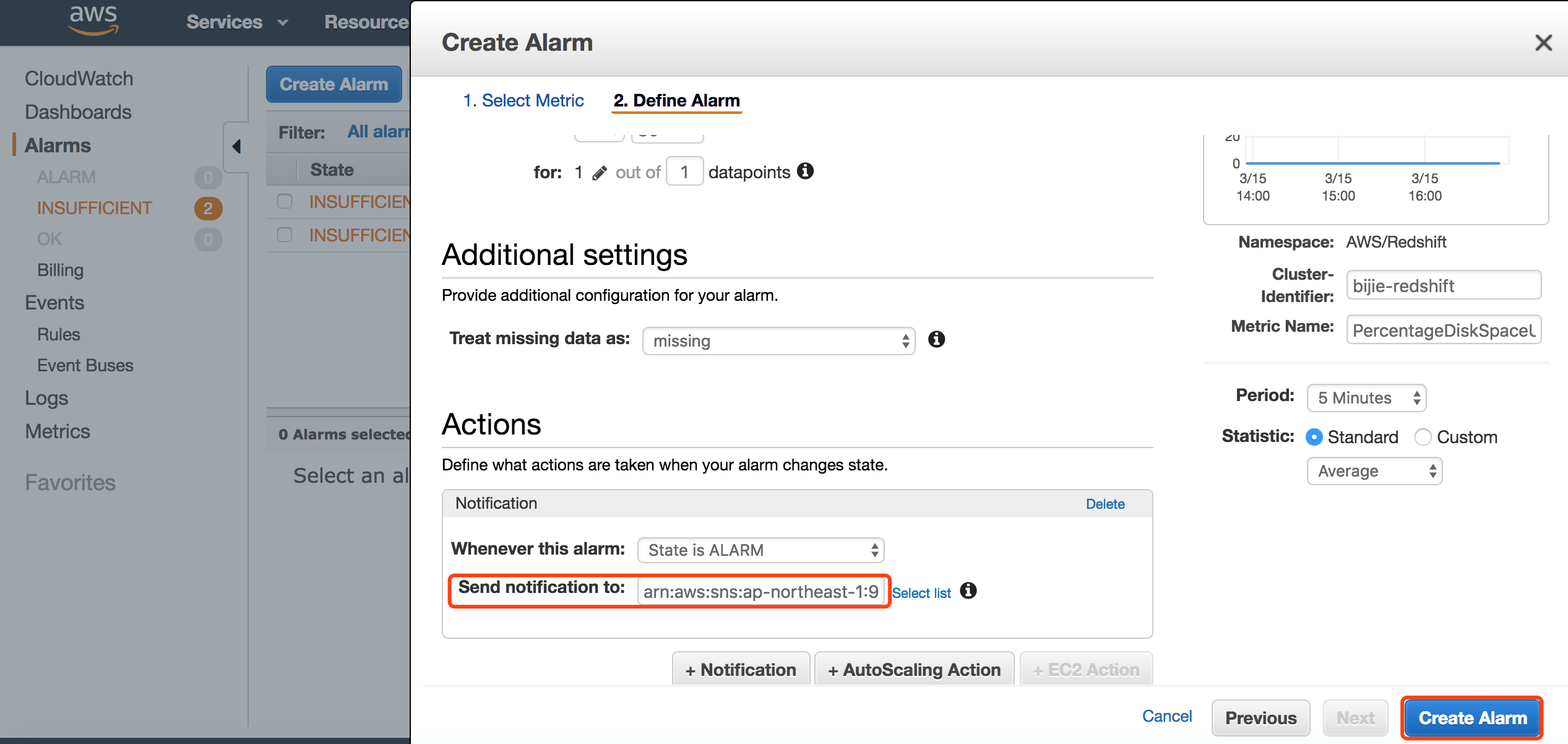
设置告警触发的时候,向已经创建的 SNS 发送消息。
第六步 测试整个流程:
1.进入 SNS,选择手工向 SNS 发送消息,具体的消息内容不重要。


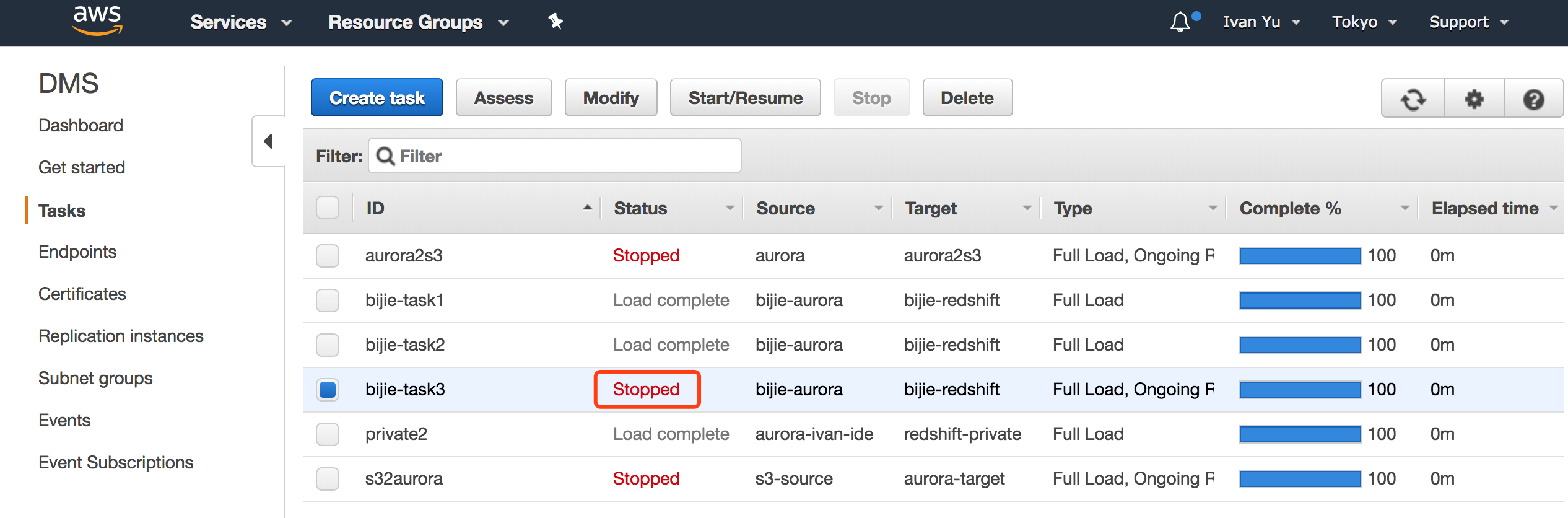
2. 在 Step Function 界面能够看到触发了新的状态机执行。


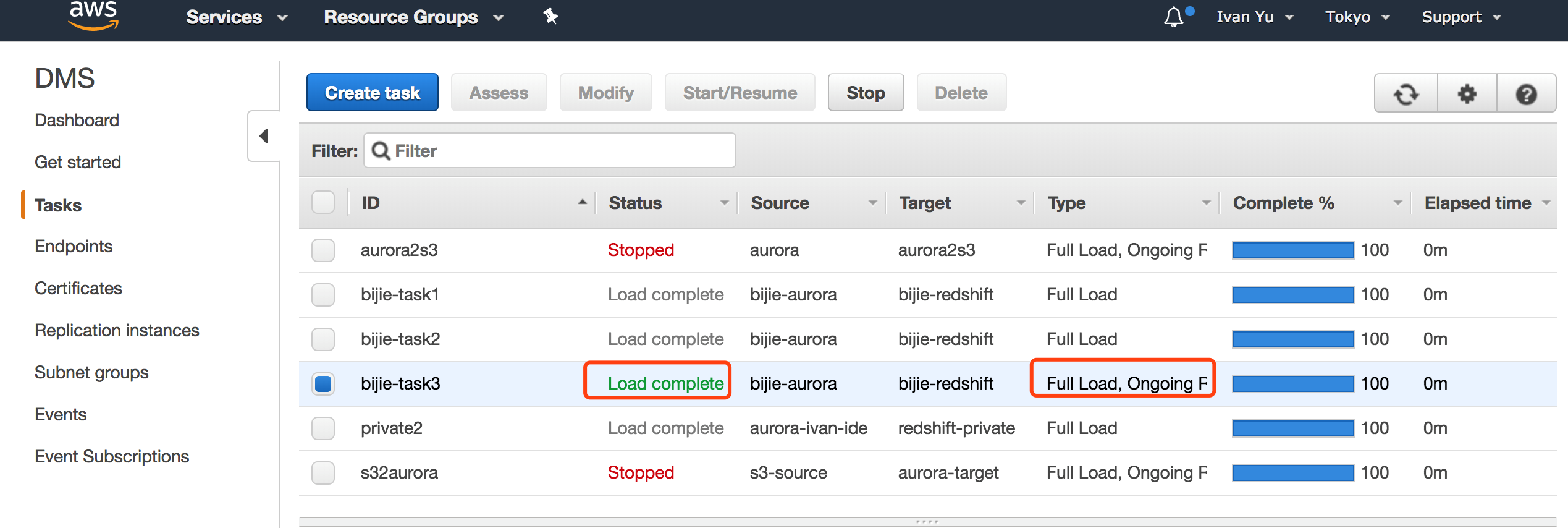
3. 通过 DMS 界面,我们可以看到 DMS 任务已经被停止,在 Redshift 界面,我们可以查看集群扩展的状态。

4. 等到状态机执行成功后,可以看到 DMS 任务被重新启动,并且 Redshift 集群的规模扩展了1倍。

