亚马逊AWS官方博客
在 Amazon SageMaker 上使用 AWS Inferentia2 和 AWS Trainium 以最低成本实现高性能的生成式人工智能推理
随着能够创建类人文本、图像、代码和音频的生成式人工智能模型的兴起,人工智能(AI)和机器学习(ML)的世界见证了模式的转变。与传统的机器学习模型相比,生成式人工智能模型要大得多,也复杂得多。然而,这种模型增加了复杂性,也带来了高昂的推理成本,以及对强大计算资源日益增长的需求。对于资源有限的企业和研究人员来说,生成式人工智能模型的高推理成本可能会成为进入市场的障碍,因此需要更高效、更具成本效益的解决方案。此外,大多数生成式人工智能使用案例都涉及人机交互或真实世界场景,因此需要能提供低延迟性能的硬件。AWS 一直在利用专用芯片进行创新,以满足对功能强大、高效且经济实惠的计算硬件的日益增长的需求。
今天,我们很高兴地宣布,Amazon SageMaker 支持基于 AWS Inferentia2(ml.inf2)和 AWS Trainium(ml.trn1)的 SageMaker 实例,以托管用于实时推理和异步推理的生成式人工智能模型。ml.inf2 实例可在美国东部(俄亥俄)的 SageMaker 上部署模型,ml.trn1 实例可在美国东部(弗吉尼亚北部)的 SageMaker 上部署模型。
您可以在 SageMaker 上使用这些实例,以低成本实现生成式人工智能模型的高性能,包括大型语言模型(LLM)、Stable Diffusion 和 Vision Transformers。此外,您还可以使用 Amazon SageMaker Inference Recommender 来协助您运行负载测试,并评估在这些实例上部署模型的性价比优势。
您可以使用 ml.inf2 和 ml.trn1 实例在 SageMaker 上运行机器学习应用程序,以实现文本摘要、代码生成、视频和图像生成、语音识别、个性化、欺诈侦测等。要轻松上手,您可以在配置 SageMaker 端点时首先指定 ml.trn1 或 ml.inf2 实例。然后将兼容 ml.trn1 和 ml.inf2 的 AWS Deep Learning Containers(DLC)用于 PyTorch、TensorFlow、Hugging Face 和大型模型推理(LMI)。有关版本的完整列表,请参阅可用的 Deep Learning Containers 映像。
在这篇文章中,我们将展示利用 LMI 容器,在不需要任何额外编码的情况下,使用 SageMaker 在 AWS Inferentia2 上部署大型语言模型的过程。我们使用 GPT4ALL-J,这是一种经过微调的 GPT-J 7B 模型,可提供聊天机器人风格的互动。
ml.trn1 和 ml.inf2 实例概述
ml.trn1 实例由 Trainium 加速器提供支持,该加速器主要用于生成式人工智能模型(包括 LLM)的高性能深度学习训练。不过,这些实例也支持比 Inf2 所适合的模型更大的推理工作负载。最大的实例(trn1.32xlarge 实例)在单个实例中配备了 16 个 Trainium 加速器和 512 GB 加速器内存,可提供高达 3.4 petaflops 的 FP16/BF16 计算能力。16 个 Trainium 加速器通过超高速 NeuronLinkv2 进行连接,这样可简化集体通信。
ml.Inf2 实例由 AWS Inferentia2 加速器提供支持,这是一款专为推理而构建的加速器。与第一代 AWS Inferentia 相比,这款加速器的计算性能提高了三倍,吞吐量提高了四倍,延迟降低了多达 10 倍。最大的实例 Inf2.48xlarge 在单个实例中配备了 12 个 AWS Inferentia2 加速器和 384 GB 加速器内存,BF16/FP16 的综合计算能力为 2.3 petaflops。这使您能够在单个实例中部署包含多达 1750 亿个参数的模型。Inf2 是唯一提供这种互连功能的推理优化实例,而这种功能只有在更昂贵的训练实例中才有。对于单个加速器无法容纳的超大型模型,数据可通过 NeuronLink 直接在加速器之间流动,完全绕过 CPU。借助 NeuronLink,Inf2 支持更快的分布式推理,并提高吞吐量、降低延迟。
