AWS Big Data Blog
Category: Amazon Redshift

Accelerate your data warehouse migration to Amazon Redshift – Part 2
This is the second post in a multi-part series. We’re excited to shared dozens of new features to automate your schema conversion; preserve your investment in existing scripts, reports, and applications; accelerate query performance; and potentially reduce your overall cost to migrate to Amazon Redshift. Check out all posts in this series: Accelerate your data […]
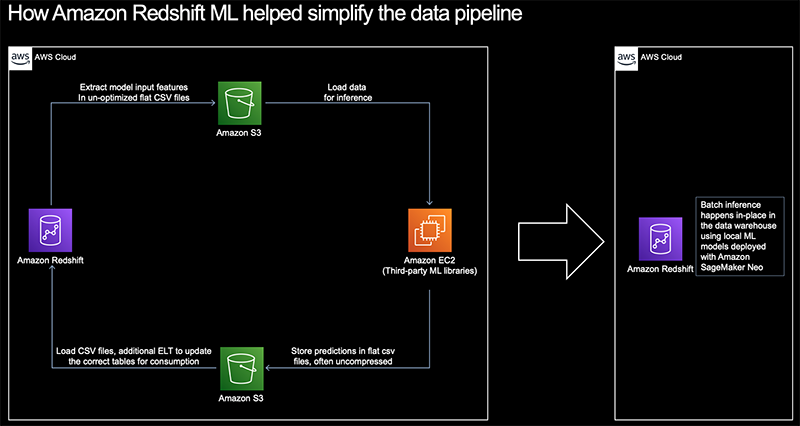
How Jobcase is using Amazon Redshift ML to recommend job search content at scale
This post is co-written with Clay Martin and Ajay Joshi from Jobcase as the lead authors. Jobcase is an online community dedicated to empowering and advocating for the world’s workers. We’re the third-largest destination for job search in the United States, and connect millions of Jobcasers to relevant job opportunities, companies, and other resources on […]
Case-insensitive collation support for string processing in Amazon Redshift
Amazon Redshift is a fast, fully managed, cloud-native data warehouse. Tens of thousands of customers have successfully migrated their workloads to Amazon Redshift. We hear from customers that they need case-insensitive collation for strings in Amazon Redshift in order to maintain the same functionality and meet their performance goals when they migrate their existing workloads […]

Data preparation using Amazon Redshift with AWS Glue DataBrew
July 2023: This post was reviewed for accuracy. With AWS Glue DataBrew, data analysts and data scientists can easily access and visually explore any amount of data across their organization directly from their Amazon Simple Storage Service (Amazon S3) data lake, Amazon Redshift data warehouse, Amazon Aurora, and other Amazon Relational Database Service (Amazon RDS) databases. You can choose from over […]

Work with semistructured data using Amazon Redshift SUPER
With the new SUPER data type and the PartiQL language, Amazon Redshift expands data warehouse capabilities to natively ingest, store, transform, and analyze semi-structured data. Semi-structured data (such as weblogs and sensor data) fall under the category of data that doesn’t conform to a rigid schema expected in relational databases. It often contain complex values […]
Amazon Redshift identity federation with multi-factor authentication
July 2023: This post was reviewed for accuracy. Password-based access control alone is not considered secure enough, and many organizations are adopting multi-factor authentication (MFA) and single sign-on (SSO) as a de facto standard to prevent unauthorized access to systems and data. SSO frees up time and resources for both administrators and end users from […]
Improve query performance using AWS Glue partition indexes
While creating data lakes on the cloud, the data catalog is crucial to centralize metadata and make the data visible, searchable, and queryable for users. With the recent exponential growth of data volume, it becomes much more important to optimize data layout and maintain the metadata on cloud storage to keep the value of data […]
How Amazon Customer Service lowered Amazon Redshift costs and improved performance using RA3 nodes
Amazon Customer Service solves exciting and challenging customer care problems for Amazon.com, the world’s largest online retailer. In 2021, the Amazon Customer Service Technology team upgraded its dense-compute nodes (dc2.8xlarge) to the Amazon Redshift RA3 instance family (ra3.16xlarge). Moving to the most advanced Amazon Redshift architecture enabled the team to reduce its infrastructure costs, improve […]

Simplify Amazon Redshift RA3 migration evaluation with Simple Replay utility
Amazon Redshift is a fast, fully managed, widely popular cloud data warehouse that allows you to process exabytes of data across your data warehouse, operational database, and data lake using standard SQL. It offers different node types to accommodate various workloads; you can choose from RA3, DC2, and DS2 depending on your requirements. RA3 is […]
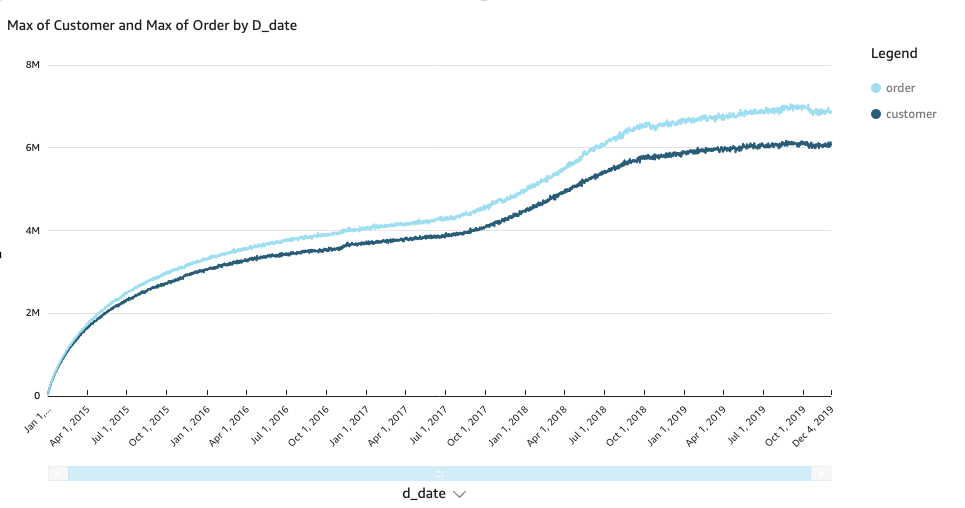
Use HyperLogLog for trend analysis with Amazon Redshift
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL. Amazon Redshift offers up to three times better price performance than any other cloud data warehouse. Tens of thousands of customers use Amazon Redshift to process exabytes of […]