AWS Big Data Blog
Migrate RDBMS or On-Premise data to EMR Hive, S3, and Amazon Redshift using EMR – Sqoop
This blog post shows how our customers can benefit by using the Apache Sqoop tool. This tool is designed to transfer and import data from a Relational Database Management System (RDBMS) into AWS – EMR Hadoop Distributed File System (HDFS), transform the data in Hadoop, and then export the data into a Data Warehouse (e.g. in Hive or Amazon Redshift).
To demonstrate the Sqoop tool, this post uses Amazon RDS for MySQL as a source and imports data in the following three scenarios:
- Scenario 1 — AWS EMR (HDFS -> Hive and HDFS)
- Scenario 2 — Amazon S3 (EMFRS), and then to EMR-Hive
- Scenario 3 — S3 (EMFRS), and then to Redshift

These scenarios help customers initiate the data transfer simultaneously, so that the transfer can run more expediently and cost efficient than a traditional ETL tool. Once the script is developed, customers can reuse it to transfer a variety of RDBMS data sources into EMR-Hadoop. Examples of these data sources are PostgreSQL, SQL Server, Oracle, and MariaDB.
We can also simulate the same steps for an on-premise RDBMS. This requires us to have the correct JDBC driver installed, and a network connection set up between the Corporate Data Center and the AWS Cloud environment. In this scenario, consider using either the AWS Direct Connect or AWS Snowball methods, based upon the data load volume and network constraints.
Prerequisites
To complete the procedures in this post, you need to perform the following tasks.
Step 1 — Launch an RDS Instance
By using the AWS Management Console or AWS CLI commands, launch MySQL instances with the desired capacity. The following example use the T2.Medium class with default settings.

To call the right services, copy the endpoint and use the following JDBC connection string exactly as shown. This example uses the US East (N. Virginia) us-east-1 AWS Region.
Step 2 — Test the connection and load sample data into RDS – MySQL
First, I used open source data sample from this location: https://bulkdata.uspto.gov/data/trademark/casefile/economics/2016/
Second, I loaded the following two tables:
- Events Data, from: https://bulkdata.uspto.gov/data/trademark/casefile/economics/2016/event.csv.zip
- US CLASS Data, from: https://bulkdata.uspto.gov/data/trademark/casefile/economics/2016/us_class.csv.zip
Third, I used MySQL Workbench tool to load sample tables and the Import/Export wizard to load data. This loads data automatically and creates the table structure.
Download Steps:
The following steps can help download the MySQL Database Engine and load above mentioned data source into tables: https://docs.thinkwithwp.com/AmazonRDS/latest/UserGuide/CHAP_GettingStarted.CreatingConnecting.MySQL.html#CHAP_GettingStarted.Connecting.MySQL
I used the following instructions on a Mac:
| Step A: Install Homebrew | Step B: Install MySQL |
| Homebrew is open source software package management system; At the time of this blog post, Homebrew has MySQL version 5.7.15 as the default formula in its main repository. | Enter the following command: $ brew info MySQL |
| To install Homebrew, open terminal, and enter: | Expected output: MySQL: stable 8.0.11 (bottled) |
| $ /usr/bin/ruby -e “$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)” | To install MySQL, enter: $ brew install MySQL |
| Homebrew then downloads and installs command line tools for Xcode 8.0 as part of the installation process) |
Fourth, when the download is complete, provide the connection string, port, SID to the connection parameter. In main console, click MySQL connections (+) sign à new connection window and provide connection parameter Name, hostname – RDS endpoint, port, username and password.

