AWS Big Data Blog
Category: Amazon Simple Storage Service (S3)
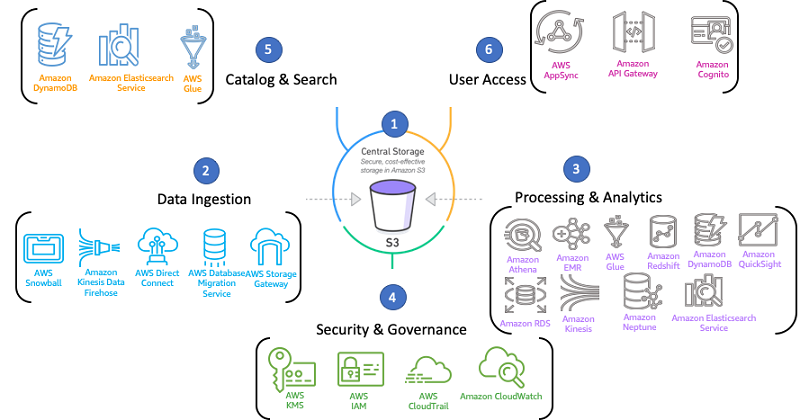
Build an AWS Well-Architected environment with the Analytics Lens
Building a modern data platform on AWS enables you to collect data of all types, store it in a central, secure repository, and analyze it with purpose-built tools. Yet you may be unsure of how to get started and the impact of certain design decisions. To address the need to provide advice tailored to specific technology and application domains, AWS added the concept of well-architected lenses 2017. AWS now is happy to announce the Analytics Lens for the AWS Well-Architected Framework. This post provides an introduction of its purpose, topics covered, common scenarios, and services included.

How Siemens built a fully managed scheduling mechanism for updates on Amazon S3 data lakes
Siemens is a global technology leader with more than 370,000 employees and 170 years of experience. To protect Siemens from cybercrime, the Siemens Cyber Defense Center (CDC) continuously monitors Siemens’ networks and assets. To handle the resulting enormous data load, the CDC built a next-generation threat detection and analysis platform called ARGOS. ARGOS is a […]

Analyze your Amazon S3 spend using AWS Glue and Amazon Redshift
The AWS Cost & Usage Report (CUR) tracks your AWS usage and provides estimated charges associated with that usage. You can configure this report to present the data at hourly or daily intervals, and it is updated at least one time per day until it is finalized at the end of the billing period. The […]
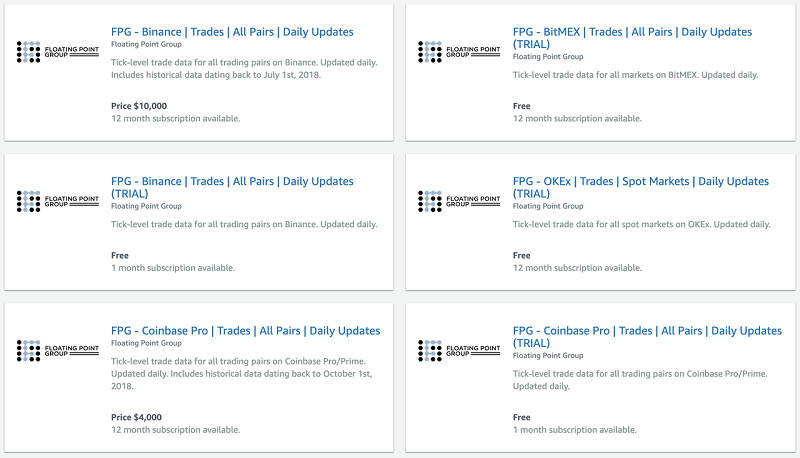
