AWS Big Data Blog
Build a modern data architecture on AWS with Amazon AppFlow, AWS Lake Formation, and Amazon Redshift: Part 2
In Part 1 of this post, we provided a solution to build the sourcing, orchestration, and transformation of data from multiple source systems, including Salesforce, SAP, and Oracle, into a managed modern data platform. Roche partnered with AWS Professional Services to build out this fully automated and scalable platform to provide the foundation for their machine learning goals. This post continues the data journey to include the steps undertaken to build an agile and extendable Amazon Redshift data warehouse platform using a DevOps approach.
The modern data platform ingests delta changes from all source data feeds once per night. The orchestration and transformations of the data is undertaken by dbt. dbt enables data analysts and engineers to write data transformation queries in a modular manner without having to maintain the run order manually. It compiles all code into raw SQL queries that run against the Amazon Redshift cluster. It also controls the dependency management within your queries and runs it in the correct order. dbt code is a combination of SQL and Jinja (a templating language); therefore, you can express logic such as if statements, loops, filters, and macros in your queries. dbt also contains automatic data validation job scheduling to measure the data quality of the data loaded. For more information about how to configure a dbt project within an AWS environment, see Automating deployment of Amazon Redshift ETL jobs with AWS CodeBuild, AWS Batch, and DBT.
Amazon Redshift was chosen as the data warehouse because of its ability to seamlessly access data stored in industry standard open formats within Amazon Simple Storage Service (Amazon S3) and rapidly ingest the required datasets into local, fast storage using well-understood SQL commands. Being able to develop extract, load, and transform (ELT) code pipelines in SQL was important for Roche to take advantage of the existing deep SQL skills of their data engineering teams.
A modern ELT platform requires a modern, agile, and highly performant data model. The solution in this post builds a data model using the Data Vault 2.0 standards. Data Vault has several compelling advantages for data-driven organizations:
- It removes data silos by storing all your data in reusable source system independent data stores keyed on your business keys.
- It’s a key driver for data integration at many levels, from multiple source systems, multiple local markets, multiple companies and affiliates, and more.
- It reduces data duplication. Because data is centered around business keys, if more than one system sends the same data, then multiple data copies aren’t needed.
- It holds all history from all sources; downstream you can access any data at any point in time.
- You can load data without contention or in parallel, and in batch or real time.
- The model can adapt to change with minimal impact. New business relationships can be made independently of the existing relationships
- The model is well established in the industry and naturally drives templated and reusable code builds.
The following diagram illustrates the high-level overview of the architecture:
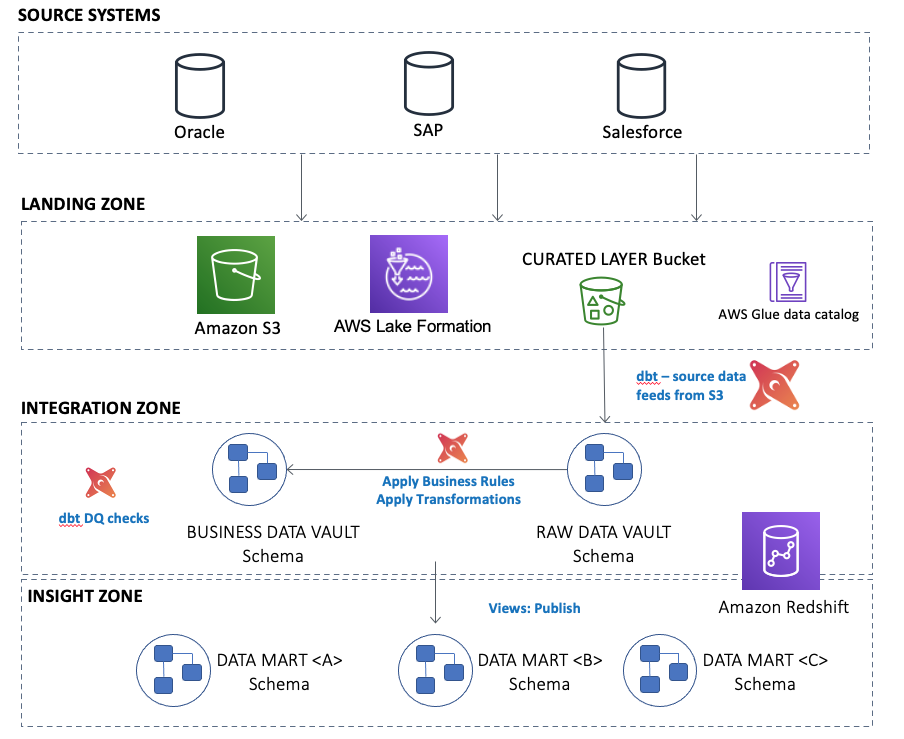
Amazon Redshift has several methods for ingesting data from Amazon S3 into the data warehouse cluster. For this modern data platform, we use a combination of the following methods:
- We use Amazon Redshift Spectrum to read data directly from Amazon S3. This allows the project to rapidly load, store, and use external datasets. Amazon Redshift allows the creation of external schemas and external tables to facilitate data being accessed using standard SQL statements.
