AWS Big Data Blog
Category: Amazon Redshift
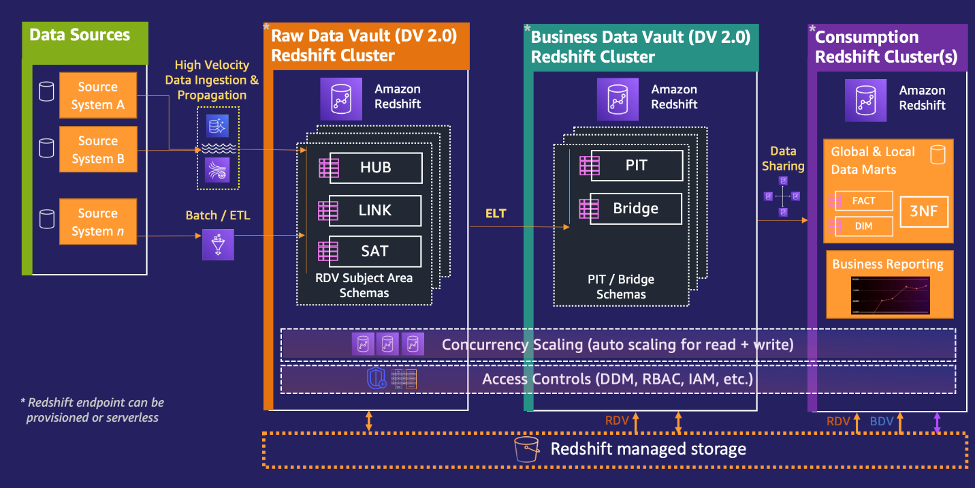
Power enterprise-grade Data Vaults with Amazon Redshift – Part 2
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x better price-performance than any other cloud data warehouses. As with all […]

What’s cooking with Amazon Redshift at AWS re:Invent 2023
AWS re:Invent is a powerhouse of a learning event and every time I have attended, I’ve been amazed at its scale and impact. There are keynotes packed with announcements from AWS leaders, training and certification opportunities, access to more than 2,000 technical sessions, an elaborate expo, executive summits, after-hours events, demos, and much more. The […]

How Wallapop improved performance of analytics workloads with Amazon Redshift Serverless and data sharing
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it straightforward and cost-effective to analyze all your data at petabyte scale, using standard SQL and your existing business intelligence (BI) tools. Today, tens of thousands of customers run business-critical workloads on Amazon Redshift. Amazon Redshift Serverless makes it effortless to run and […]

How Gameskraft uses Amazon Redshift data sharing to support growing analytics workloads
This post is co-written by Anshuman Varshney, Technical Lead at Gameskraft. Gameskraft is one of India’s leading online gaming companies, offering gaming experiences across a variety of categories such as rummy, ludo, poker, and many more under the brands RummyCulture, Ludo Culture, Pocket52, and Playship. Gameskraft holds the Guinness World Record for organizing the world’s […]

Simplifying data processing at Capitec with Amazon Redshift integration for Apache Spark
This post is co-written with Preshen Goobiah and Johan Olivier from Capitec. Apache Spark is a widely-used open source distributed processing system renowned for handling large-scale data workloads. It finds frequent application among Spark developers working with Amazon EMR, Amazon SageMaker, AWS Glue and custom Spark applications. Amazon Redshift offers seamless integration with Apache Spark, […]

Create a modern data platform using the Data Build Tool (dbt) in the AWS Cloud
Building a data platform involves various approaches, each with its unique blend of complexities and solutions. A modern data platform entails maintaining data across multiple layers, targeting diverse platform capabilities like high performance, ease of development, cost-effectiveness, and DataOps features such as CI/CD, lineage, and unit testing. In this post, we delve into a case […]

How Gilead used Amazon Redshift to quickly and cost-effectively load third-party medical claims data
This post was co-written with Rajiv Arora, Director of Data Science Platform at Gilead Life Sciences. Gilead Sciences, Inc. is a biopharmaceutical company committed to advancing innovative medicines to prevent and treat life-threatening diseases, including HIV, viral hepatitis, inflammation, and cancer. A leader in virology, Gilead historically relied on these drugs for growth but now […]

Implement model versioning with Amazon Redshift ML
Amazon Redshift ML allows data analysts, developers, and data scientists to train machine learning (ML) models using SQL. In previous posts, we demonstrated how you can use the automatic model training capability of Redshift ML to train classification and regression models. Redshift ML allows you to create a model using SQL and specify your algorithm, […]

Amazon Redshift: Lower price, higher performance
Like virtually all customers, you want to spend as little as possible while getting the best possible performance. This means you need to pay attention to price-performance. With Amazon Redshift, you can have your cake and eat it too! Amazon Redshift delivers up to 4.9 times lower cost per user and up to 7.9 times […]

Create, train, and deploy Amazon Redshift ML model integrating features from Amazon SageMaker Feature Store
Amazon Redshift is a fast, petabyte-scale, cloud data warehouse that tens of thousands of customers rely on to power their analytics workloads. Data analysts and database developers want to use this data to train machine learning (ML) models, which can then be used to generate insights on new data for use cases such as forecasting […]