背景
Alluxio是大数据技术堆栈的分布式缓存,对于S3,hdfs等数据的warm up有显著的性能提升,且与上层计算引擎如Hive,spark,Trino都有深度的集成,做为大数据领域的查询加速是一个不可多得的功能组件。
Alluxio社区与AWS EMR服务有深入的交互和集成,官方提供了on EMR的集成方案,详见Alluxio社区文档,AWS也提供了快速安装部署的bootstrap脚本及配置,详见AWS官方blog。
以上文档基于emr 5.2x版本,其hive,Spark等组件版本较老,且没有考虑EMR的多主,Task计算实例组的集成场景,在客户使用高版本EMR,启用HA及Task计算实例的时候,其安装部署存在缺陷导致部署失败。
本文档从Alluxio整体架构作为切入点,详细介绍了Alluxio的设计思路,使得读者能更深入的理解在AWS EMR上的集成方法,同时重新梳理并修正了Alluxio社区on AWS EMR集成的方案的缺陷,新增加了对EMR task实例组及多主高可用集群的支持,使得Alluxio 在AWS EMR上更能适应客户的生产环境。
Alluxio architecture overview

主要功能组件有:
Master节点: 类似NN的设计,同样有standby Master(HA)和secondary Master(元数据镜像合并)概念,Jounary 日志节点随master启动,做为快速recovery

Worker节点:与DataNode类似,缓存层提供Tier Storage(MEM,SSD,HDD三层),短路读和常规缓存穿透,3种写缓存模式(内存only,cache_through可以同步和异步, throught不写缓存)

Job master & Job worker: 缓存数据的读写,alluxio提供了类似hadoop MR的框架,由job master负责资源分配,job worker执行数据的pipeline管道,缓存副本默认为1
Alluxio的主要业务场景有
- hdfs/S3缓存,查询加速
- 多对象存储统一UFS路径
- 跨bucket,hdfs集群数据缓存
主要功能feature:
- 针对hdfs,s3多layer的backend存储
- 缓存读写,写支持cache through模式,异步更新backend storage;读支持push下压,缓存击穿后直接读backend storage
- ttl缓存过期时间配置
e.g:
alluxio.user.file.create.ttl = -1
alluxio.user.file.create.ttl.action = DELETE
alluxio.master.ttl.checker.interval = 1hour
- Impersonal/Acl/SASL HDFS类似的权限管控功能同样适用于Alluxio
- 缓存同步与清理
e.g:
缓存清理:Alluxio rm -r -U alluxio:///<path>
缓存同步:alluxio load alluxio:///<path>
Alluxio on AmazonEMR集成
集成架构
Alluxio 在Amazon EMR上架构如下所示

如上图所示,Alluxio Master组件作为管理模块,安装部署在Amazon EMR主实例组,如果需要Alluxio HA高可用,可以通过将EMR部署为多主,在bootstrap中打开alluxio HA(-h)的switch开关,部署脚本会将Alluxio Master部署到每个EMR 主节点实例,并在S3注册目录以供Alluxio主节点fail over时做Raft选举
Alluxio Worker组件安装部署在Amazon EMR的核心及任务实例组,由于task实例组客户可能配置扩缩,扩缩task计算节点时Alluxio work也会相应扩缩,其上面的缓存节点会做rebalance,造成缓存层性能抖动,因此对于Task任务实例组是否安装部署Alluxio,在bootstrap脚本中同样提供了switch开关(-g)
Alluxio tier storage配置为mem layer,UFS backend配置为S3数据湖存储
相应的Alluxio job master,job worker组件,和master,worker节点同样的部署方式,分布安装在EMR 主节点实例组和核心、任务实例组
集成步骤
以下章节详细介绍Alluxio在Amazon EMR上集成的实施步骤
- alluxio官网下载社区版tar安装包(本文采用7.3)
- 可以通过aws cli或者emr console,指定初始化配置json和bootstrap方式进行EMR上alluxio的集成安装和部署
- Amazon emr cli方式:
aws emr create-cluster \
--release-label emr-6.5.0 \
–instance-groups '[{"InstanceCount":2,"EbsConfiguration":{"EbsBlockDeviceConfigs":[{"VolumeSpecification":{"SizeInGB":64,"VolumeType":"gp2″},"InstanceGroupType":"CORE","InstanceType":"m5.xlarge","Name":"Core-2″}, \
{"InstanceCount":1,"EbsConfiguration":{"EbsBlockDeviceConfigs":[{"VolumeSpecification":{"SizeInGB":64,"VolumeType":"gp2″},"VolumesPerInstance":2}]},"InstanceGroupType":"MASTER","InstanceType":"m5.xlarge","Name":"Master-1″}]' \
