AWS Big Data Blog
Category: Amazon Redshift

Running queries securely from the same VPC where an Amazon Redshift cluster is running
Customers who don’t need to set up a VPN or a private connection to AWS often use public endpoints to access AWS. Although this is acceptable for testing out the services, most production workloads need a secure connection to their VPC on AWS. If you’re running your production data warehouse on Amazon Redshift, you can […]

Scheduling SQL queries on your Amazon Redshift data warehouse
Amazon Redshift is the most popular cloud data warehouse today, with tens of thousands of customers collectively processing over 2 exabytes of data on Amazon Redshift daily. Amazon Redshift is fully managed, scalable, secure, and integrates seamlessly with your data lake. In this post, we discuss how to set up and use the new query […]
Dream11’s journey to building their Data Highway on AWS
This is a guest post co-authored by Pradip Thoke of Dream11. In their own words, “Dream11, the flagship brand of Dream Sports, is India’s biggest fantasy sports platform, with more than 100 million users. We have infused the latest technologies of analytics, machine learning, social networks, and media technologies to enhance our users’ experience. Dream11 […]

Building high-quality benchmark tests for Amazon Redshift using Apache JMeter
Updated April 2021 to offer more Apache JMeter tips, and highlight some capabilities in the newer version of Apache JMeter. In the introductory post of this series, we discussed benchmarking benefits and best practices common across different open-source benchmarking tools. As a reminder of why benchmarking is important, Amazon Redshift allows you to scale storage […]
How FanDuel Group secures personally identifiable information in a data lake using AWS Lake Formation
This post is co-written with Damian Grech from FanDuel FanDuel Group is an innovative sports-tech entertainment company that is changing the way consumers engage with their favorite sports, teams, and leagues. The premier gaming destination in the US, FanDuel Group consists of a portfolio of leading brands across gaming, sports betting, daily fantasy sports, advance-deposit […]

