AWS Big Data Blog
Enable fine-grained data access in Zeppelin Notebook with AWS Lake Formation
This post explores how you can use AWS Lake Formation integration with Amazon EMR to implement fine-grained column-level access controls while using Spark in a Zeppelin Notebook.
My previous post Extract Salesforce.com data using AWS Glue and analyzing with Amazon Athena showed you a simple use case for extracting any Salesforce object data using AWS Glue and Apache Spark, saving it to Amazon Simple Storage Service (Amazon S3), cataloging the data using the Data Catalog in Glue, and querying it using Amazon Athena.
Preparing your data
For simplicity of setup and to build on the concept of fine-grained access control of data, you use the same data that you extracted from the Salesforce account object in the post Extract Salesforce.com data using AWS Glue and analyzing with Amazon Athena. Follow all the steps from the preceding post to create a table called sfdc_output, which you can query in Athena and see all the fields of the account object.
In the following sections, you see how to restrict access to only a select set of columns in this table for a user who queries this data using Spark SQL in Zeppelin Notebook.
Setting up Lake Formation
Lake Formation aims to simplify and accelerate the creation of data lakes. Amazon EMR integrates with Lake Formation and its security model to allow fine-grained access control on databases, tables, and columns defined in the Data Catalog for data stored in Amazon S3. Users authenticate against third-party identity providers (IdPs) through SAML, and the principal is used to determine if the user has the appropriate access to the columns within a table and partitions in the Data Catalog.
Lake Formation provides its own permissions model that augments the AWS Identity and Access Management (IAM) permissions model. This centrally defined permissions model enables fine-grained access to data stored in data lakes through a simple grant and revoke mechanism.
The following diagram illustrates the workflow.
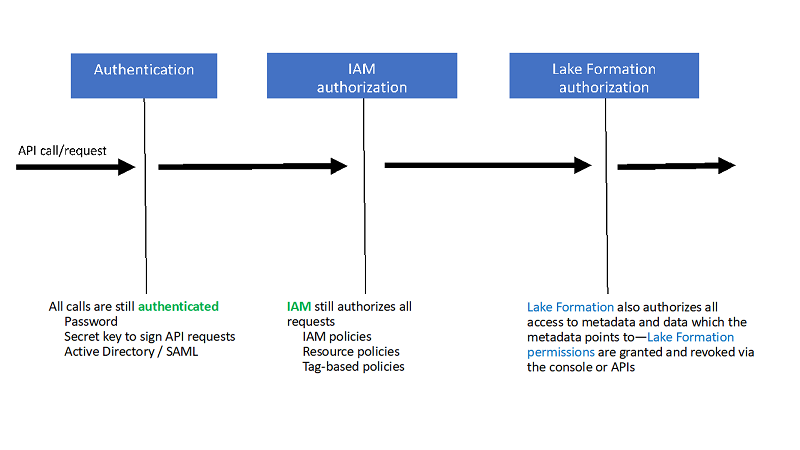
In the preceding flow, you still authenticate the principal at the IdP, and use the IAM policy to authorize access to AWS resources. Additionally, you use Lake Formation to authorize data access. When a principal attempts to run a query in Amazon EMR against a table set up with Lake Formation, Amazon EMR requests temporary credentials for data access from Lake Formation. Lake Formation returns temporary credentials and allows data access.
For more information about setting up Lake Formation, see Setting Up AWS Lake Formation. For this use case, you want to enable the integration of Amazon EMR with Lake Formation so you can use Zeppelin Notebook to see the fine-grained data access controls in action. For this post, I’ve configured the authentication module using the third-party SAML provider Auth0. You can also use Okta or Active Directory Federation Services (ADFS) to set up authentication with the IdP of your choice. For more information about setting up IdP and to launch Amazon EMR with an AWS CloudFormation stack, see Integration with Amazon EMR.
