AWS Big Data Blog
How SimilarWeb analyze hundreds of terabytes of data every month with Amazon Athena and Upsolver
This is a guest post by Yossi Wasserman, a data collection & innovation team leader at Similar Web.
SimilarWeb, in their own words: SimilarWeb is the pioneer of market intelligence and the standard for understanding the digital world. SimilarWeb provides granular insights about any website or mobile app across all industries in every region. SimilarWeb is changing the way businesses make decisions by empowering marketers, analysts, sales teams, investors, executives and more with the insights they need to succeed in a digital world.
SimilarWeb is a market intelligence company that provides insights on what is happening across the digital world. Thousands of customers use these insights to make critical decisions on how to improve strategies in marketing, drive sales, make investments and more. The importance of the decision making that our solution empowers puts a huge emphasis on our capacity to effectively collect and use this information.
Specifically, the team I lead is charged with overseeing SimilarWeb’s mobile data collection. We currently process hundreds of TB of anonymous data every month.
The data-collection process is critical for SimilarWeb, because we can’t provide our customers’ insights based on a flawed or incomplete data. The data collection team needs analytics to track new types of data, partner integrations, overall performance and more with great effectiveness as quickly as possible. It’s imperative for my team to identify and address anomalies as early as possible. Any tool that supports this process gives us a significant advantage.
Technical challenges of SimilarWeb mobile data collection
Hundreds of TB of data is streamed into SimilarWeb every month from different sources. The data is complex. It contains hundreds of fields, many of which are deeply nested, in addition to some with null values. This complexity creates a technical challenge because the data must be cleaned, normalized and prepared for querying.
The first option was to use our existing on-premises Hadoop cluster, which processes all of SimilarWeb’s data in a daily batch process that takes a few hours to run. For our business-critical monitoring, a 24-hour delay is not acceptable.
We considered developing a new process using Hadoop. But that would require our team to focus away from daily operations to code, scale, and maintain extract, transform and load (ETL) jobs. Also, having to deal with different databases deflects our team’s focus on operations. Therefore, we wanted an agile solution where every team member could create new reports, investigate discrepancies, and add automated tests.
We also had a count distinct problem, which caused a compute bottleneck. The count distinct problem is the difficulty of finding the number of distinct elements in a data stream containing repeated elements. We track the number of unique visitors for billions of possible segments; for example, by device, operating system, or country. Count distinct is a non-additive aggregation, so calculating an accurate number of unique visitors usually requires many memory-intensive compute nodes.
Why we chose Amazon Athena
We chose Amazon Athena to solve these. Athena offered us:
- Fast queries using SQL — our team wants to use SQL to query the data, but traditional SQL databases are hard to scale to hundreds of terabytes. Athena works for us because it runs distributed SQL queries on Amazon S3 using Apache Presto.
- Low maintenance — Athena is a serverless platform that doesn’t require IT operating costs.
- Low cost — storing so much data in a data warehouse is expensive, because of the number of database nodes required. We query only a small portion of the data, so the Athena price of $0.005 per GB scanned is appealing.
Why we chose Upsolver
As another part of our solution, we chose Upsolver. Upsolver bridges together the data lake and the analytics users who aren’t big data engineers. Its cloud data lake platform helps organizations efficiently manage a data lake. Upsolver enables a single user to control big streaming data from ingestion to management and preparation for analytics platforms like Athena, Amazon Redshift and OpenSearch Service.
We chose Upsolver for these reasons:
- Upsolver allows us to provide hourly statistics to Athena and S3. As a result, we can identify anomalies after 1 hour instead of 24 hours.
- Upsolver is easy to configure at scale by using its graphical user interface (GUI). It took us about an hour to build a pipeline from Kafka to Athena, including the number of distinct visitors for every segment we track.
- Upsolver’s Stream Discovery tool helped us create our tables in Athena. We saw the exact distribution of values for every field in our JSON, which helped us find the fields we wanted and make necessary corrections.
- Upsolver is easy to maintain. Upsolver is a serverless platform with little IT overhead.
- Our data remains private in our own S3 bucket. Although our data is anonymous, we didn’t want it out of our control.
Our solution
Our solution includes Athena for SQL analytics, S3 for events storage, and Upsolver for data preparation. The following diagram shows our solution from start to finish.
