亚马逊AWS官方博客
AWS Entity Resolution:匹配和链接来自多个应用程序和数据存储的相关记录
随着组织的发展,包含客户、业务或产品信息的记录往往越来越分散,并且跨应用程序、渠道和数据存储相互孤立。由于可以通过不同的方式收集信息,因此出现的问题是存在不同但等效的数据,例如街道地址(“5th Avenue”和“5th Ave”)。结果就是,将相关记录链接在一起以形成统一视图并获得更理想的见解并非易事。
例如,公司希望开展广告活动,以个性化的消息传递吸引多个应用程序和渠道内的消费者。公司通常不得不处理包含不完整或冲突信息的不同数据记录,从而很难匹配记录。
在零售行业,公司必须在其供应链和门店中协调使用多种不同产品代码的产品,例如库存单位(SKU)、通用产品代码(UPC)或专有代码。因此,公司无法快速、全面地分析信息。
解决此问题的一种方法是构建定制的数据解析解决方案,例如与多个数据库交互的复杂 SQL 查询,或者训练机器学习(ML)模型进行记录匹配。但是,这些解决方案需要几个月的时间才能成功构建,需要开发资源,而且维护成本很高。
为了协助解决此问题,我们于今日推出 AWS Entity Resolution,这是一项由 ML 支持的服务,可帮助您匹配和链接存储在多个应用程序、渠道和数据存储中的相关记录。可以在几分钟内开始配置灵活、可扩展且可无缝连接到现有应用程序的实体解析工作流程。
AWS Entity Resolution 提供高级匹配技术,例如基于规则的匹配和机器学习模型,以此协助您准确链接相关的客户信息、产品代码或业务数据代码集。例如,可以使用 AWS Entity Resolution 将最近发生的事件(例如广告点击、放弃购物车和购买)链接到唯一的实体 ID,从而形成客户交互的统一视图;或者,可以使用该服务更全面地跟踪门店中使用不同代码(如 SKU 或 UPC)的产品。
借助 AWS Entity Resolution,您可以提高匹配准确性并保护数据安全,同时最大限度地减少数据移动,因为它可以读取已存在的记录。接下来查看该服务的实际操作。
使用 AWS Entity Resolution
作为分析平台的一部分,我在 Amazon Simple Storage Service(Amazon S3)存储桶中放入一个逗号分隔值(CSV)的文件,其中包含一百万个虚构客户。这些客户来自忠诚度计划,但可以通过不同的渠道(在线、门店内、邮寄)申请,因此可能有多条记录与同一个客户关联。
下面是此 CSV 文件中数据的格式:
我使用 AWS Glue 爬网程序来自动确定文件的内容,并在数据目录中更新元数据表,以便将其用于我的分析作业。现在,我可以在 AWS Entity Resolution 中使用相同的设置。
在 AWS Entity Resolution 控制台中,我选择 开始使用来查看如何设置匹配工作流程。