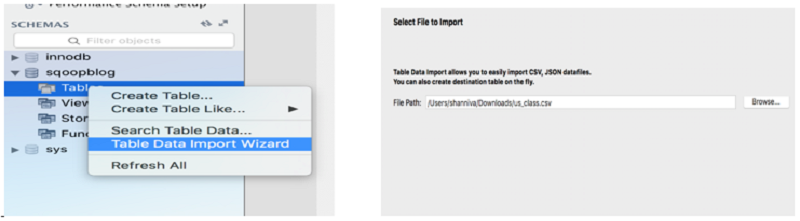

Step 3 — Launch EMR Cluster
Open the EMR console, choose Advanced option, and launch the cluster with the following options set:

Step 4 — Test the SSH access and install MySQL-connector-java-version-bin.jar in the EMR folder
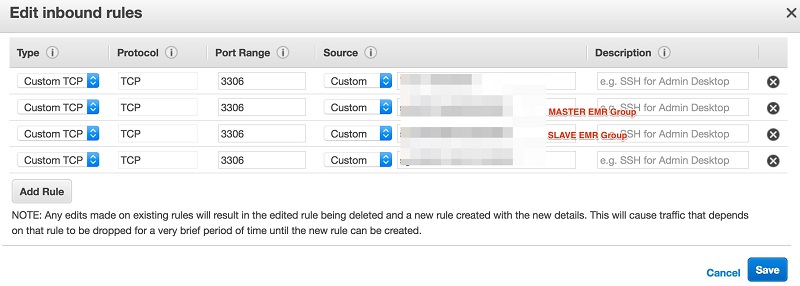
a. From the security groups for Master – click link and edit inbound rule to allow your PC or laptop IP to access the Master cluster.

b. Download the MySQL JDBC driver to your local PC from the following location: http://www.mysql.com/downloads/connector/j/5.1.html
c. Unzip the folder and copy the latest version of MySQL Connector available. (In my example, the version I use is MySQL-connector-java-5.1.46-bin.jar file).
d. Copy the file to the /var/lib/sqoop/ directory EMR master cluster. (Note: Because EMR Master doesn’t allow public access to the master node, I had to do a manual download from a local PC. I then used FileZila (Cross platform FTP application) to push the file.)
e. From your terminal, SSH to Master cluster, navigate to the /usr/lib/sqoop directory and copy this JAR file.
Note: This driver copy can be automated by using a bootstrap script to copy the driver file into an S3 path, and then transferring it into a master node. An example script would be:
Or, with temporary internet access to download file directly into Master node, copy code below:
In the Master node directory /usr/lib/sqoop, it should look like below.

- Before you begin working with EMR, you need at least two AWS Identity and Access Management (IAM) service roles with sufficient permissions to access the resources in your account.
- Amazon RDS and EMR Master and Slave clusters must have access to connect and then initiate the importing and exporting of data from MySQL RDS instances. For example, I am editing the RDS MySQL instance security group to allow an incoming connection from the EMR nodes – the Master security group and Slave Security group.
Step 5 — Test the connection to MySQL RDS from EMR
After you are logged in, run the following command in the EMR master cluster to validate your connection. It also checks the MySQL RDS login and runs the sample query to check table record count.
Note: This record count in the previous sample query should match with MySQL tables, as shown in the following example:

Import data into EMR – bulk load
To import data into EMR, you must first import the full data as a text file, by using the following query:
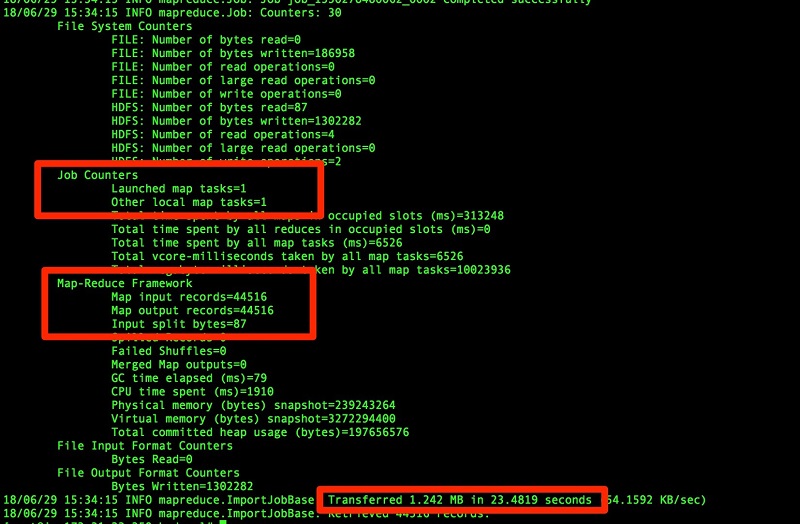
After the import completes, validate the extract file in respective hadoop directory location.