--applications Name=Spark Name=Presto Name=Hive \
--name try-alluxio \
--bootstrap-actions \
Path=s3://xxxxxx.serverless-analytics/alluxiodemobucket/alluxio-emr.sh,\
Args=[s3://xxxxxx.serverless-analytics/alluxiodemobucket/data/,-d,"s3://xxxxxx.serverless-analytics/alluxiodemobucket/install/alluxio-2.7.3-bin.tar.gz",-p,"alluxio.user.block.size.bytes.default=122M|alluxio.user.file.writetype.default=CACHE_THROUGH",-s,"|"] \
--configurations s3://xxxxxx.serverless-analytics/alluxiodemobucket/ \
--ec2-attributes KeyName=ec203.pem
boostrap初始化参数
s3://xxxxxx.serverless-analytics/alluxiodemobucket/data/ -d s3://xxxxxx.serverless-analytics/alluxiodemobucket/install/alluxio-2.7.3-bin.tar.gz -p alluxio.user.block.size.bytes.default=122M|alluxio.user.file.writetype.default=CACHE_THROUGH -s |
boostrap初始化参数
s3://xxxxxx.serverless-analytics/alluxiodemobucket/data/ -d s3://xxxxxx.serverless-analytics/alluxiodemobucket/install/alluxio-2.7.3-bin.tar.gz -p alluxio.user.block.size.bytes.default=122M|alluxio.user.file.writetype.default=CACHE_THROUGH -s |
配置文件及boostrap脚本:
s3://xxxxxx.serverless-analytics/alluxiodemobucket/install: 安装tar包
s3://xxxxxx.serverless-analytics/alluxiodemobucket/data:测试under store底层存储
s3://xxxxxx.serverless-analytics/alluxiodemobucket/*.sh|*.json : bootstrap脚本及initial 配置
初始化Alluxio json集群配置:
{"Classification":"presto-connector-hive","Properties":{"hive.force-local-scheduling":"true","hive.metastore":"glue","hive.s3-file-system-type":"PRESTO"}},{"Classification":"hadoop-env","Configurations":[{"Classification":"export","Properties":{"HADOOP_CLASSPATH":"/opt/alluxio/client/alluxio-client.jar:${HADOOP_CLASSPATH}"}}],"Properties":{}}
Boostrap启动脚本说明
- Bootstrap主要完成alluxio集成步骤,包括解压alluxio tar安装包,等待emr hdfs等关键组件启动,然后解压并修改alluxio配置文件,启动alluxio各个组件进程
- Alluxio社区官方提供了和Amazon emr的集成boostrap,但只限于27版本,高版本(e.g: emr6.5)上组件组件端口会冲突,且没有考虑task节点实例类型的扩缩及HA等场景,本方案将原有的脚本主要升级和优化如下:
- Bootstrap脚本在task节点挂起,因为找不到DataNode进程,官方脚本内没有判断task实例类型,会一直循环等待
wait_for_hadoop func需要修改,如果是task,不再等待datanode进程,进入下一步骤
local -r is_task="false"
grep -i "instanceRole" /mnt/var/lib/info/job-flow-state.txt|grep -i task
if [ $? = "0" ];then
is_task="true"
fi
- 如果不需要扩展Task实例上的Alluxio worker,需要boostrap脚本中指定参数以便识别放过Task实例节点的alluxio安装部署过程
e)ignore_task_node="true"
;;
if [[ "${ignore_task_node}" = "true" ]]; then
"don't install alluxio on task node, boostrap exit!"