要创建匹配工作流程,我首先需要使用架构映射来定义自己的数据。

我选择创建架构映射,输入名称和描述,然后选择从 AWS Glue 导入架构的选项。我也可以使用分步流程或 JSON 编辑器定义自定义架构。
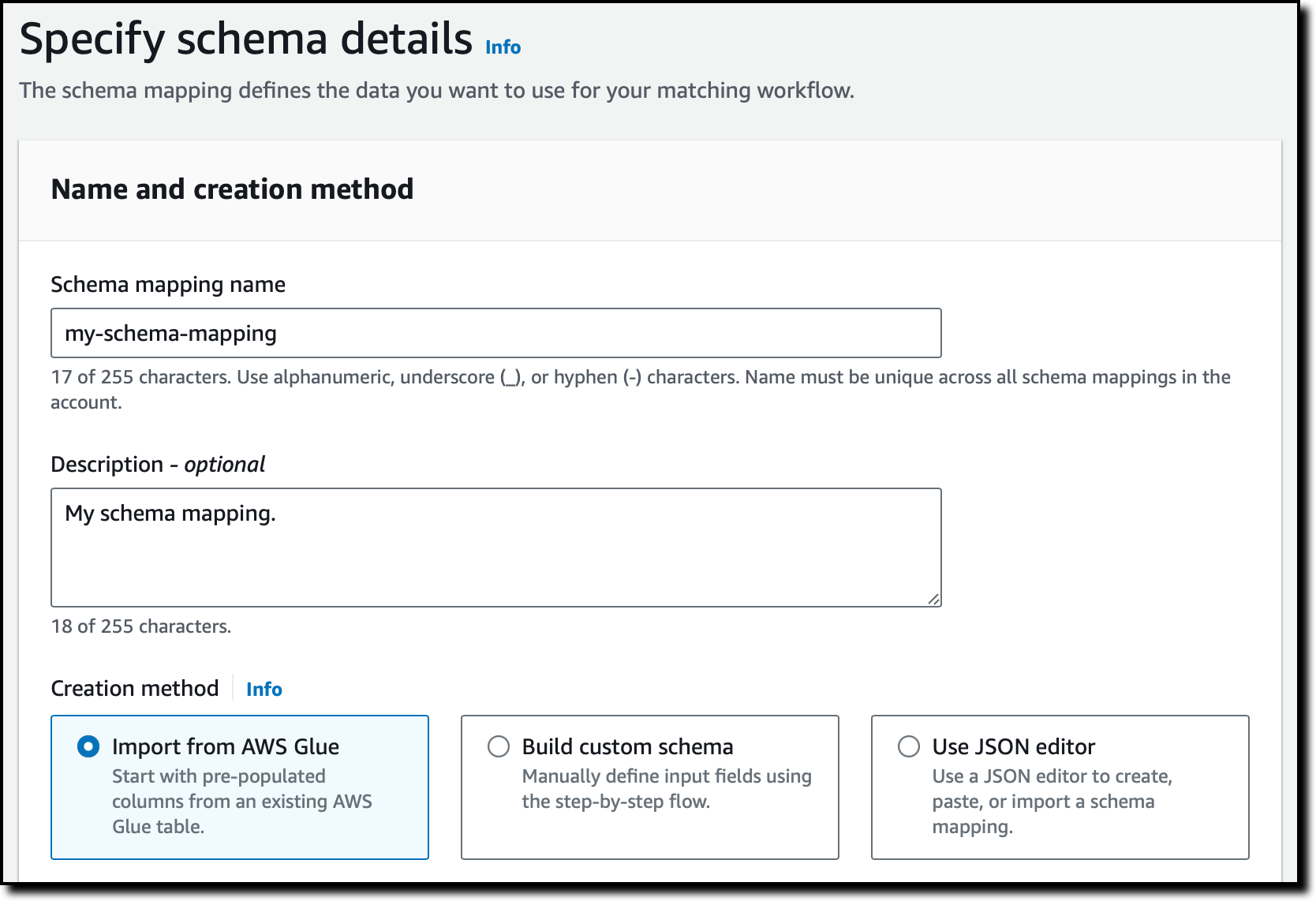
我从两个下拉列表中选择 AWS Glue 数据库和表,以导入列并预填充输入字段。
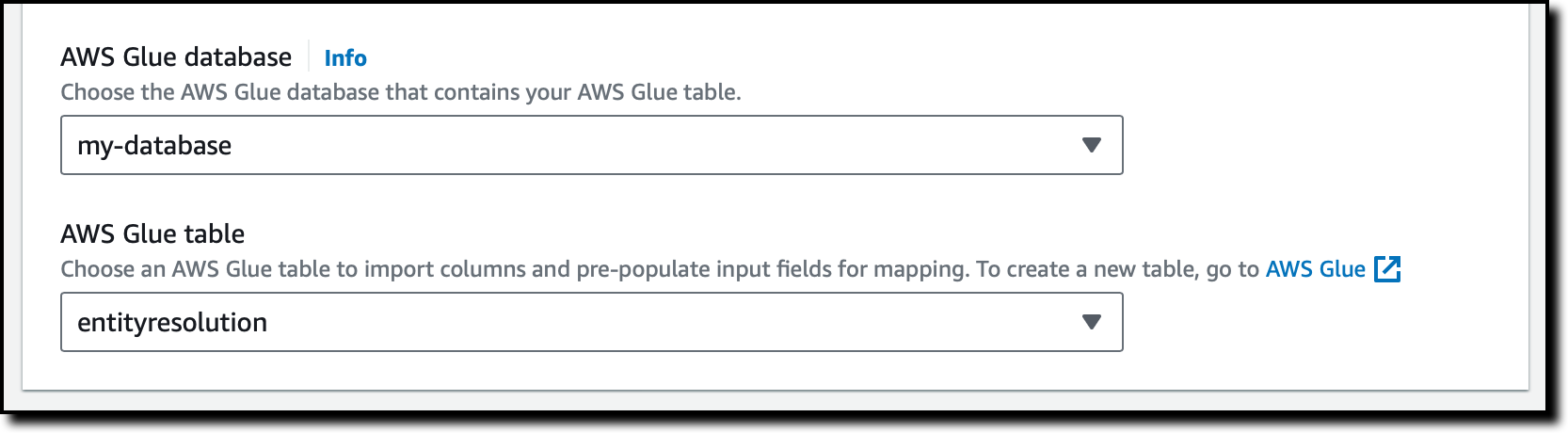
我从下拉列表中选择唯一 ID。唯一 ID 是可以清晰引用每行数据的列。在此案例中,该 ID 是 CSV 文件中的 loyalty_id。