Granting fine-grained access with Lake Formation
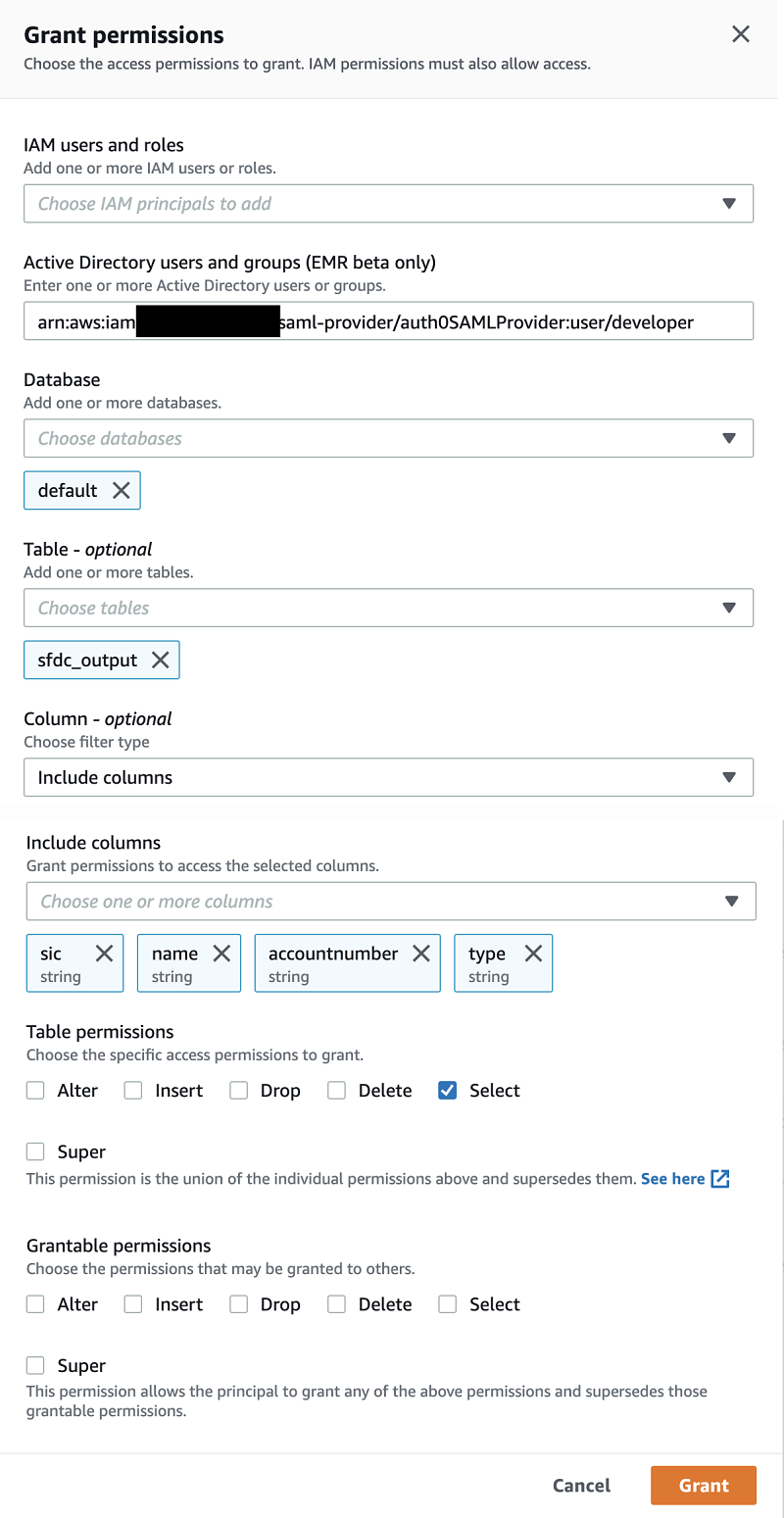
For the purpose of demonstrating fine-grained data access, I created a user called developer in Auth0. Suppose that for your table sfdc_output, you don’t want to give this user access to certain billing-related fields. Complete the following steps:
- On the Lake Formation console, choose Data permissions.
- For Active Directory users and groups, enter the ARN for the user developer.
- For Database, choose default.
- For Table, choose sfdc_output.
- For Column, choose Include columns.
- For Include columns, choose sic, name, accountnumber, and type.
These are the specific columns from this table that you want the developer user to have access to.
- For Table permissions¸ select Select.
- Choose Grant.