- Some feeds are persisted in a staging schema within Amazon Redshift, for example larger data volumes and datasets that are used multiple times in subsequent ELT processing. dbt handles the orchestration and loading of this data in an incremental manner to cater to daily delta changes.
Within Amazon Redshift, the Data Vault 2.0 data model is split into three separate areas:
- Raw Data Vault within a schema called
raw_dv - Business Data Vault within a schema called
business_dv - Multiple Data Marts, each with their own schema
Raw Data Vault
Business keys are central to the success of any Data Vault project, and we created hubs within Amazon Redshift as follows:
Keep in mind the following:
- The business keys from one or more source feeds are written to the reusable
_bkcolumn; compound business keys should be concatenated together with a common separator between each element. - The primary key is stored in the
_pkcolumn and is a hashed value of the_bkcolumn. In this case, MD5 is the hashing algorithm used. Load_Dtsis the date and time of the insertion of this row.- Hubs hold reference data, which is typically smaller in volume than transactional data, so you should choose a distribution style of ALL for the most performant joining to other tables at runtime.
Because Data Vault is built on a common reusable notation, the dbt code is parameterized for each target. The Roche engineers built a Yaml-driven code framework to parameterize the logic for the build of each target table, enabling rapid build and testing of new feeds. For example, the preceding user hub contains parameters to identify source columns for the business key, source to target mappings, and physicalization choices for the Amazon Redshift target:
On reading the YAML configuration, dbt outputs the following, which is run against the Amazon Redshift cluster:
dbt also has the capability to add reusable macros to allow common tasks to be automated. The following example shows the construction of the business key with appropriate separators (the macro is called compound_key):
Historized reference data about each business key is stored in satellites. The primary key of each satellite is a compound key consisting of the _pk column of the parent hub and the Load_Dts. See the following code:
Keep in mind the following:
- The feed name is saved as part of the satellite name. This allows the loading of reference data from either multiple feeds within the same source system or from multiple source systems.
- Satellites are insert only; new reference data is loaded as a new row with an appropriate
Load_Dts. - The
HASH_DIFFcolumn is a hashed concatenation of all the descriptive columns within the satellite. The dbt code uses it to decide whether reference data has changed and a new row is to be inserted. - Unless the data volumes within a satellite become very large (millions of rows), you should choose a distribution choice of ALL to enable the most performant joins at runtime. For larger volumes of data, choose a distribution style of AUTO to take advantage of Amazon Redshift automatic table optimization, which chooses the most optimum distribution style and sort key based on the downstream usage of these tables.
Transactional data is stored in a combination of link and link satellite tables. These tables hold the business keys that contribute to the transaction being undertaken as well as optional measures describing the transaction.
Previously, we showed the build of the user hub and two of its satellites. In the following link table, the user hub foreign key is one of several hub keys in the compound key:
Keep in mind the following:
- The foreign keys back to each hub are a hash value of the business keys, giving a 1:1 join with the
_pkcolumn of each hub. - The primary key of this link table is a hash value of all of the hub foreign keys.