As shown in the previous example, the original table was not partitioned. Hence, it is extracted as one file and imported into the Hadoop folder. If this had been a larger table, it would have caused performance issues.
To address this issue, I show how performance increases if we select a partition table and use the direct method to export faster and more efficiently. I updated the event table, EVENTS_PARTITION, with the EVENT_DT column as the KEY Partition. I then copied the original table data into this table. In addition, I used the direct method to take advantage of utilizing MySQL partitions to optimize the efficiency of simultaneous data transfer.

Copy data and run stats.
Run the following query in MySQL Workbench to copy data and run stats:

After running the query in MySQL workbench, run the following Sqoop command in the EMR master node:
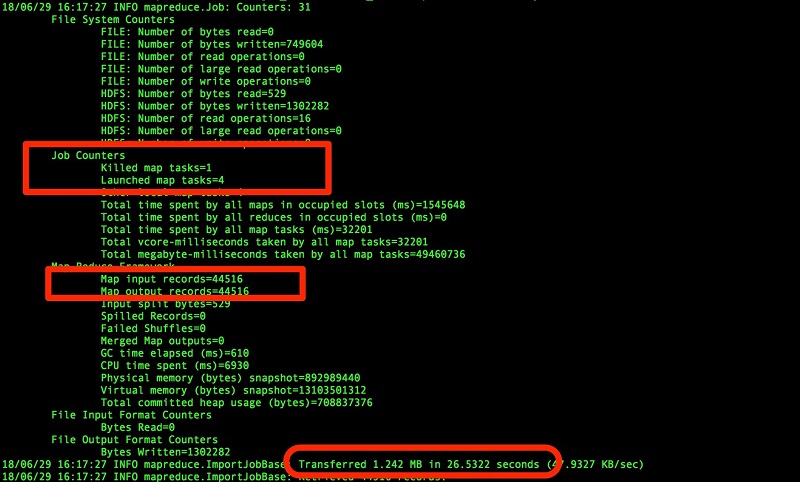
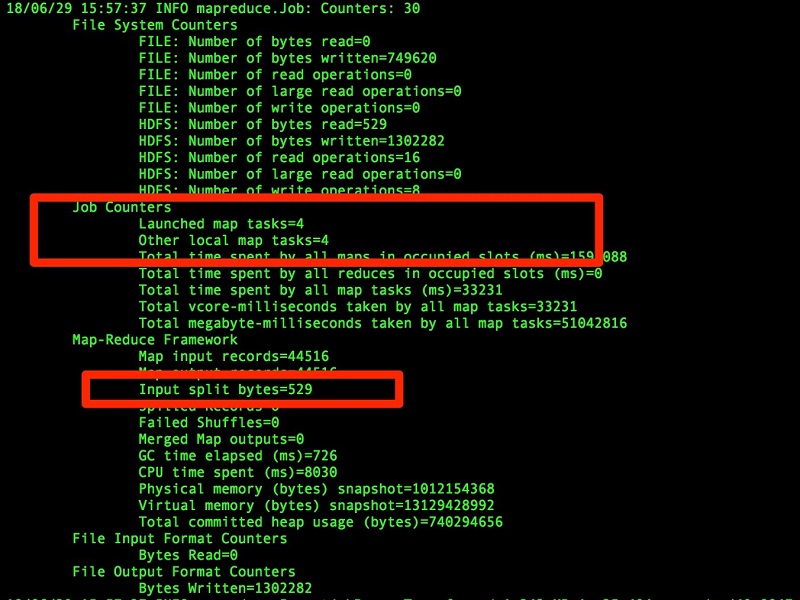 This example shows the performance improvement for the same command with the added argument option, which is a partitioned table. It also shows the data file split into four parts. Number of map reduce tasks automatically creates 4 based on table partition stats.
This example shows the performance improvement for the same command with the added argument option, which is a partitioned table. It also shows the data file split into four parts. Number of map reduce tasks automatically creates 4 based on table partition stats.