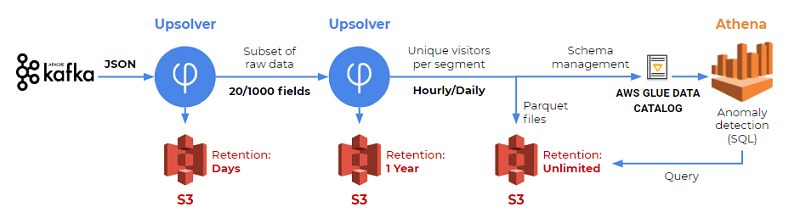
In the following sections, we walk through our solution step-by-step.
Step 1: Get the raw data from Kafka to S3
Our data resides on-premises in Kafka. We use Upsolver’s connector to read events from Kafka and store them on S3. We needed to do this only once. The following example shows how we created the data source in Kafka.

Step 2: Create a reduced stream on S3
Storing hundreds of TB on S3 wasn’t necessary for the kind of analytics we needed to perform. Our full stream includes about 400 fields, although we need only 20–30 of them. We used Upsolver to create a reduced stream. This reduced stream contains some of the fields from the original stream, plus some new calculated fields we added with Upsolver. We store the output in S3.
We also knew that our Kafka topic contained events that weren’t relevant to our use case. As another part of reducing our stream, we filtered out those events using Upsolver. Although we keep the raw data for only one day, we store the reduced stream for one year. The reduced stream enables us to stay dynamic — using a one-year event source, but at a much lower cost than storing the full raw data.
Step 3: Create and manage tables in Athena
AWS Glue Data Catalog and Amazon S3 are critical when using Athena. Athena takes advantage of a concept known as external tables. This means tables’ schema definitions are managed in the AWS Glue Data Catalog and the data is managed in S3.
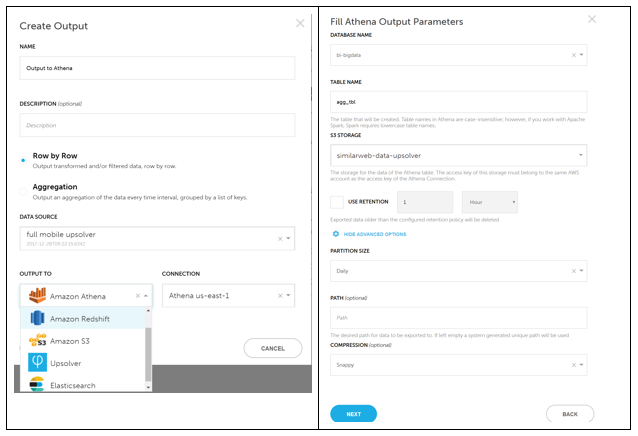
We mapped the nested JSON source files to a flat output table backed by Parquet files by using the Upsolver Create Output feature. When Upsolver is run, it creates two different types of output:
- Flat Parquet files on S3, as shown in the following screenshot. We frequently use the aggregation option, because we track the number of distinct users for various segments on an hourly basis.
- Four added columns for our tables, as shown in the following example. Our tables’ schema change over time because of schema evolution and partition management. Because we’re using daily partitions, Upsolver added the four columns to our tables. Upsolver manages all of these changes for us directly in the AWS Glue Data Catalog.

Step 4: Perform SQL analytics in Athena
Our developers use the Athena SQL console to look for anomalies in new data. Usually a spike or a drop in the number of distinct users per tracked dimension indicates an anomaly. Examples of tracked dimensions can be SDK versions, devices, or operating systems.
We also track various fields, in real-time, for production debugging. Also, in some cases, we add queries to continuous integrations jobs.
Conclusion
In this post, I discussed our main challenges when dealing with large amounts of data. I showed you how we selected Amazon Athena and Upsolver to build a performant, cost effective, and efficient solution that everyone on the team can use. Overall, this new pipeline helped improve our efficiency and reduce the time from ingestion to insight from 24 hours to minutes.
About the Author
 Yossi Wasserman is a data collection & innovation team leader at SimilarWeb. He holds a BSc in Software Engineering, and over then 10 years of experience in the field of mobile app development.
Yossi Wasserman is a data collection & innovation team leader at SimilarWeb. He holds a BSc in Software Engineering, and over then 10 years of experience in the field of mobile app development.