Sharing Amazon Redshift data securely across Amazon Redshift clusters for workload isolation
Amazon Redshift data sharing allows for a secure and easy way to share live data for read purposes across Amazon Redshift clusters. Amazon Redshift is a fast, fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. It allows […]
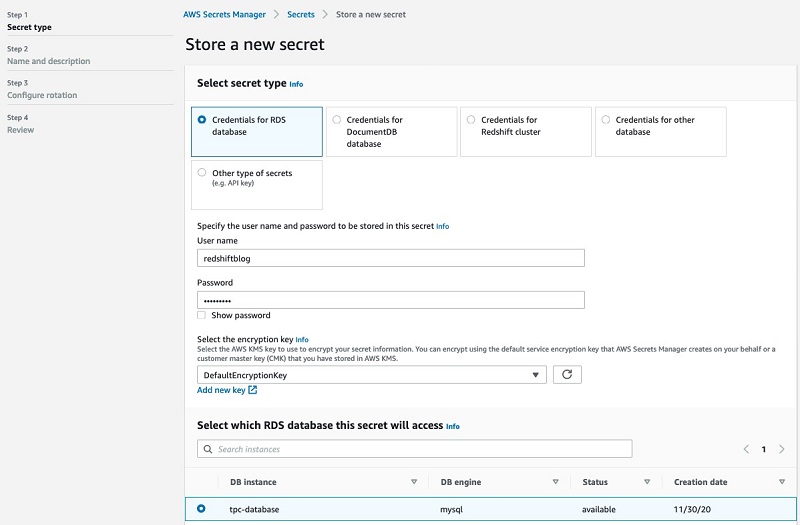
Announcing Amazon Redshift federated querying to Amazon Aurora MySQL and Amazon RDS for MySQL
Since we launched Amazon Redshift as a cloud data warehouse service more than seven years ago, tens of thousands of customers have built analytics workloads using it. We’re always listening to your feedback and, in April 2020, we announced general availability for federated querying to Amazon Aurora PostgreSQL and Amazon Relational Database Service (Amazon RDS) […]
Building high-quality benchmark tests for Amazon Redshift using SQLWorkbench and psql
In the introductory post of this series, we discussed benchmarking benefits and best practices common across different open-source benchmarking tools. In this post, we discuss benchmarking Amazon Redshift with the SQLWorkbench and psql open-source tools. Let’s first start with a quick review of the introductory installment. When you use Amazon Redshift to scale compute and […]
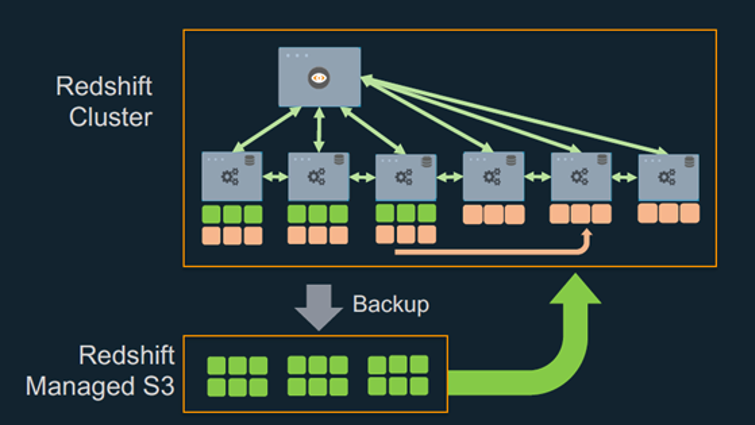
Getting the most out of your analytics stack with Amazon Redshift
Analytics environments today have seen an exponential growth in the volume of data being stored. In addition, analytics use cases have expanded, and data users want access to all their data as soon as possible. The challenge for IT organizations is how to scale your infrastructure, manage performance, and optimize for cost while meeting these […]
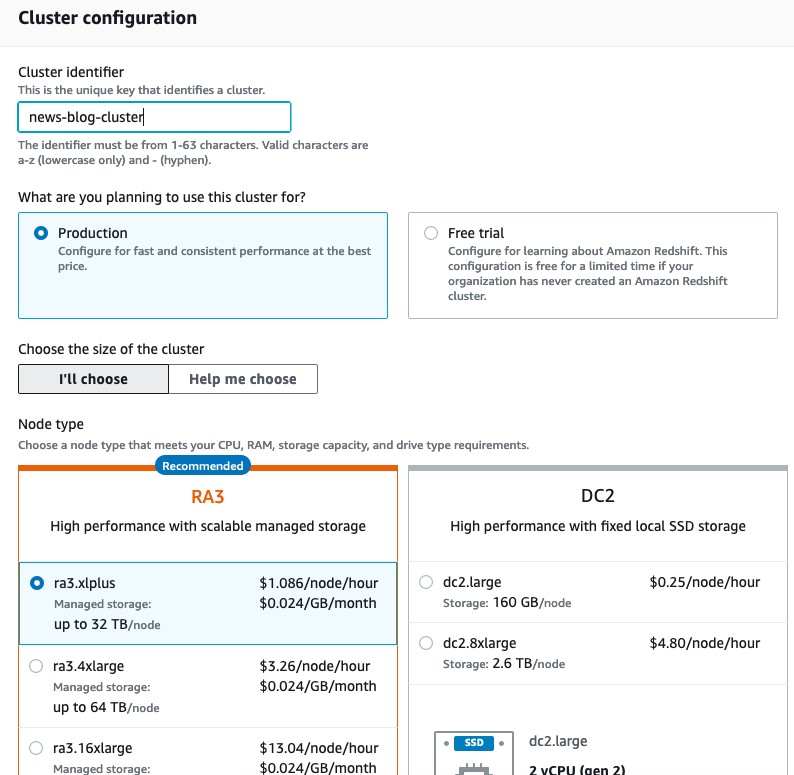
Introducing Amazon Redshift RA3.xlplus nodes with managed storage
Since we launched Amazon Redshift as a cloud data warehouse service more than seven years ago, tens of thousands of customers have built analytics workloads using it. We’re always listening to your feedback and, in December 2019, we announced our third-generation RA3 node type to provide you the ability to scale and pay for compute […]