AWS Big Data Blog
Category: Amazon Redshift

Federate access to your Amazon Redshift cluster with Active Directory Federation Services (AD FS): Part 2
In the first post of this series, Federating access to your Amazon Redshift cluster with Active Directory: Part 1, you set up Microsoft Active Directory Federation Services (AD FS) and Security Assertion Markup Language (SAML) based authentication and tested the SAML federation using a web browser. In Part 2, you learn to set up an […]

Federate access to your Amazon Redshift cluster with Active Directory Federation Services (AD FS): Part 1
This blog post was reviewed and updated May 2022, to include and comply with recently published Part 3 from this series. Many customers request detailed steps to set up federated single sign-on (SSO) using Microsoft Active Directory Federation Services (AD FS) for Amazon Redshift. In this two-part series, you will find detailed steps to achieve […]
Develop an application migration methodology to modernize your data warehouse with Amazon Redshift
This post demonstrates how to develop a comprehensive, wave-based application migration methodology for a complex project to modernize a traditional MPP data warehouse with Amazon Redshift. It provides best practices and lessons learned by considering business priority, data dependency, workload profiles and existing service level agreements (SLAs).

Restrict Amazon Redshift Spectrum external table access to Amazon Redshift IAM users and groups using role chaining
With Amazon Redshift Spectrum, you can query the data in your Amazon Simple Storage Service (Amazon S3) data lake using a central AWS Glue metastore from your Amazon Redshift cluster. This capability extends your petabyte-scale Amazon Redshift data warehouse to unbounded data storage limits, which allows you to scale to exabytes of data cost-effectively. Like Amazon EMR, you get the benefits of open data formats and inexpensive storage, and you can scale out to thousands of Redshift Spectrum nodes to pull data, filter, project, aggregate, group, and sort. Like Amazon Athena, Redshift Spectrum is serverless and there’s nothing to provision or manage. You only pay $5 for every 1 TB of data scanned. This post discusses how to configure Amazon Redshift security to enable fine grained access control using role chaining to achieve high-fidelity user-based permission management.
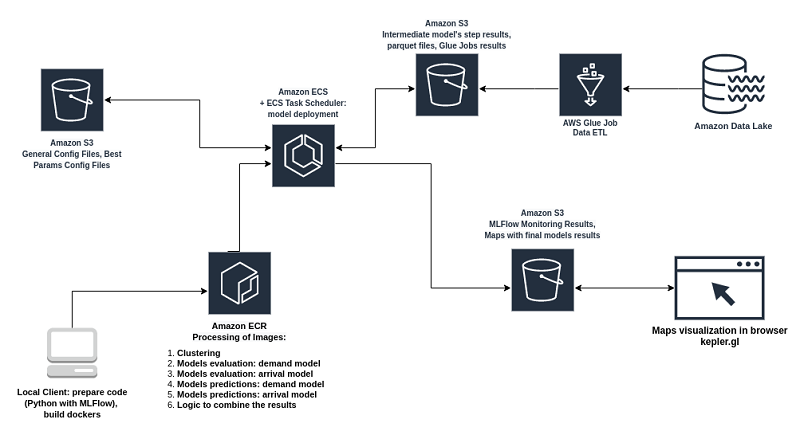
How Wind Mobility built a serverless data architecture
We parse through millions of scooter and user events generated daily (over 300 events per second) to extract actionable insight. We selected AWS Glue to perform this task. Our primary ETL job reads the newly added raw event data from Amazon S3, processes it using Apache Spark, and writes the results to our Amazon Redshift data warehouse. AWS Glue plays a critical role in our ability to scale on demand. After careful evaluation and testing, we concluded that AWS Glue ETL jobs meet all our needs and free us from procuring and managing infrastructure.

Process data with varying data ingestion frequencies using AWS Glue job bookmarks
We often have data processing requirements in which we need to merge multiple datasets with varying data ingestion frequencies. Some of these datasets are ingested one time in full, received infrequently, and always used in their entirety, whereas other datasets are incremental, received at certain intervals, and joined with the full datasets to generate output. To address this requirement, this post demonstrates how to build an extract, transform, and load (ETL) pipeline using AWS Glue.

Extend your Amazon Redshift Data Warehouse to your Data Lake
Amazon Redshift is a fast, fully managed, cloud-native data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence tools. Many companies today are using Amazon Redshift to analyze data and perform various transformations on the data. However, as data continues to grow and become […]
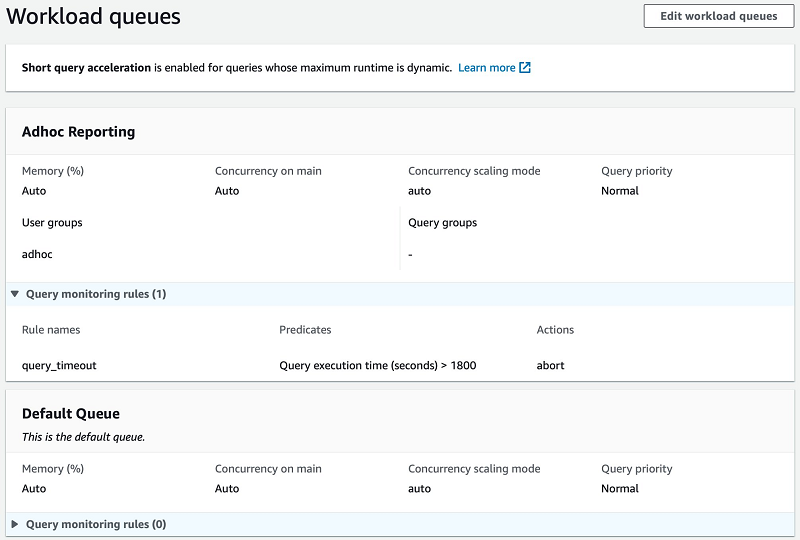
Best practices for Amazon Redshift Federated Query
This post discusses 10 best practices to help you maximize the benefits of Federated Query when you have large federated data sets, when your federated queries retrieve large volumes of data, or when you have many Redshift users accessing federated data sets. These techniques are not necessary for general usage of Federated Query. They are intended for advanced users who want to make the most of this exciting feature.
Monitor and control the storage space of a schema with quotas with Amazon Redshift
Many organizations are moving toward self-service analytics, where different personas create their own insights on the evolved volume, variety, and velocity of data to keep up with the acceleration of business. This data democratization creates the need to enforce data governance, control cost, and prevent data mismanagement. Controlling the storage quota of different personas is a significant challenge for data governance and data storage operation. This post shows you how to set up Amazon Redshift storage quotas by different personas.
Migrating your Netezza data warehouse to Amazon Redshift
With IBM announcing Netezza reaching end-of-life, you’re faced with the prospect of having to migrate your data and workloads off your analytics appliance. For some, this presents an opportunity to transition to the cloud.
Enter Amazon Redshift.