AWS Inferentia2 和 Trainium 加速器都有两个 NeuronCores-v2、32 GB HBM 内存堆栈和专用的集体计算引擎,在进行多加速器推理时,通过重叠计算和通信自动优化运行时系统。有关架构的更多详细信息,请参考 Trainium 和 Inferentia 设备。
下图显示了使用 AWS Inferentia2 的架构示例。

AWS Neuron SDK
AWS Neuron 是用于在基于 AWS Inferentia 和 Trainium 的实例上运行深度学习工作负载的 SDK。AWS Neuron 包括深度学习编译器、运行时系统和原生集成到 TensorFlow 和 PyTorch 中的工具。利用 Neuron,您可以在 ml.trn1 和 ml.inf2 上开发、分析和部署高性能机器学习工作负载。
Neuron 编译器接受各种格式的机器学习模型(TensorFlow、PyTorch、XLA HLO),并对这些模型进行优化,以便在 Neuron 设备上运行。在机器学习框架内调用 Neuron 编译器,而在该框架内,机器学习模型由 Neuron 框架插件发送给编译器。由此产生的编译器构件称为 NEFF 文件(Neuron 可执行文件格式),Neuron 运行时系统会将该文件加载到 Neuron 设备中。
Neuron 运行时系统由内核驱动程序和 C/C++ 库组成,这些库提供 API 来访问 AWS Inferentia 和 Trainium Neuron 设备。适用于 TensorFlow 和 PyTorch 的 Neuron 机器学习框架插件使用 Neuron 运行时系统在 NeuronCore 上加载和运行模型。Neuron 运行时系统将编译好的深度学习模型(NEFF)加载到 Neuron 设备上,并针对高吞吐量和低延迟进行优化。
使用 SageMaker ml.inf2 实例托管 NLP 模型
transformers-neuronx 是一个开源库,可将模型的大型权重矩阵分片到多个 NeuronCore 上,在深入研究如何使用该库为 LLM 提供服务之前,让我们先简单了解一下可用于单个 NeuronCore 的模型的典型部署流程。
查看支持的模型列表,确保 AWS Inferentia2 支持该模型。接下来,需要使用 Neuron 编译器对模型进行预编译。您可以使用 SageMaker notebook 或 Amazon Elastic Compute Cloud(Amazon EC2)实例来编译模型。您可以借助 SageMaker Python SDK,使用 PyTorch 等流行的深度学习框架部署模型,如以下代码所示。您可以将模型部署到 SageMaker 托管服务,并获得可用于推理的端点。这些端点是完全托管的,支持自动扩缩。
有关在 SageMaker 上使用示例脚本的典型 Inf2 开发流程的更多详细信息,请参阅开发流程。
使用 SageMaker ml.inf2 实例托管 LLM
大型语言模型通常具有数十亿个参数,规模太大,单个加速器无法容纳。这就需要使用模型并行技术,在多个加速器上托管 LLM。托管 LLM 的另一个关键要求是实施高性能的模型服务解决方案。该解决方案应该能够高效地加载模型、管理分区,并通过 HTTP 端点无缝地处理请求。
SageMaker 包括专门的 Deep Learning Containers(DLC)、库和工具,用于模型并行化和大型模型推理。有关在 SageMaker 上开始使用 LMI 的资源,请参阅模型并行化和大型模型推理。SageMaker 使用流行的开源库维护 DLC,以便在 AWS 基础设施上托管 GPT、T5、OPT、BLOOM 和 Stable Diffusion 等大型模型。这些专用的 DLC 称为 SageMaker LMI 容器。