Collect and distribute high-resolution crypto market data with ECS, S3, Athena, Lambda, and AWS Data Exchange
This is a guest post by Floating Point Group. In their own words, “Floating Point Group is on a mission to bring institutional-grade trading services to the world of cryptocurrency.” The need and demand for financial infrastructure designed specifically for trading digital assets may not be obvious. There’s a rather pervasive narrative that these coins […]
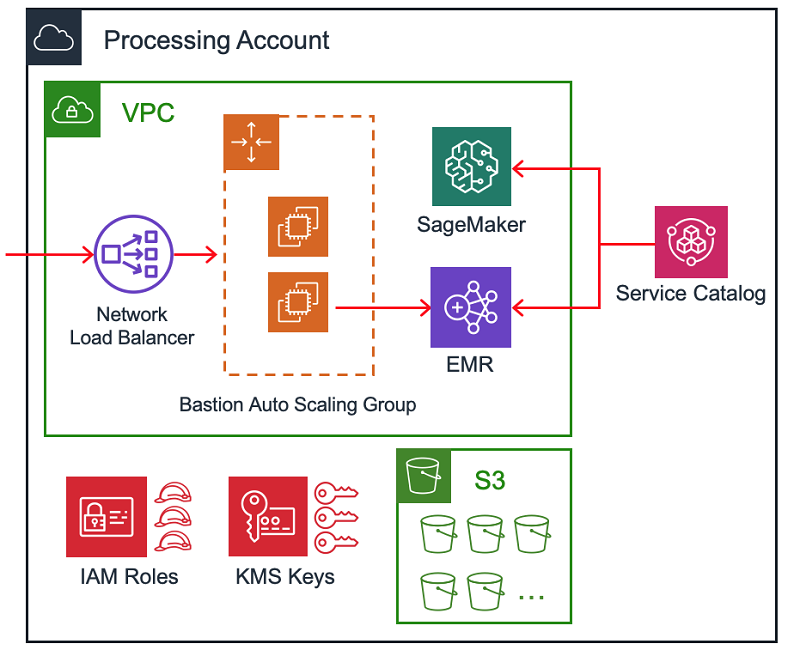
Provisioning the Intuit Data Lake with Amazon EMR, Amazon SageMaker, and AWS Service Catalog
This post outlines the approach taken by Intuit, though it is important to remember that there are many ways to build a data lake (for example, AWS Lake Formation). We’ll cover the technologies and processes involved in creating the Intuit Data Lake at a high level, including the overall structure and the automation used in provisioning accounts and resources. Watch this space in the future for more detailed blog posts on specific aspects of the system, from the other teams and engineers who worked together to build the Intuit Data Lake.
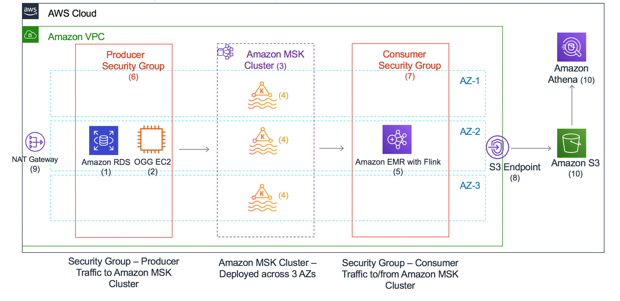
Extract Oracle OLTP data in real time with GoldenGate and query from Amazon Athena
This post describes how you can improve performance and reduce costs by offloading reporting workloads from an online transaction processing (OLTP) database to Amazon Athena and Amazon S3. The architecture described allows you to implement a reporting system and have an understanding of the data that you receive by being able to query it on arrival.
