AWS Big Data Blog
Category: Database

How to build a front-line concussion monitoring system using AWS IoT and serverless data lakes – Part 1
In this two-part series, we show you how to build a data pipeline in support of a data lake. We use key AWS services such as Amazon Kinesis Data Streams, Kinesis Data Analytics, Kinesis Data Firehose, and AWS Lambda. In part 2, we focus on generating simple inferences from that data that can support RTP parameters.

Narrativ is helping producers monetize their digital content with Amazon Redshift
Narrativ, in their own words: Narrativ is building monetization technology for the next generation of digital content producers. Our product portfolio includes a real-time bidding platform and visual storytelling tools that together generate millions of dollars of advertiser value and billions of data points each month. At Narrativ, we have seen massive growth in our […]

Migrate RDBMS or On-Premise data to EMR Hive, S3, and Amazon Redshift using EMR – Sqoop
This blog post shows how our customers can benefit by using the Apache Sqoop tool. This tool is designed to transfer and import data from a Relational Database Management System (RDBMS) into AWS – EMR Hadoop Distributed File System (HDFS), transform the data in Hadoop, and then export the data into a Data Warehouse (e.g. in Hive or Amazon Redshift).
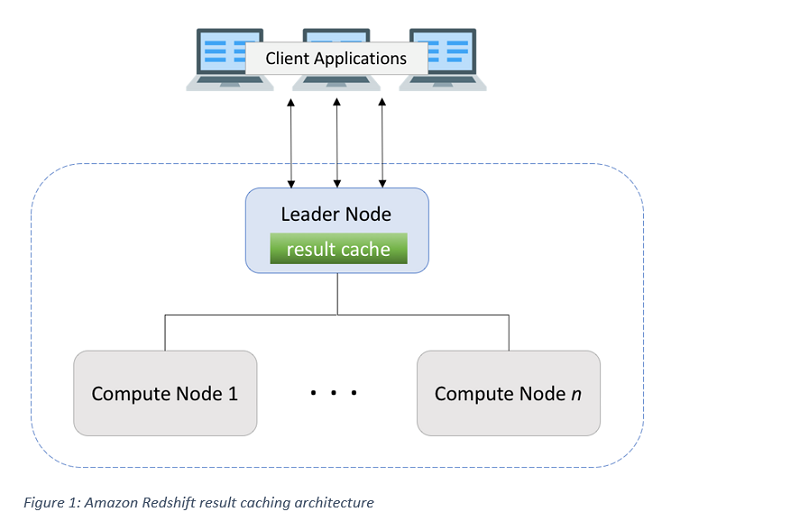
Get sub-second query response times with Amazon Redshift result caching
In this post, we take a look at query result caching in Amazon Redshift. Result caching does exactly what its name implies—it caches the results of a query.

How Goodreads offloads Amazon DynamoDB tables to Amazon S3 and queries them using Amazon Athena
In this post, we show you how to export data from a DynamoDB table, convert it into a more efficient format with AWS Glue, and query the data with Athena. This approach gives you a way to pull insights from your data stored in DynamoDB.
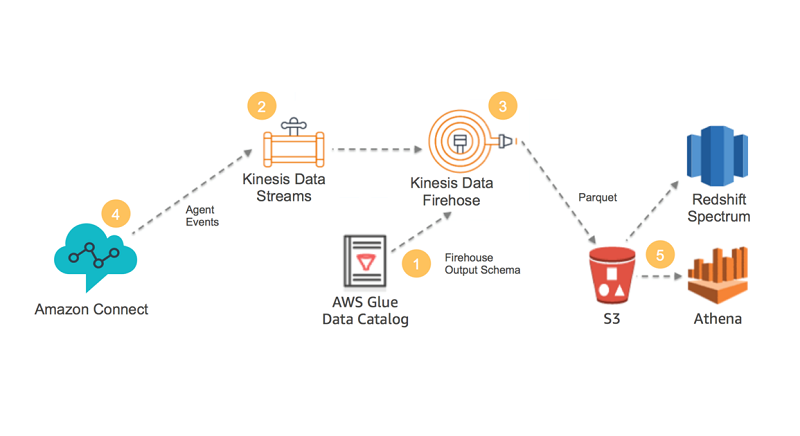
Analyze Apache Parquet optimized data using Amazon Kinesis Data Firehose, Amazon Athena, and Amazon Redshift
Kinesis Data Firehose can now save data to Amazon S3 in Apache Parquet or Apache ORC format. These are optimized columnar formats that are highly recommended for best performance and cost-savings when querying data in S3. This feature directly benefits you if you use Amazon Athena, Amazon Redshift, AWS Glue, Amazon EMR, or any other big data tools that are available from the AWS Partner Network and through the open-source community.