我选择将用于匹配的输入字段。在此案例中,我从下拉列表中选择可用于识别多条记录是否与同一个客户相关的列。如果某些列不是匹配所必需的,但在输出文件中是必需的,我可以选择将它们添加为直通字段。我选择下一步。

我将输入字段映射到它们的输入类型和匹配键。通过这种方式,AWS Entity Resolution 就知道如何使用这些字段来匹配相似的记录。我选择下一步继续。
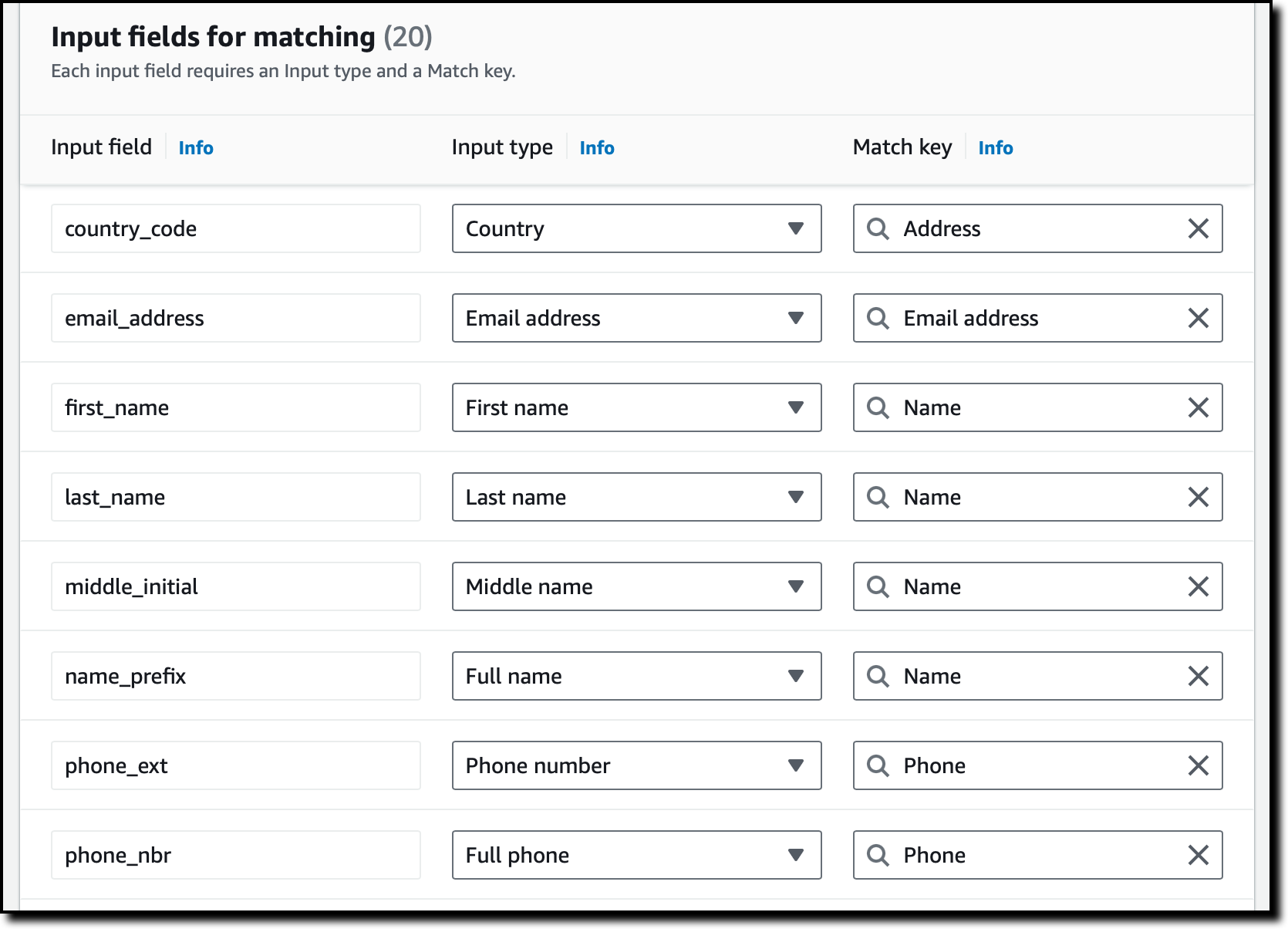
现在,我使用分组来更妥善地组织需要比较的数据。例如,可以将名字、中间名和姓氏输入字段组合在一起并作为全名进行比较。