exit 0
fi
- 默认没有支持HA的bootstrap脚本,需要在bootstrap里面判断多个master节点并启动standby alluxio master
- 这里采用embedded JN 日志节点的形式,不占用EMR上Zookeeper的资源:
- Alluxio HA模式下task节点需要增加HA rpc访问地址列表
if [[ "${ha_mode}" = "true" ]]; then
namenodes=$(xmllint --xpath "/configuration/property[name='${namenode_prop}']/value/text()" "${ALLUXIO_HOME}/conf/hdfs-site.xml")
alluxio_journal_addre=""
alluxio_rpc_addre=""
for namenode in ${namenodes//,/ }; do
if [[ "${alluxio_rpc_addre}" != "" ]]; then
alluxio_rpc_addre=$alluxio_rpc_addre","
alluxio_journal_addre=$alluxio_journal_addre","
fi
alluxio_rpc_addre=$alluxio_rpc_addre"${namenode}:19998"
alluxio_journal_addre=$alluxio_journal_addre"${namenode}:19200"
done
set_alluxio_property alluxio.master.rpc.addresses $alluxio_rpc_addre
fi
验证Alluxio works
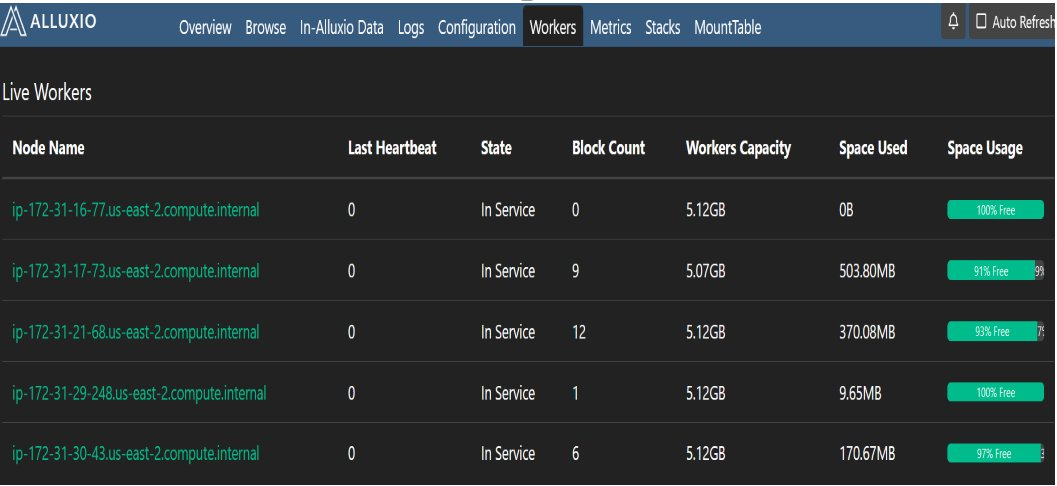
EMR启动后,会自动拉起Alluxio master ,worker进程,在Alluxio的admin 29999端口的管理控制台console上,可以方便的查看到集群的状态及capacity容量、UFS路径等信息
Alluxio console


计算框架集成
create external table s3_test1 (userid INT,
age INT,
gender CHAR(1),
occupation STRING,
zipcode STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '|'
LOCATION 's3://xxxxxx.serverless-analytics/alluxiodemobucket/data/s3_test1'
Hive alluxio读写
0: jdbc:hive2://xx.xx.xx.xx:10000/default> shwo create table alluxiodb.test1;
| createtab_stmt |
+----------------------------------------------------+
| CREATE EXTERNAL TABLE `alluxiodb.test1`( |
| `userid` int, |
| `age` int, |
| `gender` char(1), |
| `occupation` string, |
| `zipcode` string) |
| ROW FORMAT SERDE |
| 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' |
| WITH SERDEPROPERTIES ( |
| 'field.delim'='|', |
| 'serialization.format'='|') |
| STORED AS INPUTFORMAT |
| 'org.apache.hadoop.mapred.TextInputFormat' |
| OUTPUTFORMAT |
| 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat' |
| LOCATION |
| 'alluxio:/testTable' |
| TBLPROPERTIES ( |
| 'bucketing_version'='2') |
+----------------------------------------------------+
0: jdbc:hive2://xx.xx.xx.xx:10000/default>INSERT INTO alluxiodb.test1 VALUES (2, 24, 'F', 'Developer', '12345');
0: jdbc:hive2://xx.xx.xx.xx:10000/default> select * from test1;
--+
| test1.userid | test1.age | test1.gender | test1.occupation | test1.zipcode |
+---------------+------------+---------------+-------------------+----------------+
| 1 | 24 | F | Developer | 12345 |
| 4 | 46 | F | Developer | 12345 |
| 5 | 56 | A | Developer | 12345 |
| 2 | 224 | F | Developer | 12345
Trino alluxio query:
trino:alluxiodb> select * from test1;
userid | age | gender | occupation | zipcode
--------+-----+--------+------------+---------
1 | 24 | F | Developer | 12345
2 | 224 | F | Developer | 12345
Spark alluxio读写
>>> spark.sql("insert into alluxiodb.test1 values (3,33,'T','Admin','222222')")
>>> spark.sql("select * from alluxiodb.test1").show(1000,False) +------+---+------+----------+-------+
