AWS Big Data Blog
Category: Intermediate (200)

Accelerate your data and AI workflows by connecting to Amazon SageMaker Unified Studio from Visual Studio Code
In this post, we demonstrate how to connect your local VS Code to SageMaker Unified Studio so you can build complete end-to-end data and AI workflows while working in your preferred development environment.

Migrating from API keys to service account tokens in Grafana dashboards using Terraform
In this blog post, we walk through how to migrate from API keys to service account tokens when automating Amazon Managed Grafana resource management. We will also show how to securely store tokens using AWS Secrets Manager and automate token rotation with AWS Lambda.

Use the Amazon DataZone upgrade domain to Amazon SageMaker and expand to new SQL analytics, data processing, and AI uses cases
Don’t miss our upcoming webinar! Register here to join AWS experts as they dive deeper and share practical insights for upgrading to SageMaker. Amazon DataZone and Amazon SageMaker announced a new feature that allows an Amazon DataZone domain to be upgraded to the next generation of SageMaker, making the investment customers put into developing Amazon […]

Build a streaming data mesh using Amazon Kinesis Data Streams
AWS provides two primary solutions for streaming ingestion and storage: Amazon Managed Streaming for Apache Kafka (Amazon MSK) or Amazon Kinesis Data Streams. These services are key to building a streaming mesh on AWS. In this post, we explore how to build a streaming mesh using Kinesis Data Streams.

Introducing restricted classification terms for governed classification in Amazon SageMaker Catalog
Security and compliance concerns are key considerations when customers across industries rely on Amazon SageMaker Catalog. Customers use SageMaker Catalog to organize, discover, and govern data and machine learning (ML) assets. A common request from domain administrators is the ability to enforce governance controls on certain metadata terms that carry compliance or policy significance. Examples […]

Announcing SageMaker Unified Studio Workshops for Financial Services
In this post, we’re excited to announce the release of four Amazon SageMaker Unified Studio publicly available workshops that are specific to each FSI segment: insurance, banking, capital markets, and payments. These workshops can help you learn how to deploy Amazon SageMaker Unified Studio effectively for business use cases.
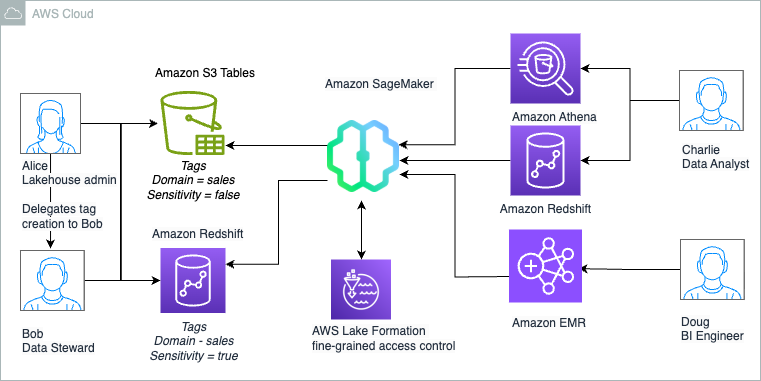
The Amazon SageMaker Lakehouse Architecture now supports Tag-Based Access Control for federated catalogs
We are now announcing support for Lake Formation tag-based access control (LF-TBAC) to federated catalogs of S3 Tables, Redshift data warehouses, and federated data sources such as Amazon DynamoDB, MySQL, PostgreSQL, SQL Server, Oracle, Amazon DocumentDB, Google BigQuery, and Snowflake. In this post, we illustrate how to manage S3 Tables and Redshift tables in the lakehouse using a single fine-grained access control mechanism of LF-TBAC. We also show how to access these lakehouse tables using your choice of analytics services, such as Athena, Redshift, and Apache Spark in Amazon EMR Serverless.

Amazon SageMaker Catalog expands discoverability and governance for Amazon S3 general purpose buckets
In July 2025, Amazon SageMaker announced support for Amazon Simple Storage Service (Amazon S3) general purpose buckets and prefixes in Amazon SageMaker Catalog that delivers fine-grained access control and permissions through S3 Access Grants. In this post, we explore how this integration addresses key challenges our customers have shared with us, and how data producers, such as administrators and data engineers, can seamlessly share and govern S3 buckets and prefixes using S3 Access Grants, while making it readily discoverable for data consumers.

Build enterprise-scale log ingestion pipelines with Amazon OpenSearch Service
In this post, we share field-tested patterns for log ingestion that have helped organizations successfully implement logging at scale, while maintaining optimal performance and managing costs effectively. A well-designed log analytics solution can help support proactive management in a variety of use cases, including debugging production issues, monitoring application performance, or meeting compliance requirements.

Transform your data to Amazon S3 Tables with Amazon Athena
This post demonstrates how Amazon Athena CREATE TABLE AS SELECT (CTAS) simplifies the data transformation process through a practical example: migrating an existing Parquet dataset into Amazon S3 Tables.