We can also use the m 10 argument to increase the map tasks, which equals to the number of input splits
Note: You can also split more data extract files during the import process by increasing the map reduce engine argument ( -m <<desired #> , as shown in the above sample code. Make sure that the extract files align with partition distribution, otherwise the output files will be out of order.


Consider the following additional options, if required to import selective columns.
In the following example, add the – COLUMN argument to the selective field.
For scenario 2, we will import the table data file into S3 bucket. Before you do, make sure that the EMR-EC2 instance group has added security to the S3 bucket. Run the following command in the EMR master cluster:
Import as Hive table – Full Load
Now, let’s try creating a hive table directly from the Sqoop command. This is a more efficient way to create hive tables dynamically, and we can later alter this table as an external table for any additional requirements. With this method, customers can save time creating and transforming data into hive through an automated approach.
 Now, let’s try a direct method to see how significantly the load performance and import time improves.
Now, let’s try a direct method to see how significantly the load performance and import time improves.
Following are additional optional to consider.
In the following example, add the COLUMN argument to the selective field and import into EMR as hive table.
Perform a free-form query and import into EMR as a hive table.
– For scenario 2, create a hive table manually from the S3 location. The following sample creates an external table from the S3 location. Run the select statement to check data counts.
Import note: Using Sqoop version 1.4.7, you can directly create hive tables by using scripts, as shown in the following sample code. This feature is supported in EMR 5.15.0.
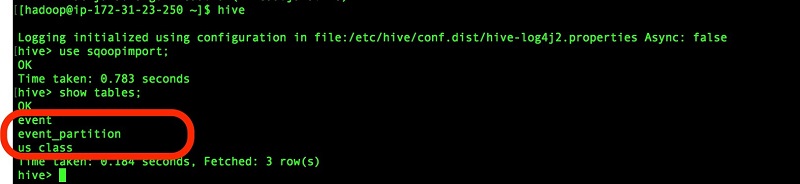
For the previous code samples, validate in Hive or Hue, and confirm the table records.

Import the full schema table into Hive.
Note: Create a Hive database in Hue or Hive first, and then run the following command in the EMR master cluster.
Import as Hive table – Incremental Load
Now, let’s try loading into Hive a sample incremental data feed for the partition table with the event date as the key. Use the following Sqoop command on an incremental basis.
In addition to initial data in table called EVENT_BASETABLE. I loaded the incremental data into EVENT_BASETABLE table. Let’s follow below steps and command to do incremental updates by sqoop, and import into Hive.
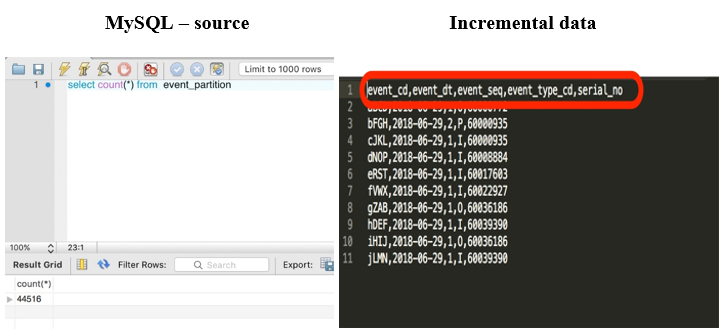
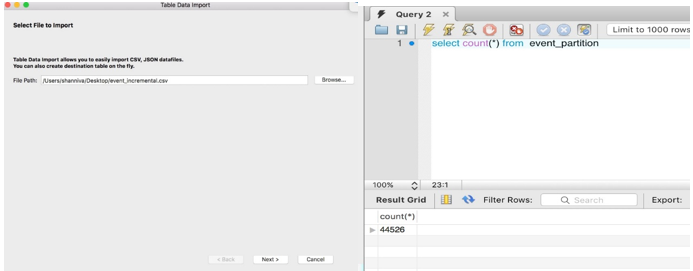