|userid|age|gender|occupation|zipcode|
+------+---+------+----------+-------+
|2 |224|F |Developer |12345 |
|3 |33 |T |Admin |222222 |
|1 |24 |F |Developer |12345 |
+------+---+------+----------+-------+
benchmark测试
采用hive tpcds benchmark utility 生成并load 测试数据,可以方便的对比通过s3路径和alluxio缓存路径两种场景下查询性能
- alluxio hive benchmarch result:
hive -i testbench_alluxio.settings
hive> use tpcds_bin_partitioned_orc_30;
hive> source query55.sql;
+-----------+------------------------+---------------------+
| brand_id | brand | ext_price |
+-----------+------------------------+---------------------+
| 2002002 | importoimporto #2 | 328158.27 |
| 4004002 | edu packedu pack #2 | 278740.06999999995 |
| 2004002 | edu packimporto #2 | 243453.09999999998 |
| 2001002 | amalgimporto #2 | 226828.09000000003 |
| 4003002 | exportiedu pack #2 | 194363.72000000003 |
| 5004002 | edu packscholar #2 | 178895.29000000004 |
| 5003002 | exportischolar #2 | 158463.69 |
| 3003002 | exportiexporti #2 | 126980.51999999999 |
| 4001002 | amalgedu pack #2 | 107703.01000000001 |
| 5002002 | importoscholar #2 | 104491.46000000002 |
| 3002002 | importoexporti #2 | 87758.88 |
| 8010006 | univmaxi #6 | 87110.54999999999 |
| 10004013 | edu packunivamalg #13 | 76879.23 |
| 8008006 | namelessnameless #6 | 74991.82 |
| 6010006 | univbrand #6 | 72163.57 |
| 7006008 | corpbrand #8 | 71066.42 |
| 2003002 | exportiimporto #2 | 69029.02 |
| 6015006 | scholarbrand #6 | 66395.84 |
| 4002002 | importoedu pack #2 | 65223.01999999999 |
| 8013002 | exportimaxi #2 | 63271.69 |
| 9007002 | brandmaxi #2 | 61539.36000000001 |
| 3001001 | edu packscholar #2 | 60449.65 |
| 10003014 | exportiunivamalg #14 | 56505.57000000001 |
| 3001001 | exportiexporti #2 | 55458.64 |
| 7015004 | scholarnameless #4 | 55006.78999999999 |
| 5002001 | exportischolar #2 | 54996.270000000004 |
| 6014008 | edu packbrand #8 | 54793.31999999999 |
| 4003001 | amalgcorp #8 | 53875.51000000001 |
| 8011006 | amalgmaxi #6 | 52845.8 |
| 1002002 | importoamalg #2 | 52328.259999999995 |
| 2003001 | maxinameless #6 | 50577.89 |
| 9016008 | corpunivamalg #8 | 49700.12 |
| 7015006 | scholarnameless #6 | 49592.7 |
| 9005004 | scholarmaxi #4 | 49205.19 |
| 4003001 | exportiimporto #2 | 48604.97 |
| 2002001 | edu packamalg #2 | 48451.979999999996 |
| 9012002 | importounivamalg #2 | 48429.990000000005 |
| 7012004 | importonameless #4 | 48303.979999999996 |
| 10009004 | edu packamalg #2 | 48301.05 |
| 1004001 | amalgexporti #2 | 48215.880000000005 |
| 1001002 | amalgamalg #2 | 47018.94 |
| 9015010 | scholarunivamalg #10 | 46495.380000000005 |
| 6005007 | importobrand #6 | 46233.630000000005 |
| 9010004 | univunivamalg #4 | 46164.04 |
| 8015006 | scholarmaxi #6 | 46143.41 |
| 7016002 | corpnameless #2 | 46133.31 |
| 10006011 | corpunivamalg #11 | 46085.81 |
| 9001003 | importoamalg #2 | 45303.18 |
