AWS Big Data Blog
Tag: AWS Glue

Empower your Jira data in a data lake with Amazon AppFlow and AWS Glue
In the world of software engineering and development, organizations use project management tools like Atlassian Jira Cloud. Managing projects with Jira leads to rich datasets, which can provide historical and predictive insights about project and development efforts. Although Jira Cloud provides reporting capability, loading this data into a data lake will facilitate enrichment with other […]

How the BMW Group analyses semiconductor demand with AWS Glue
This is a guest post co-written by Maik Leuthold and Nick Harmening from BMW Group. The BMW Group is headquartered in Munich, Germany, where the company oversees 149,000 employees and manufactures cars and motorcycles in over 30 production sites across 15 countries. This multinational production strategy follows an even more international and extensive supplier network. Like many automobile companies across the world, the […]

Build a data lake with Apache Flink on Amazon EMR
To build a data-driven business, it is important to democratize enterprise data assets in a data catalog. With a unified data catalog, you can quickly search datasets and figure out data schema, data format, and location. The AWS Glue Data Catalog provides a uniform repository where disparate systems can store and find metadata to keep […]

Build, Test and Deploy ETL solutions using AWS Glue and AWS CDK based CI/CD pipelines
April 2025: After careful consideration, we have made the decision to close new customer access to AWS CodeCommit, effective July 25, 2024. AWS CodeCommit existing customers can continue to use the service as normal. AWS continues to invest in security, availability, and performance improvements for AWS CodeCommit, but we do not plan to introduce new […]

Upgrade Amazon EMR Hive Metastore from 5.X to 6.X
If you are currently running Amazon EMR 5.X clusters, consider moving to Amazon EMR 6.X as it includes new features that helps you improve performance and optimize on cost. For instance, Apache Hive is two times faster with LLAP on Amazon EMR 6.X, and Spark 3 reduces costs by 40%. Additionally, Amazon EMR 6.x releases […]

Interactively develop your AWS Glue streaming ETL jobs using AWS Glue Studio notebooks
Enterprise customers are modernizing their data warehouses and data lakes to provide real-time insights, because having the right insights at the right time is crucial for good business outcomes. To enable near-real-time decision-making, data pipelines need to process real-time or near-real-time data. This data is sourced from IoT devices, change data capture (CDC) services like […]

Optimize Federated Query Performance using EXPLAIN and EXPLAIN ANALYZE in Amazon Athena
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. In 2019, Athena added support for federated queries to run SQL […]
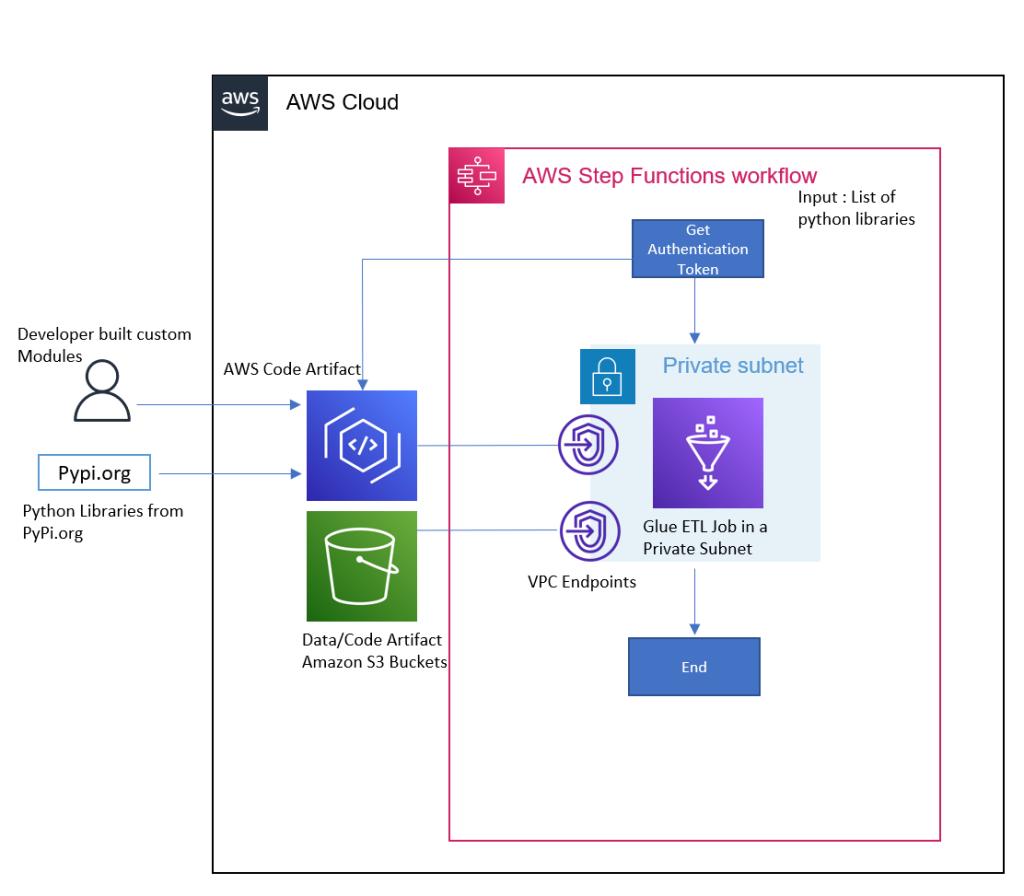
Simplify and optimize Python package management for AWS Glue PySpark jobs with AWS CodeArtifact
Data engineers use various Python packages to meet their data processing requirements while building data pipelines with AWS Glue PySpark Jobs. Languages like Python and Scala are commonly used in data pipeline development. Developers can take advantage of their open-source packages or even customize their own to make it easier and faster to perform use […]

How MEDHOST’s cardiac risk prediction successfully leveraged AWS analytic services
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. MEDHOST has been providing products and services to healthcare facilities of all types and sizes for over 35 years. Today, more than 1,000 healthcare facilities are partnering with MEDHOST and enhancing their […]
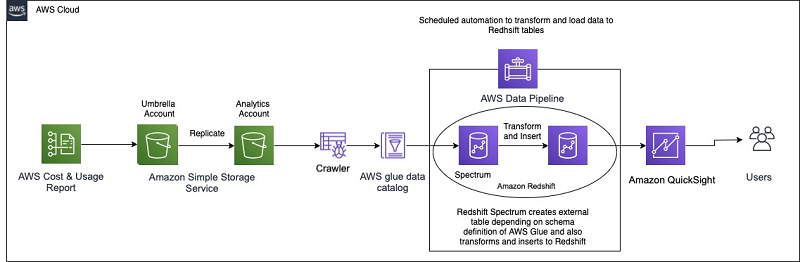
How Aruba Networks built a cost analysis solution using AWS Glue, Amazon Redshift, and Amazon QuickSight
February 2023 Update: Console access to the AWS Data Pipeline service will be removed on April 30, 2023. On this date, you will no longer be able to access AWS Data Pipeline though the console. You will continue to have access to AWS Data Pipeline through the command line interface and API. Please note that […]