SageMaker LMI 容器使用 DJLServing,这是一种与 transformers-neuronx 库集成的模型服务器,可支持 NeuronCore 之间的张量并行。要了解有关 DJLServing 工作原理的更多信息,请参阅使用 DJLServing 和 DeepSpeed 模型并行推理在 Amazon SageMaker 上部署大型模型。DJL 模型服务器和 transformers-neuronx 库是容器的核心组件,其中还包括 Neuron SDK。这种设置便于将模型加载到 AWS Inferentia2 加速器上,在多个 NeuronCore 上并行处理模型,并通过 HTTP 端点提供服务。
LMI 容器支持从 Amazon Simple Storage Service(Amazon S3)存储桶或 Hugging Face Hub 加载模型。默认的处理程序脚本会加载模型,将模型编译并转换为 Neuron 优化格式,然后再次加载模型。要使用 LMI 容器托管 LLM,我们有两种选择:
- 无代码(首选)– 这是使用 LMI 容器部署 LLM 的最简单方法。在这种方法中,您可以使用提供的默认处理程序,只需传递模型名称和
serving.properties文件中所需的参数,即可加载和托管模型。要使用默认处理程序,我们需要将entryPoint参数设置为djl_python.transformers-neuronx。 - 自带脚本 – 在这种方法中,您可以选择创建自己的 model.py 文件,其中包含加载和服务模型所需的代码。该文件充当
DJLServingAPI 和transformers-neuronxAPI 之间的中介。要自定义模型加载过程,可以为serving.properties提供可配置的参数。有关可用的可配置参数的完整列表,请参阅所有 DJL 配置选项。以下是 model.py 文件的示例。
运行时系统架构
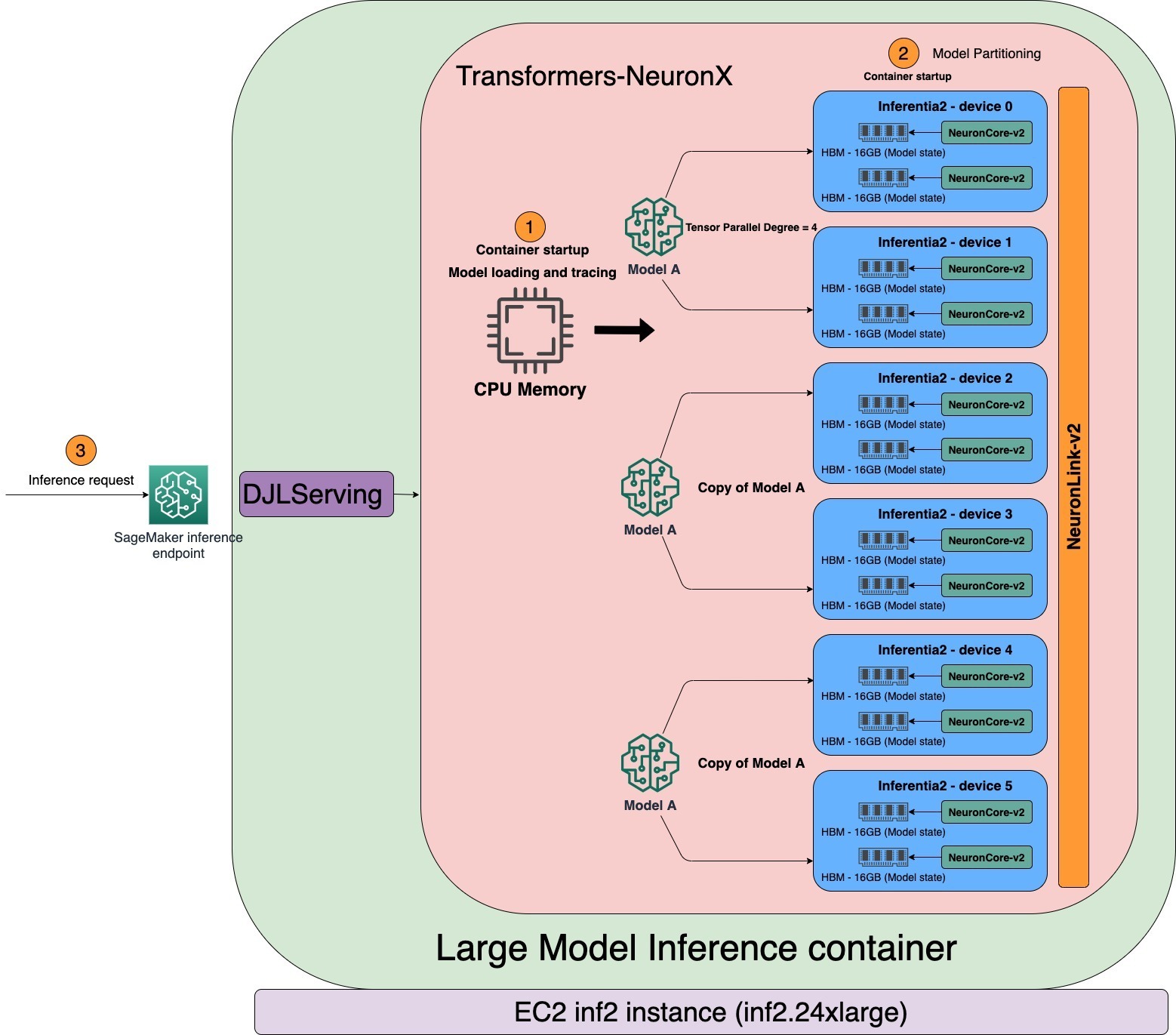
tensor_parallel_degree 属性值决定了张量并行模块在多个 NeuronCore 上的分布。例如,inf2.24xlarge 有六个 AWS Inferentia2 加速器。每个 AWS Inferentia2 加速器都有两个 NeuronCore。每个 NeuronCore 都有一个 16 GB 的专用高带宽内存(HBM),用于存储张量并行模块。当张量并行度为 4 时,LMI 将为同一模型分配三个模型副本,每个副本使用 4 个 NeuronCore。如下图所示,当 LMI 容器启动时,将首先在 CPU 可寻址内存中加载和跟踪模型。跟踪完成后,根据张量并行度跨 NeuronCore 对模型进行分区。
LMI 使用 DJLServing 作为其模型服务堆栈。在 SageMaker 中通过容器的运行状况检查后,容器即可处理推理请求。DJLServing 启动相当于 TOTAL NUMBER OF NEURON CORES/TENSOR_PARALLEL_DEGREE 的多个 Python 进程。每个 Python 进程都包含相当于 TENSOR_PARALLEL_DEGREE 的 C++ 线程。每个 C++ 线程在一个 NeuronCore 上保存一个模型分片。
当使用多个独立请求调用服务器时,许多实践者(Python 进程)倾向于按顺序运行推理。尽管设置起来更容易,但利用加速器的计算能力通常不是最佳实践。为解决这一问题,DJLServing 提供了动态批处理的内置优化功能,可在服务器端将这些独立的推理请求动态合并成一个更大的批处理,以提高吞吐量。所有请求都先到达动态批处理器,然后才进入实际的作业队列等待推理。您可以使用 serving.properties 中的 batch_size 设置,为动态批处理设置首选的批处理大小。您还可以配置 max_batch_delay,根据延迟要求指定批处理器中等待其他请求加入批处理的最长延迟时间。吞吐量还取决于模型副本的数量和容器中启动的 Python 进程组。如下图所示,当张量并行度设置为 4 时,LMI 容器会启动三个 Python 进程组,每个进程组都包含模型的完整副本。这使您可以增加批处理大小,获得更高的吞吐量。
