AWS Big Data Blog
Tag: Amazon Athena

Detect fraudulent calls using Amazon QuickSight ML insights
The financial impact of fraud in any industry is massive. According to the Financial Times article Fraud Costs Telecoms Industry $17bn a Year (paid subscription required), fraud costs the telecommunications industry $17 billion in lost revenues every year. Fraudsters constantly look for new technologies and devise new techniques. This changes fraud patterns and makes detection […]

Trigger cross-region replication of pre-existing objects using Amazon S3 inventory, Amazon EMR, and Amazon Athena
In Amazon Simple Storage Service (Amazon S3), you can use cross-region replication (CRR) to copy objects automatically and asynchronously across buckets in different AWS Regions. CRR is a bucket-level configuration, and it can help you meet compliance requirements and minimize latency by keeping copies of your data in different Regions. CRR replicates all objects in […]

Easily query AWS service logs using Amazon Athena
In this post, we’re open-sourcing a Python library known as Athena Glue Service Logs (AGSlogger). This library has predefined templates for parsing and optimizing the most popular log formats. The library provides a mechanism for defining schemas, managing partitions, and transforming data within an extract, transform, load (ETL) job in AWS Glue. AWS Glue is a serverless data transformation and cataloging service. You can use this library in conjunction with AWS Glue ETL jobs to enable a common framework for processing log data.

Visualize over 200 years of global climate data using Amazon Athena and Amazon QuickSight
Climate Change continues to have a profound effect on our quality of life. As a result, the investigation into sustainability is growing. Researchers in both the public and private sector are planning for the future by studying recorded climate history and using climate forecast models. To help explain these concepts, this post introduces the Global […]

Create real-time clickstream sessions and run analytics with Amazon Kinesis Data Analytics, AWS Glue, and Amazon Athena
April 2024: The content of this post is no longer relevant and deprecated. August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Clickstream events are small pieces of data that are generated continuously with high speed […]
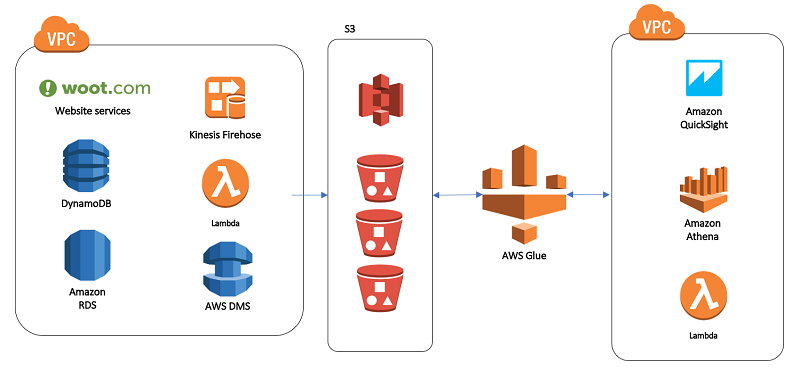
Our data lake story: How Woot.com built a serverless data lake on AWS
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. In this post, we talk about designing a cloud-native data warehouse as a replacement for our legacy data warehouse built on a relational database. At the beginning of the design process, the […]

Analyze and visualize nested JSON data with Amazon Athena and Amazon QuickSight
April 2024: This post was reviewed for accuracy. Although structured data remains the backbone for many data platforms, increasingly unstructured or semi-structured data is used to enrich existing information or create new insights. Amazon Athena enables you to analyze a wide variety of data. This includes tabular data in CSV or Apache Parquet files, data […]
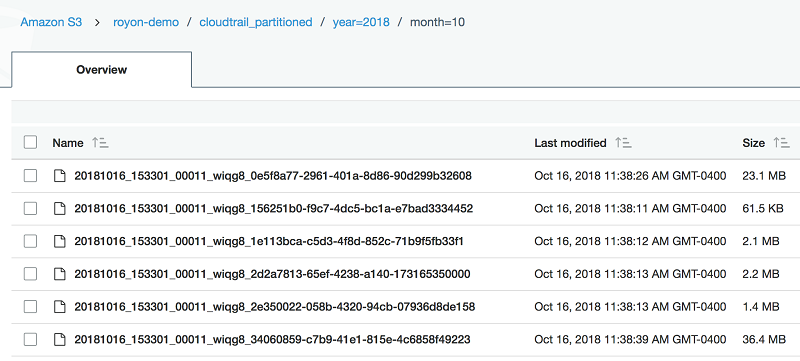
Use CTAS statements with Amazon Athena to reduce cost and improve performance
This blog post shows how to use the CREATE TABLE AS SELECT (CTAS statement) in Athena. It also shows how to automate the creation of unique tables that represent a subset of the AWS CloudTrail data. This helps us audit Amazon Athena usage.

Getting started: Training resources for Big Data on AWS
Whether you’ve just signed up for your first AWS account or you’ve been with us for some time, there’s always something new to learn as our services evolve to meet the ever-changing needs of our customers. To help ensure you’re set up for success as you build with AWS, we put together this quick reference guide for Big Data training and resources available here on the AWS site.
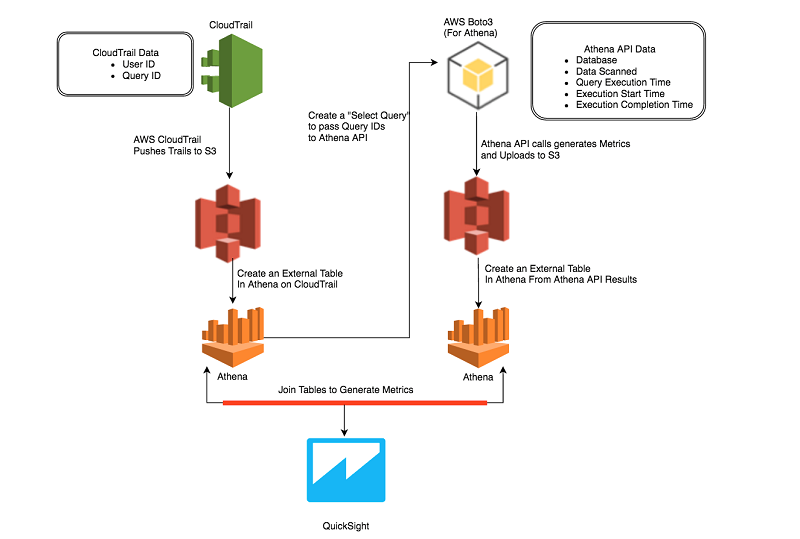
How Realtor.com Monitors Amazon Athena Usage with AWS CloudTrail and Amazon QuickSight
In this post, I discuss how to build a solution for monitoring Athena usage. To build this solution, you rely on AWS CloudTrail. CloudTrail is a web service that records AWS API calls for your AWS account and delivers log files to an S3 bucket.