| 10015011 | scholarnameless #2 | 45299.06 |
| 5002001 | importoexporti #2 | 44757.73000000001 |
| 10010004 | univamalgamalg #4 | 43347.899999999994 |
| 2004001 | importoamalg #2 | 43127.46000000001 |
| 9002011 | edu packcorp #8 | 41740.42 |
| 10008009 | namelessunivamalg #9 | 41369.479999999996 |
| 8002010 | importonameless #10 | 41046.02 |
| 6002008 | importocorp #8 | 40795.42999999999 |
| 7007010 | brandbrand #10 | 40591.95 |
| 6012002 | importobrand #2 | 40545.72 |
| 2003001 | amalgexporti #2 | 39679.76 |
| 8005007 | exportischolar #2 | 39593.39 |
| 9015011 | importoscholar #2 | 39419.41 |
| 9005012 | scholarmaxi #12 | 39151.020000000004 |
| 9016012 | corpunivamalg #12 | 39117.53 |
| 5003001 | exportiexporti #2 | 39061.0 |
| 9002002 | importomaxi #2 | 38763.61 |
| 6010004 | univbrand #4 | 38375.29 |
| 8016009 | edu packamalg #2 | 37759.44 |
| 8003010 | exportinameless #10 | 37605.38 |
| 10010013 | univamalgamalg #13 | 37567.33 |
| 4003001 | importoexporti #2 | 37455.68 |
| 4001001 | importoedu pack #2 | 36809.149999999994 |
| 8006003 | edu packimporto #2 | 36687.04 |
| 6004004 | edu packcorp #4 | 36384.1 |
| 5004001 | scholarbrand #8 | 36258.58 |
| 10006004 | importonameless #10 | 36226.62 |
| 2002001 | scholarbrand #4 | 36138.93 |
| 7001010 | amalgbrand #10 | 35986.36 |
| 8015005 | edu packunivamalg #4 | 35956.33 |
| 10014008 | edu packamalgamalg #8 | 35371.05 |
| 7004005 | amalgamalg #2 | 35265.32 |
| 6016004 | corpbrand #4 | 35256.990000000005 |
| 4002001 | amalgedu pack #2 | 35183.9 |
+-----------+------------------------+---------------------+
- s3 hive benchmarch result:
hive -i testbench_s3.settings
hive> use tpcds_bin_partitioned_orc_30;
hive> source query55.sql;
+-----------+------------------------+---------------------+
| brand_id | brand | ext_price |
+-----------+------------------------+---------------------+
| 4003002 | exportiedu pack #2 | 324254.89 |
| 4004002 | edu packedu pack #2 | 241747.01000000004 |
| 2004002 | edu packimporto #2 | 214636.82999999996 |
| 3003002 | exportiexporti #2 | 158815.92 |
| 2002002 | importoimporto #2 | 126878.37000000002 |
| 2001002 | amalgimporto #2 | 123531.46 |
| 4001002 | amalgedu pack #2 | 114080.09000000003 |
| 5003002 | exportischolar #2 | 103824.98000000001 |
| 5004002 | edu packscholar #2 | 97543.4 |
| 3002002 | importoexporti #2 | 90002.6 |
| 6010006 | univbrand #6 | 72953.48000000001 |
| 6015006 | scholarbrand #6 | 67252.34000000001 |
| 7001010 | amalgbrand #10 | 60368.53 |
| 4002001 | amalgmaxi #12 | 59648.09 |
| 5002002 | importoscholar #2 | 59202.14 |
| 9007008 | brandmaxi #8 | 57989.22 |
| 2003002 | exportiimporto #2 | 57869.27 |
| 1002002 | importoamalg #2 | 57119.29000000001 |
| 3001001 | exportiexporti #2 | 56381.43 |
| 7010004 | univnameless #4 | 55796.41 |
| 4002002 | importoedu pack #2 | 55696.91 |
| 8001010 | amalgnameless #10 | 54025.19 |