- The primary key gives direct access to the optional link satellite that holds further historized data about this transaction. The definition of the link satellites is almost identical to satellites; instead of the
_pkfrom the hub being part of the compound key, the_pkof the link is used. - Because data volumes are typically larger for links and link satellites than hubs or satellites, you can again choose AUTO distribution style to let Amazon Redshift choose the optimum physical table distribution choice. If you do choose a distribution style, then choose KEY on the
_pkcolumn for both the distribution style and sort key on both the link and any link satellites. This improves downstream query performance by co-locating the datasets on the same slice within the compute nodes and enables MERGE JOINS at run time for optimum performance.
In addition to the dbt code to build all the preceding targets in the Amazon Redshift schemas, the product contains a powerful testing tool that makes assertions on the underlying data contents. The platform continuously tests the results of each data load.
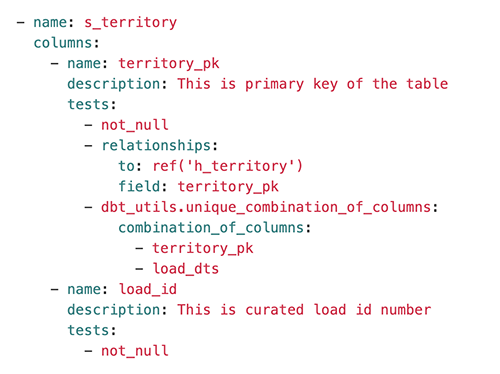
Tests are specified using a YAML file called schema.yml. For example, taking the territory satellite (s_territory), we can see automated testing for conditions, including ensuring the primary key is populated, its parent key is present in the territory hub (h_territory), and the compound key of this satellite is unique:
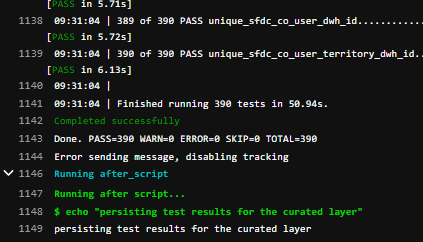
As shown in the following screenshot, the tests are clearly labeled as PASS or FAILED for quick identification of data quality issues.
Business Data Vault
The Business Data Vault is a vital element of any Data Vault model. This is the place where business rules, KPI calculations, performance denormalizations, and roll-up aggregations take place. Business rules can change over time, but the raw data does not, which is why the contents of the Raw Data Vault should never be modified.
The type of objects created in the Business Data Vault schema include the following:
- Type 2 denormalization based on either the latest load date timestamp or a business-supplied effective date timestamp. These objects are ideal as the base for a type 2 dimension view within a data mart.
- Latest row filtering based on either the latest load date timestamp or a business-supplied effective date timestamp. These objects are ideal as the base for a type 1 dimension within a data mart.
- For hubs with multiple independently loaded satellites, point-in-time (PIT) tables are created with the snapshot date set to one time per day.
- Where the data access requirements span multiple links and link satellites, bridge tables are created with the snapshot date set to one time per day.
In the following diagram, we show an example of user reference data from two source systems being loaded into separate satellite targets.