用于部署 LLM 的 SageMaker notebook
在本节中,我们将逐步演示如何部署 GPT4All-J,这是一种包含 60 亿个参数的模型,采用 FP32 时有 24 GB。GPT4All-J 是一款流行的聊天机器人,接受过的训练包括单词问题、对话、代码、诗歌、歌曲和故事等各种交互内容。GPT4all-J 是一种经过微调的 GPT-J 模型,可产生与人类互动类似的响应。
GitHub 上提供完整的 notebook 示例。我们可以使用 SageMaker Python SDK 将模型部署到 Inf2 实例。我们使用提供的默认处理程序来加载模型。这样,我们只需提供一个 servings.properties 文件。此文件具有 DJL 模型服务器下载和托管模型所需的配置。我们可以使用 model_id 参数指定 Hugging Face 模型的名称,以便直接从 Hugging Face 存储库下载模型。或者,您也可以通过提供 s3url 参数从 Amazon S3 下载模型。entryPoint 参数配置为指向用于加载模型的库。有关 djl_python.fastertransformer 的更多详细信息,请参阅 GitHub 代码。
tensor_parallel_degree 属性值决定了张量并行模块在多个设备上的分布。例如,如果有 12 个 NeuronCore,张量并行度为 4,那么 LMI 将分配 3 个模型副本,每个副本使用 4 个 NeuronCore。您还可以使用属性 dtype 定义精度类型。n_position 参数定义了模型的最大输入和输出序列长度之和。请参阅以下代码:
构造包含 serving.properties 的 tarball,并将其上传到 S3 存储桶。虽然本示例使用的是默认处理程序,但您也可以开发一个 model.py 文件来自定义加载和服务流程。如果有任何需要安装的软件包,请将它们包含在 requirements.txt 文件中。请参阅以下代码:
检索 DJL 容器映像并创建 SageMaker 模型:
接下来,我们使用之前定义的模型配置创建 SageMaker 端点。容器会将模型下载到 /tmp 空间,因为 SageMaker 会将 /tmp 映射到 Amazon Elastic Block Store(Amazon EBS)。我们需要添加一个 volume_size 参数,以确保 /tmp 目录有足够的空间来下载和编译模型。我们将 container_startup_health_check_timeout 设置为 3600 秒,以确保在模型准备就绪后开始运行状况检查。我们使用 ml.inf2.8xlarge 实例。请参阅以下代码:
创建 SageMaker 端点后,我们可以使用 Predictor 对象针对 SageMaker 端点进行实时预测:
清理
完成测试后,删除端点以节省成本:
总结
在这篇文章中,我们展示了 SageMaker 新推出的功能,它现在支持 ml.inf2 和 ml.trn1 实例来托管生成式人工智能模型。我们演示了如何在不编写任何代码的情况下,使用 SageMaker 和 LMI 容器在 AWS Inferentia2 上部署生成式人工智能模型 GPT4ALL-J。我们还展示了如何使用 DJLServing 和 transformers-neuronx 加载模型、对模型进行分区和提供服务。
Inf2 实例提供了在 AWS 上运行生成式人工智能模型的最具成本效益的方式。有关性能详情,请参阅 Inf2 性能。
查看 GitHub 存储库,获取 notebook 示例。试试吧,如果有任何问题,请告诉我们!