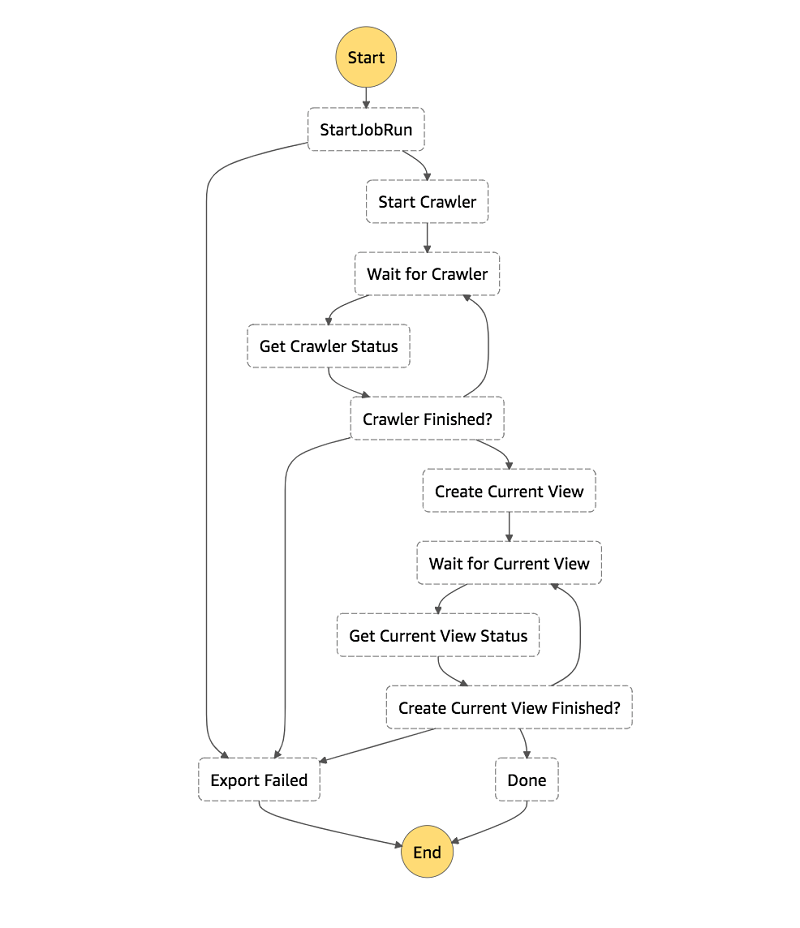
How to export an Amazon DynamoDB table to Amazon S3 using AWS Step Functions and AWS Glue
In this post, I show you how to use AWS Glue’s DynamoDB integration and AWS Step Functions to create a workflow to export your DynamoDB tables to S3 in Parquet. I also show how to create an Athena view for each table’s latest snapshot, giving you a consistent view of your DynamoDB table exports.

Trigger cross-region replication of pre-existing objects using Amazon S3 inventory, Amazon EMR, and Amazon Athena
In Amazon Simple Storage Service (Amazon S3), you can use cross-region replication (CRR) to copy objects automatically and asynchronously across buckets in different AWS Regions. CRR is a bucket-level configuration, and it can help you meet compliance requirements and minimize latency by keeping copies of your data in different Regions. CRR replicates all objects in […]

Improve Apache Spark write performance on Apache Parquet formats with the EMRFS S3-optimized committer
November 2024: This post was reviewed and updated for accuracy. The EMRFS S3-optimized committer is a new output committer available for use with Apache Spark jobs as of Amazon EMR 5.19.0. This committer improves performance when writing Apache Parquet files to Amazon S3 using the EMR File System (EMRFS). In this post, we run a performance […]
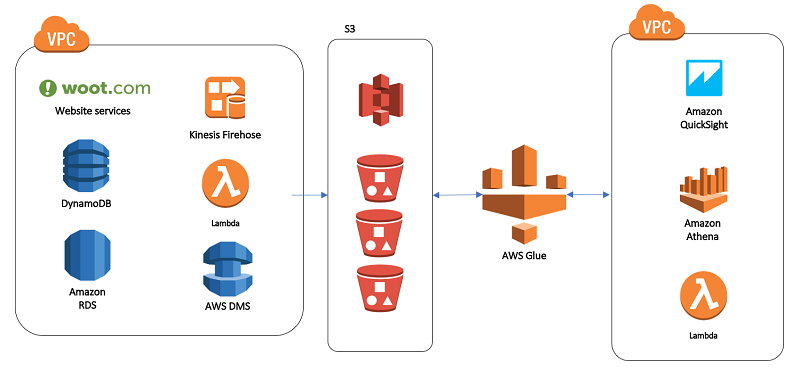
Our data lake story: How Woot.com built a serverless data lake on AWS
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. In this post, we talk about designing a cloud-native data warehouse as a replacement for our legacy data warehouse built on a relational database. At the beginning of the design process, the […]