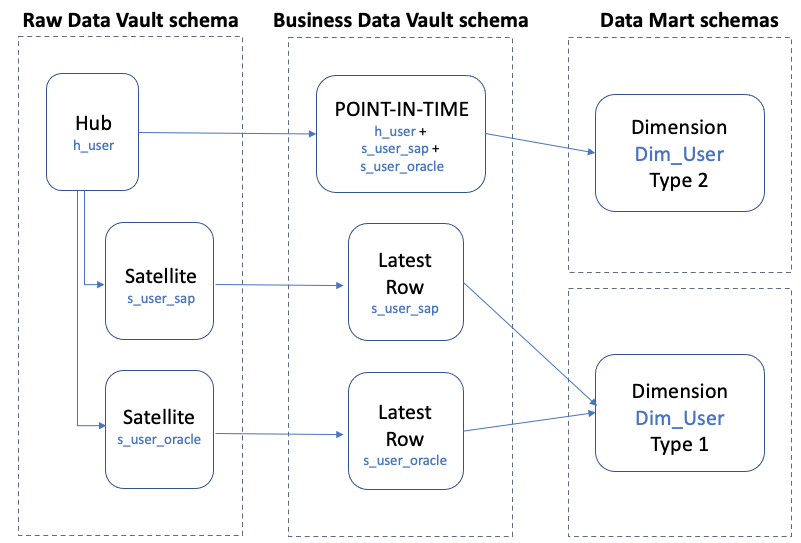
Keep in mind the following:
- You should create a separate schema for the Business Data Vault objects
- You can build several object types in the Business Data Vault:
- PIT and bridge targets are typically either tables or materialized views can be used for data that incrementally changes due to the auto refresh capabilities
- The type 2 and latest row selections from an underlying satellite are typically views because of the lower data volumes typically found in reference datasets
- Because the Raw Data Vault tables are insert only, to determine a timeline of changes, create a view similar to the following:
Data Marts
The work undertaken in the Business Data Vault means that views can be developed within the Data Marts to directly access the data without having to physicalize the results into another schema. These views may apply filters to the Business Vault objects, for example to filter only for data from specific countries, or the views may choose a KPI that has been calculated in the Business Vault that is only useful within this one data mart.
Conclusion
In this post, we detailed how you can use dbt and Amazon Redshift for continuous build and validation of a Data Vault model that stores all data from multiple sources in a source-independent manner while offering flexibility and choice of subsequent business transformations and calculations.
Special thanks go to Roche colleagues Bartlomiej Zalewski, Wojciech Kostka, Michalina Mastalerz, Kamil Piotrowski, Igor Tkaczyk, Andrzej Dziabowski, Joao Antunes, Krzysztof Slowinski, Krzysztof Romanowski, Patryk Szczesnowicz, Jakub Lanski, and Chun Wei Chan for their project delivery and support with this post.
About the Authors
 Dr. Yannick Misteli, Roche – Dr. Yannick Misteli is leading cloud platform and ML engineering teams in global product strategy (GPS) at Roche. He is passionate about infrastructure and operationalizing data-driven solutions, and he has broad experience in driving business value creation through data analytics.
Dr. Yannick Misteli, Roche – Dr. Yannick Misteli is leading cloud platform and ML engineering teams in global product strategy (GPS) at Roche. He is passionate about infrastructure and operationalizing data-driven solutions, and he has broad experience in driving business value creation through data analytics.
 Simon Dimaline, AWS – Simon Dimaline has specialised in data warehousing and data modelling for more than 20 years. He currently works for the Data & Analytics team within AWS Professional Services, accelerating customers’ adoption of AWS analytics services.
Simon Dimaline, AWS – Simon Dimaline has specialised in data warehousing and data modelling for more than 20 years. He currently works for the Data & Analytics team within AWS Professional Services, accelerating customers’ adoption of AWS analytics services.
 Matt Noyce, AWS – Matt Noyce is a Senior Cloud Application Architect in Professional Services at Amazon Web Services. He works with customers to architect, design, automate, and build solutions on AWS for their business needs.
Matt Noyce, AWS – Matt Noyce is a Senior Cloud Application Architect in Professional Services at Amazon Web Services. He works with customers to architect, design, automate, and build solutions on AWS for their business needs.
 Chema Artal Banon, AWS – Chema Artal Banon is a Security Consultant at AWS Professional Services and he works with AWS’s customers to design, build, and optimize their security to drive business. He specializes in helping companies accelerate their journey to the AWS Cloud in the most secure manner possible by helping customers build the confidence and technical capability.
Chema Artal Banon, AWS – Chema Artal Banon is a Security Consultant at AWS Professional Services and he works with AWS’s customers to design, build, and optimize their security to drive business. He specializes in helping companies accelerate their journey to the AWS Cloud in the most secure manner possible by helping customers build the confidence and technical capability.