AWS Big Data Blog
Category: Intermediate (200)

Automate secure access to Amazon MWAA environments using existing OpenID Connect single-sign-on authentication and authorization
Customers use Amazon Managed Workflows for Apache Airflow (Amazon MWAA) to run Apache Airflow at scale in the cloud. They want to use their existing login solutions developed using OpenID Connect (OIDC) providers with Amazon MWAA; this allows them to provide a uniform authentication and single sign-on (SSO) experience using their adopted identity providers (IdP) […]

Introducing field-based coloring experience for Amazon QuickSight
Color plays a crucial role in visualizations. It conveys meaning, captures attention, and enhances aesthetics. You can quickly grasp important information when key insights and data points pop with color. However, it’s important to use color judiciously to enhance readability and ensure correct interpretation. Color should also be accessible and consistent to enable users to […]

How Amazon Finance Automation built a data mesh to support distributed data ownership and centralize governance
Amazon Finance Automation (FinAuto) is the tech organization of Amazon Finance Operations (FinOps). Its mission is to enable FinOps to support the growth and expansion of Amazon businesses. It works as a force multiplier through automation and self-service, while providing accurate and on-time payments and collections. FinAuto has a unique position to look across FinOps […]

Configure end-to-end data pipelines with Etleap, Amazon Redshift, and dbt
This blog post is co-written with Zygimantas Koncius from Etleap. Organizations use their data to extract valuable insights and drive informed business decisions. With a wide array of data sources, including transactional databases, log files, and event streams, you need a simple-to-use solution capable of efficiently ingesting and transforming large volumes of data in real […]

Level up your React app with Amazon QuickSight: How to embed your dashboard for anonymous access
Using embedded analytics from Amazon QuickSight can simplify the process of equipping your application with functional visualizations without any complex development. There are multiple ways to embed QuickSight dashboards into application. In this post, we look at how it can be done using React and the Amazon QuickSight Embedding SDK. Dashboard consumers often don’t have […]

Getting started guide for near-real time operational analytics using Amazon Aurora zero-ETL integration with Amazon Redshift
November 2023: This post was reviewed and updated to include the latest enhancements in Amazon Aurora MySQL zero-ETL integration with Amazon Redshift on general availability (GA). Amazon Aurora zero-ETL integration with Amazon Redshift was announced at AWS re:Invent 2022 and is now generally available (GA) for Aurora MySQL 3.05.0 (compatible with MySQL 8.0.32) and higher […]
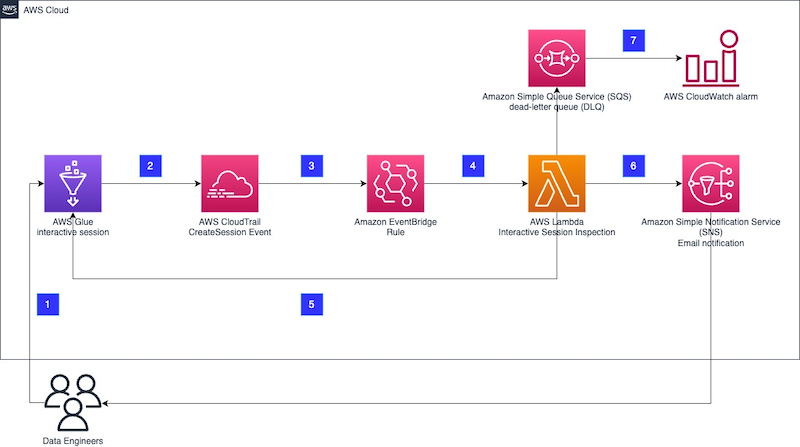
Enforce boundaries on AWS Glue interactive sessions
AWS Glue interactive sessions allow engineers to build, test, and run data preparation and analytics workloads in an interactive notebook. Interactive sessions provide isolated development environments, take care of the underlying compute cluster, and allow for configuration to stop idling resources. Glue interactive sessions provides default recommended configurations, and also allows users to customize the […]

Get started managing partitions for Amazon S3 tables backed by the AWS Glue Data Catalog
Large organizations processing huge volumes of data usually store it in Amazon Simple Storage Service (Amazon S3) and query the data to make data-driven business decisions using distributed analytics engines such as Amazon Athena. If you simply run queries without considering the optimal data layout on Amazon S3, it results in a high volume of […]

Amazon OpenSearch Service’s vector database capabilities explained
Using Amazon OpenSearch Service’s vector database capabilities, you can implement semantic search, Retrieval Augmented Generation (RAG) with LLMs, recommendation engines, and search in rich media. Learn how.

Efficiently crawl your data lake and improve data access with an AWS Glue crawler using partition indexes
In today’s world, customers manage vast amounts of data in their Amazon Simple Storage Service (Amazon S3) data lakes, which requires convoluted data pipelines to continuously understand the changes in the data layout and make them available to consuming systems. AWS Glue crawlers provide a straightforward way to catalog data in the AWS Glue Data […]