注意事项:
- 由于 Redshift 在调整集群的过程中处于 read only 模式,无法写入新的数据,此时 DMS 无法将 Aurora 的增量更新同步到 Redshfit 中,所以需要停止 DMS 任务,等到 Redshift 集群调整完成后再重新启动 DMS 任务。
- DMS 任务停止期间,Aurora 的增量更新保存在 binlog 中,需要确保 binlog 在 Aurora 中的保存时间大于 DMS 任务停止的时间,下图展示了如何将 binlog 的保存时间设为 24h。
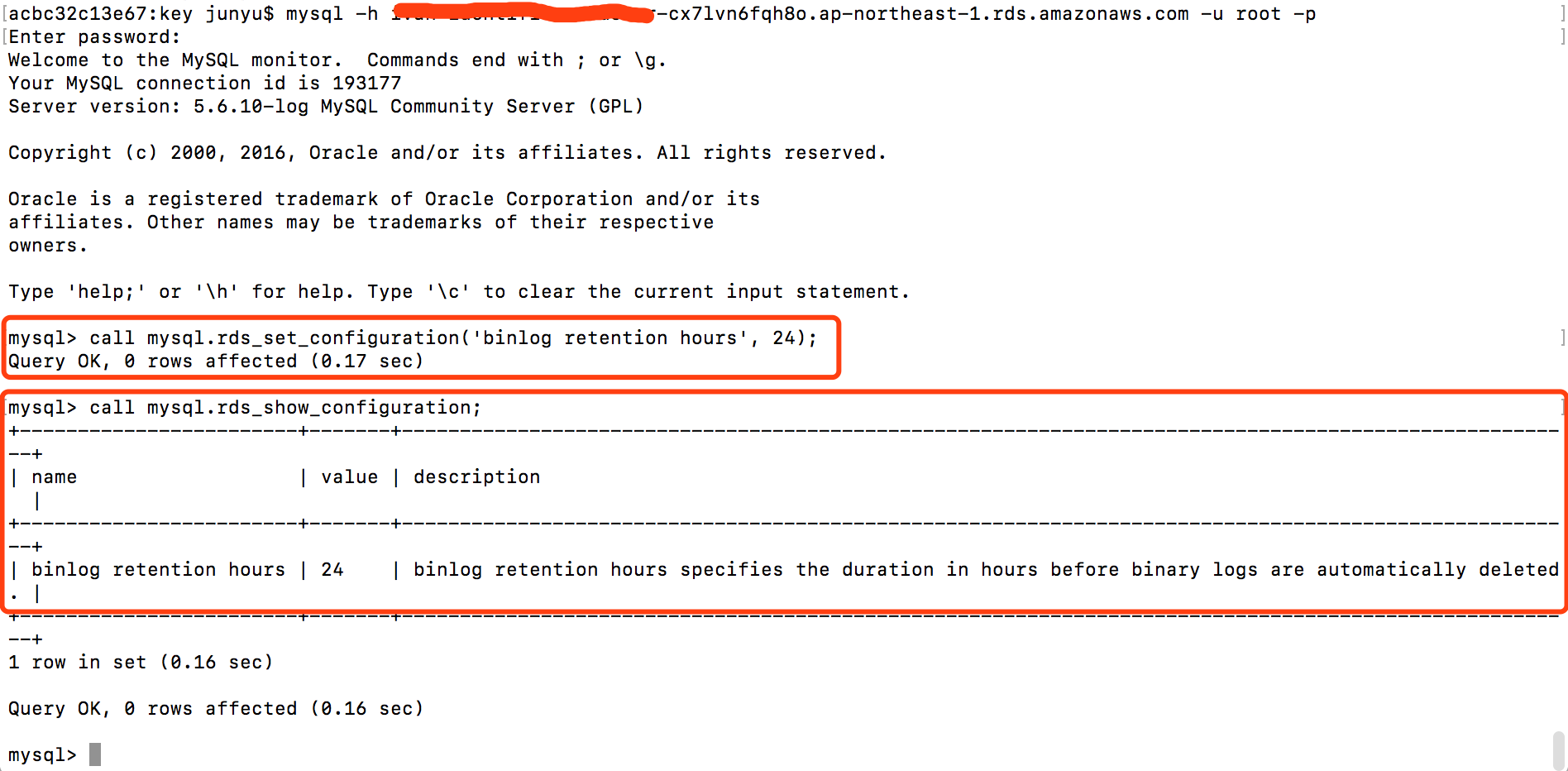 3.具体 binlog 的保存时间设为多长取决于 Redshift 当前的集群规模和数据量,建议如果当前集群规模及数据量较大的情况下,通过 Snapshot 镜像创建测试集群,手工调整测试集群的规模实际测试大致需要的时间。
3.具体 binlog 的保存时间设为多长取决于 Redshift 当前的集群规模和数据量,建议如果当前集群规模及数据量较大的情况下,通过 Snapshot 镜像创建测试集群,手工调整测试集群的规模实际测试大致需要的时间。
 4. 如果希望能够在特定的维护时间窗口调整 Redshift 集群的规模,可以通过 SNS 发送邮件的方式通知运维人员,然后在特定时间手工触发 Step Function 来实现。
4. 如果希望能够在特定的维护时间窗口调整 Redshift 集群的规模,可以通过 SNS 发送邮件的方式通知运维人员,然后在特定时间手工触发 Step Function 来实现。