| 9016012 | corpunivamalg #12 | 53992.149999999994 |
| 5002001 | exportischolar #2 | 53784.57000000001 |
| 4003001 | amalgcorp #8 | 52727.09 |
| 9001002 | amalgmaxi #2 | 52115.3 |
| 1002001 | amalgnameless #2 | 51994.130000000005 |
| 8003010 | exportinameless #10 | 51100.64 |
| 9003009 | edu packamalg #2 | 50413.2 |
| 10007003 | scholarbrand #6 | 50027.27 |
| 7006008 | corpbrand #8 | 49443.380000000005 |
| 9016010 | corpunivamalg #10 | 49181.66000000001 |
| 9005010 | scholarmaxi #10 | 49019.619999999995 |
| 4001001 | importoedu pack #2 | 47280.47 |
| 4004001 | amalgcorp #2 | 46830.21000000001 |
| 10007011 | brandunivamalg #11 | 46815.659999999996 |
| 9003008 | exportimaxi #8 | 46731.72 |
| 1003001 | amalgnameless #2 | 46250.08 |
| 8010006 | univmaxi #6 | 45460.4 |
| 8013002 | exportimaxi #2 | 44836.49 |
| 5004001 | scholarbrand #8 | 43770.06 |
| 10006011 | corpunivamalg #11 | 43461.3 |
| 2002001 | edu packamalg #2 | 42729.89 |
| 6016001 | importoamalg #2 | 42298.35999999999 |
| 5003001 | univunivamalg #4 | 42290.45 |
| 7004002 | edu packbrand #2 | 42222.060000000005 |
| 6009004 | maxicorp #4 | 42131.72 |
| 2002001 | importoexporti #2 | 41864.04 |
| 8006006 | corpnameless #6 | 41825.83 |
| 10008009 | namelessunivamalg #9 | 40665.31 |
| 4003001 | univbrand #2 | 40330.67 |
| 7016002 | corpnameless #2 | 40026.4 |
| 2004001 | corpmaxi #8 | 38924.82 |
| 7009001 | amalgedu pack #2 | 38711.04 |
| 6013004 | exportibrand #4 | 38703.41 |
| 8002010 | importonameless #10 | 38438.670000000006 |
| 9010004 | univunivamalg #4 | 38294.21 |
| 2004001 | importoimporto #2 | 37814.93 |
| 9010002 | univunivamalg #2 | 37780.55 |
| 3003001 | amalgexporti #2 | 37501.25 |
| 8014006 | edu packmaxi #6 | 35914.21000000001 |
| 8011006 | amalgmaxi #6 | 35302.51 |
| 8013007 | amalgcorp #4 | 34994.01 |
| 7003006 | exportibrand #6 | 34596.55 |
| 6009006 | maxicorp #6 | 44116.12 |
| 8002004 | importonameless #4 | 43876.82000000001 |
| 8001008 | amalgnameless #8 | 43666.869999999995 |
| 7002006 | importobrand #6 | 43574.33 |
| 7013008 | exportinameless #8 | 43497.73 |
| 6014008 | edu packbrand #8 | 43381.46 |
| 10014007 | edu packamalgamalg #7 | 42982.090000000004 |
| 9006004 | corpmaxi #4 | 42437.49 |
| 9016008 | corpunivamalg #8 | 41782.0 |
| 10006015 | amalgamalg #2 | 31716.129999999997 |
| 2003001 | univnameless #4 | 31491.340000000004 |
+-----------+------------------------+----------
可以看到平均任务的QPS提升30%~40%左右,部分任务提升50%以上
小结
本文详细介绍了在Amazon EMR上alluxio集群的安装部署,包括bootstrap脚本及EMR集群初始化json配置,并通过hive tpcds 标准benchmark,比较了开启Alluxio加速的EMR集群上hive sql查询的性能提升
参考资料
Alluxio on AWS EMR安装部署 :https://thinkwithwp.com/cn/blogs/china/five-minitues-to-use-alluxio-guide-emr-spark
Alluxio社区 EMR集成指南: https://docs.alluxio.io/os/user/stable/en/cloud/AWS-EMR.html
AWS EMR集群:https://docs.thinkwithwp.com/zh_cn/emr/latest/ManagementGuide/emr-what-is-emr.html
本篇作者