我也为地址字段创建一个组。

我选择下一步并审查所有配置。然后,我选择创建架构映射。
现在我已经创建架构映射,接下来从导航窗格中选择匹配工作流程,然后选择创建匹配工作流程。

我输入名称和描述。然后,为了配置输入数据,我选择 AWS Glue 数据库和表以及架构映射。

为了让服务有权访问数据,我选择之前配置的服务角色。服务角色提供对输入和输出 S3 存储桶以及 AWS Glue 数据库和表的访问权限。如果输入或输出存储桶已加密,则服务角色还可以授予加密和解密数据所需的 AWS Key Management Service(AWS KMS)密钥的访问权限。我选择下一步。

我可以选择使用基于规则或 ML 提供支持的匹配方法。根据不同的方法,我可以使用手动或自动处理节奏来运行匹配工作流程作业。现在,我选择机器学习匹配和手动作为处理节奏,然后选择下一步。

我将 S3 存储桶配置为输出目标。在数据格式下,我选择标准化数据,这样可以删除特殊字符和多余的空格,并将数据格式化为小写。

我使用默认的加密设置。对于数据输出,我使用默认值,以便包括所有输入字段。为安全起见,我可以隐藏字段以将其排除在输出之外,或者散列处理想要掩蔽的字段。我选择下一步。
我审查所有设置,然后选择创建并运行以完成匹配工作流程的创建并首次运行作业。
几分钟后,该作业完成。根据此分析的结果,在 100 万条记录中,只有 83.5 万条是唯一客户。我选择在 Amazon S3 中查看输出来下载输出文件。

在输出文件中,每条记录都有原始的唯一 ID(在本例中为 loyalty_id)和新分配的 MatchID。与同一客户相关的多条匹配记录具有相同的 MatchID。ConfidenceLevel 字段描述机器学习匹配所具有的置信度,即相应的记录实际上是匹配项。
我现在可以利用此信息来更准确地了解订阅忠诚度计划的客户。
可用性和定价
AWS Entity Resolution 现已在以下 AWS 区域正式推出:美国东部(俄亥俄州、弗吉尼亚州北部)、美国西部(俄勒冈州)、亚太地区(首尔、新加坡、悉尼、东京)和欧洲地区(法兰克福、爱尔兰、伦敦)。
借助 AWS Entity Resolution,您只需根据工作流程处理的源记录数量为使用的内容付费。定价并非取决于匹配方法,无论是机器学习还是基于规则的记录匹配。有关更多信息,请参阅 AWS Entity Resolution 定价。
使用 AWS Entity Resolution,您可以更深入地了解数据的链接方式。这有助于您提供新的见解,增强决策能力,以及根据客户记录的统一视图改善客户体验。
使用 AWS Entity Resolution 简化应用程序、渠道和数据存储间相关记录的匹配和链接方式。
— Danilo
附言我们专注于改进我们的内容,以提供更好的客户体验,我们需要您的反馈才能做到这一点。请参加此简短调查,分享您对 AWS Blog 体验的见解。请注意,此调查是由外部公司主办的,因此链接不会指向我们的网站。AWS 将按照 AWS 隐私声明中的说明处理您的信息。