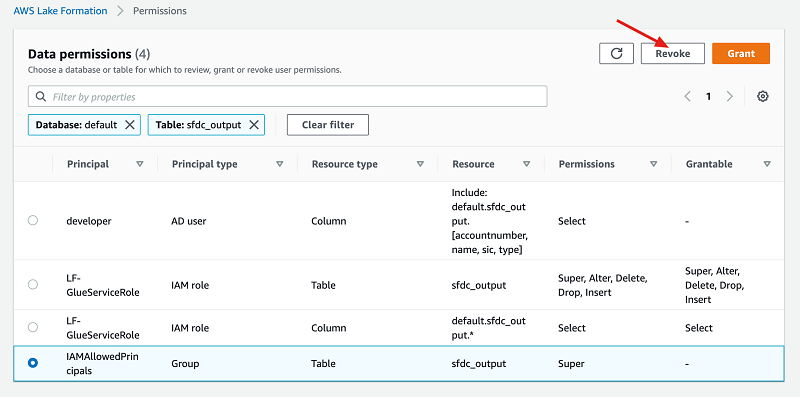
After you grant specific permissions to the developer user, you have to remove LFPassthrough access by revoking Super access given to the IAMAllowedPrincipals group. For backward compatibility, Lake Formation only passes through IAM permissions for all existing Data Catalog tables. Revoking Super access enables it to apply specific Lake Formation grants and IAM permissions.
- On the Lake Formation console, choose Permissions.
- Select IAMAllowedPrincipals for sfdc_output
- Choose Revoke.
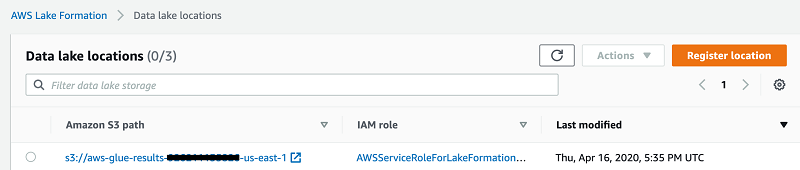
You also need to register the Amazon S3 location in Lake Formation where the table data resides.
- On the Lake Formation console, choose Data lake locations.
- Select the Amazon S3 path for your table.
- Choose Register location.
Running a query
You can now test the restrictions by running a query.
Log in to the Zeppelin console using its URL. To access Zeppelin Notebook, you must first ensure that your cluster’s master security group is configured to allow access to the Proxy Agent (port 8442) from your desktop. Do not open your EMR master to the public (0.0.0.0/0 or ::0). It redirects the link to the IdP provider for login and authentication with the developer user credentials. After authentication is complete, create a new notebook and run a Spark SQL query against the sfdc_output table.
The following screenshot shows that even though the developer user queried for the full table, only the columns that you granted them access to in Lake Formation are visible.
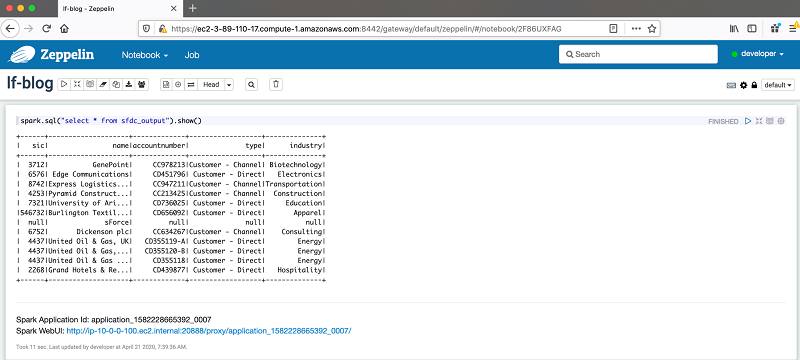
As an additional exercise, you can create another user in IdP and give a different set of column access in Lake Formation to that user. Query the table again by logging in as that user and observe the corresponding security mechanism being applied.
Querying with Jupyter Notebook
If you want to use Jupyter Notebook, you can spin up an Amazon EMR notebook, attach it to the running cluster, and run the same query in it. The following screenshot shows that the results are the same.
 Conclusion
Conclusion
This post showed how Lake Formation provides fine-grained, column-level access to tables in the Data Catalog using Spark. It enables federated single sign-on to Apache Zeppelin or Amazon EMR notebooks from your enterprise identity system that is compatible with SAML 2.0.
You can try this solution for your use-cases and if you have comments or feedback, please leave them below.
About the Authors

Behram Irani is a Senior Data Architect at Amazon Web Services.
 Rahul Sonawane is a Senior Consultant, Big Data at Amazon Web Services.
Rahul Sonawane is a Senior Consultant, Big Data at Amazon Web Services.