关于作者
 Vivek Gangasani 是 Amazon Web Services 的高级机器学习解决方案架构师。他与机器学习初创企业合作,在 AWS 上构建和部署人工智能/机器学习应用程序。他目前专注于为 MLOps、机器学习推理和低代码机器学习提供解决方案。他曾参与过不同领域的项目,包括自然语言处理和计算机视觉。
Vivek Gangasani 是 Amazon Web Services 的高级机器学习解决方案架构师。他与机器学习初创企业合作,在 AWS 上构建和部署人工智能/机器学习应用程序。他目前专注于为 MLOps、机器学习推理和低代码机器学习提供解决方案。他曾参与过不同领域的项目,包括自然语言处理和计算机视觉。
 Hiroshi Tokoyo 是 AWS Annapurna Labs 的解决方案架构师。他常驻日本,在 Annapurna Labs 被 AWS 收购之前就加入了该公司,并一直利用 Annapurna Labs 的技术为客户提供帮助。他最近的工作重点是基于专用硅芯片、AWS Inferentia 和 Trainium 的机器学习解决方案。
Hiroshi Tokoyo 是 AWS Annapurna Labs 的解决方案架构师。他常驻日本,在 Annapurna Labs 被 AWS 收购之前就加入了该公司,并一直利用 Annapurna Labs 的技术为客户提供帮助。他最近的工作重点是基于专用硅芯片、AWS Inferentia 和 Trainium 的机器学习解决方案。
 Dhawal Patel 是 AWS 的首席机器学习架构师。他一直就职于从大型企业到中型初创企业等组织,致力于解决与分布式计算和人工智能有关的问题。他专注于深度学习,包括 NLP 和计算机视觉领域。他帮助客户在 SageMaker 上实现了高性能模型推理。
Dhawal Patel 是 AWS 的首席机器学习架构师。他一直就职于从大型企业到中型初创企业等组织,致力于解决与分布式计算和人工智能有关的问题。他专注于深度学习,包括 NLP 和计算机视觉领域。他帮助客户在 SageMaker 上实现了高性能模型推理。
 Qing Lan 是 AWS 的软件开发工程师。他一直在 Amazon 从事多项具有挑战性的产品开发工作,包括高性能机器学习推理解决方案和高性能日志记录系统。Qing 的团队成功地在 Amazon Advertising 中推出了首个十亿参数模型,而且所需的延迟非常低。Qing 对基础设施优化和深度学习加速有深入的了解。
Qing Lan 是 AWS 的软件开发工程师。他一直在 Amazon 从事多项具有挑战性的产品开发工作,包括高性能机器学习推理解决方案和高性能日志记录系统。Qing 的团队成功地在 Amazon Advertising 中推出了首个十亿参数模型,而且所需的延迟非常低。Qing 对基础设施优化和深度学习加速有深入的了解。
 Qingwei Li 是 Amazon Web Services 的机器学习专家。在他中断了导师的研究补助金账户并且未能兑现他承诺的诺贝尔奖之后,他获得了运筹学博士学位。目前,他协助金融服务和保险行业的客户在 AWS 上构建机器学习解决方案。业余时间,他喜欢阅读和教学。
Qingwei Li 是 Amazon Web Services 的机器学习专家。在他中断了导师的研究补助金账户并且未能兑现他承诺的诺贝尔奖之后,他获得了运筹学博士学位。目前,他协助金融服务和保险行业的客户在 AWS 上构建机器学习解决方案。业余时间,他喜欢阅读和教学。
 Alan Tan 是 SageMaker 的高级产品经理,负责大型模型推理方面的工作。他热衷于将机器学习应用到分析领域。工作之余,他喜欢户外活动。
Alan Tan 是 SageMaker 的高级产品经理,负责大型模型推理方面的工作。他热衷于将机器学习应用到分析领域。工作之余,他喜欢户外活动。
 Varun Syal 是 AWS Sagemaker 的软件开发工程师,负责为机器学习推理平台开发面向客户的关键功能。他热衷于分布式系统和人工智能领域的工作。业余时间,他喜欢阅读和园艺。
Varun Syal 是 AWS Sagemaker 的软件开发工程师,负责为机器学习推理平台开发面向客户的关键功能。他热衷于分布式系统和人工智能领域的工作。业余时间,他喜欢阅读和园艺。