Once the incremental extracts are loaded into the Hadoop directory, you can create temporary, or incremental, tables in Hive and insert them into the main tables.
Alternatively, you can also perform the –query argument to do the incremental operation by joining various tables and condition arguments, and then inserting them into the main table.
All of these steps have been created as a Sqoop job to automate the flow.
Export data to Redshift
Now that data is imported into EMR- HDFS, S3 data store, let’s see how to use the Sqoop command to export data back into the Datawarehouse layer. In this case, we will use the Redshift cluster and demonstrate with an example.
Download the following JDBC API that our SQL client tool or application uses. If you’re not sure, download the latest version of the JDBC 4.2 API driver.
The class name for this driver is 1.2.15.1025/RedshiftJDBC41-1.2.15.1025.jar
com.amazon.redshift.jdbc42.Driver.
Copy this JAR file into the EMR master cluster node. SSH to Master cluster, navigate to /usr/lib/sqoop directory and copy this JAR file.
Note: Because EMR Master doesn’t allow public access to the master node, I had to do a manual download from a local PC. Also, I used FileZila to push the file.

Log in to the EMR master cluster and run this Sqoop command to copy the S3 data file into the Redshift cluster.
Launch the Redshift cluster. This example uses ds2.xLarge(Storage Node).

After Redshift launches, and the security group is associated with the EMR cluster to allow a connection, run the Sqoop command in EMR master node. This exports the data from the S3 location (shown previously in the Code 6 command) into the Redshift cluster as a table.
I created a table structure in Redshift as shown in the following example.
When the table is created, run the following command to import data into the Redshift table.
This command inserts the data records into the table.
For more information, see Loading Data from Amazon EMR.
For information about how to copy data back into RDBMS, see Use Sqoop to Transfer Data from Amazon EMR to Amazon RDS.
Summary
You’ve learned how to use Apache Sqoop on EMR to transfer data from RDBMS to an EMR cluster. You created an EMR cluster with Sqoop, processed a sample dataset on Hive, built sample tables in MySQL-RDS, and then used Sqoop to import the data into EMR. You also created a Redshift cluster and exported data from S3 using Sqoop.
You proved that Sqoop can perform data transfer in parallel, so execution is quick and more cost effective. You also simplified ETL data processing from the source to a target layer.
The advantages of Sqoop are:
- Fast and parallel data transfer into EMR — taking advantage of EMR compute instances to do an import process by removing external tool dependencies.
- An import process by using a direct-to-MySQL expediting query and pull performance into EMR Hadoop and S3.
- An Import Sequential dataset from Source system (Provided tables have primary keys) maintained simplifying growing need to migrate on-premised RDBMS data without re-architect
Sqoop pain points include.
- Automation by developer/Operations team community. This requires automating through workflow/job method either using Airflow support for Sqoop or other tools.
- For those tables doesn’t have primary keys and maintains legacy tables dependencies, will have challenges importing data incrementally. Recommendation is to do one-time migration through Sqoop bulk transfer and re-architect your source ingestion mechanism.
- Import/Export follows JDBC connection and doesn’t support other methods like ODBC or API calls.
If you have questions or suggestions, please comment below.
Additional Reading
If you found this post useful, be sure to check out Use Sqoop to transfer data from Amazon EMR to Amazon RDS and Seven tips for using S3DistCp on AMazon EMR to move data efficiently between HDFS and Amazon S3.
About the Author
 Nivas Shankar is a Senior Big Data Consultant at Amazon Web Services. He helps and works closely with enterprise customers building big data applications on the AWS platform. He holds a Masters degree in physics and is highly passionate about theoretical physics concepts. He enjoys spending time with his wife and two adorable kids. In his spare time, he takes his kids to tennis and football practice.
Nivas Shankar is a Senior Big Data Consultant at Amazon Web Services. He helps and works closely with enterprise customers building big data applications on the AWS platform. He holds a Masters degree in physics and is highly passionate about theoretical physics concepts. He enjoys spending time with his wife and two adorable kids. In his spare time, he takes his kids to tennis and football practice.