Analyze data in Amazon DynamoDB using Amazon SageMaker for real-time prediction
I’ll describe how to read the DynamoDB backup file format in Data Pipeline, how to convert the objects in S3 to a CSV format that Amazon ML can read, and I’ll show you how to schedule regular exports and transformations using Data Pipeline.
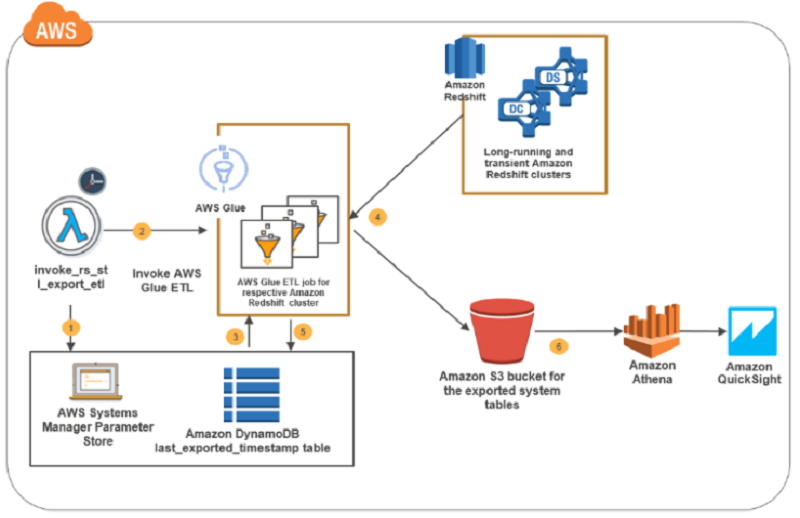
How to retain system tables’ data spanning multiple Amazon Redshift clusters and run cross-cluster diagnostic queries
In this blog post, I present a solution that exports system tables from multiple Amazon Redshift clusters into an Amazon S3 bucket. This solution is serverless, and you can schedule it as frequently as every five minutes. The AWS CloudFormation deployment template that I provide automates the solution setup in your environment. The system tables’ data in the Amazon S3 bucket is partitioned by cluster name and query execution date to enable efficient joins in cross-cluster diagnostic queries.

Getting started: Training resources for Big Data on AWS
Whether you’ve just signed up for your first AWS account or you’ve been with us for some time, there’s always something new to learn as our services evolve to meet the ever-changing needs of our customers. To help ensure you’re set up for success as you build with AWS, we put together this quick reference guide for Big Data training and resources available here on the AWS site.
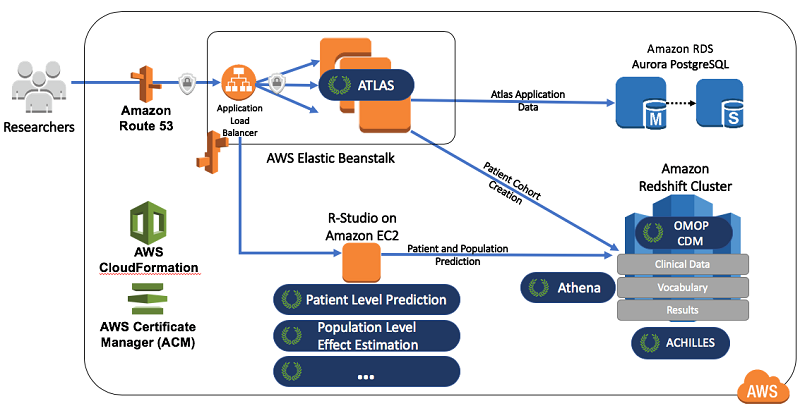
Create data science environments on AWS for health analysis using OHDSI
This blog post demonstrates how to combine some of the OHDSI projects (Atlas, Achilles, WebAPI, and the OMOP Common Data Model) with AWS technologies. By doing so, you can quickly and inexpensively implement a health data science and informatics environment.