AWS Big Data Blog
Category: Amazon Kinesis
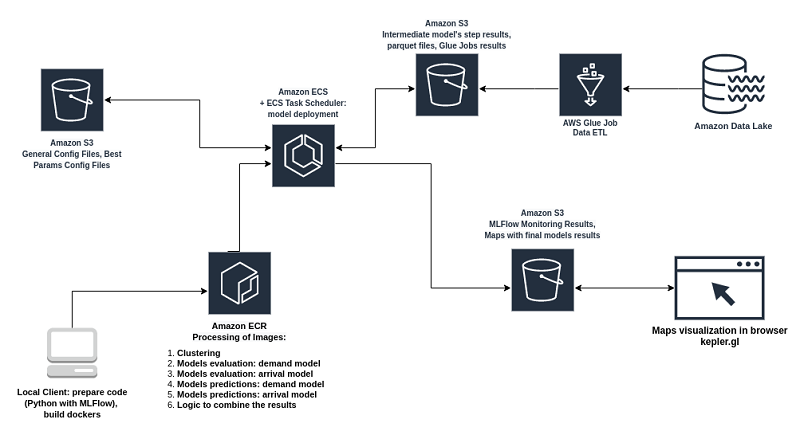
How Wind Mobility built a serverless data architecture
We parse through millions of scooter and user events generated daily (over 300 events per second) to extract actionable insight. We selected AWS Glue to perform this task. Our primary ETL job reads the newly added raw event data from Amazon S3, processes it using Apache Spark, and writes the results to our Amazon Redshift data warehouse. AWS Glue plays a critical role in our ability to scale on demand. After careful evaluation and testing, we concluded that AWS Glue ETL jobs meet all our needs and free us from procuring and managing infrastructure.
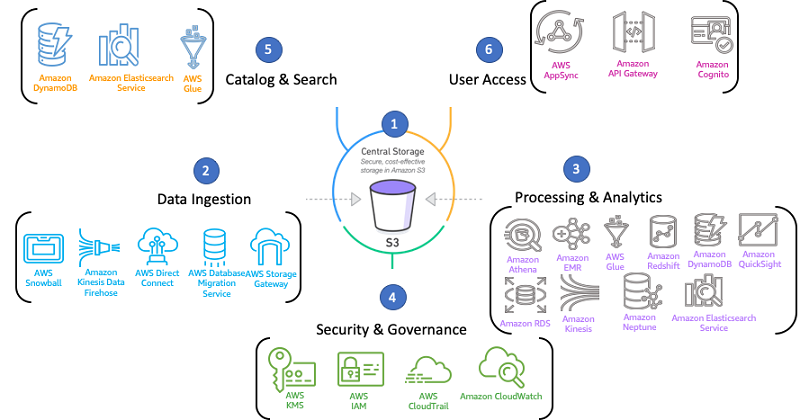
Build an AWS Well-Architected environment with the Analytics Lens
Building a modern data platform on AWS enables you to collect data of all types, store it in a central, secure repository, and analyze it with purpose-built tools. Yet you may be unsure of how to get started and the impact of certain design decisions. To address the need to provide advice tailored to specific technology and application domains, AWS added the concept of well-architected lenses 2017. AWS now is happy to announce the Analytics Lens for the AWS Well-Architected Framework. This post provides an introduction of its purpose, topics covered, common scenarios, and services included.

Ingest streaming data into Amazon OpenSearch Service within the privacy of your VPC with Amazon Data Firehose
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Today we are adding a new Amazon Data Firehose feature to set up VPC delivery to your […]

Build a cloud-native network performance analytics solution on AWS for wireless service providers
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. This post demonstrates a serverless, cloud-based approach to building a network performance analytics solution using AWS services that can provide flexibility and performance while keeping costs under control with pay-per-use AWS services. […]

Streaming ETL with Apache Flink and Amazon Kinesis Data Analytics
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Most businesses generate data […]
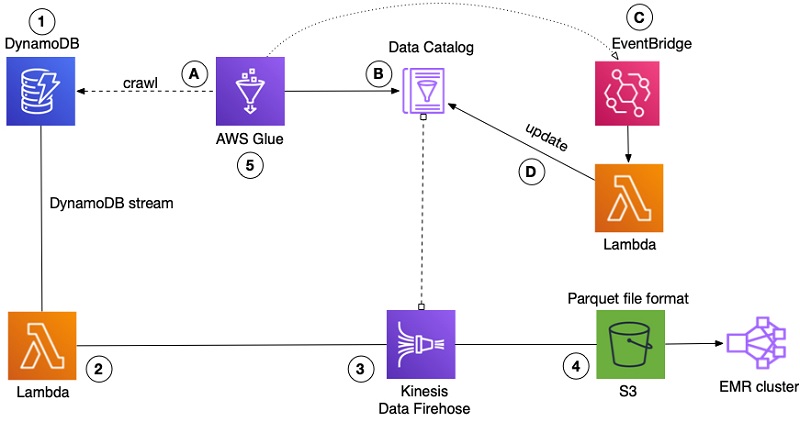
How FactSet automated exporting data from Amazon DynamoDB to Amazon S3 Parquet to build a data analytics platform
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. This is a guest post by Arvind Godbole, Lead Software Engineer with FactSet and Tarik Makota, AWS Principal Solutions Architect. In their own words “FactSet creates flexible, open data and software solutions […]

Under the hood: Scaling your Kinesis data streams
Real-time delivery of data and insights enables businesses to pivot quickly in response to changes in demand, user engagement, and infrastructure events, among many others. Amazon Kinesis offers a managed service that lets you focus on building your applications, rather than managing infrastructure. Scalability is provided out-of-the-box, allowing you to ingest and process gigabytes of […]

Optimize downstream data processing with Amazon Data Firehose and Amazon EMR running Apache Spark
This blog post shows how to use Amazon Kinesis Data Firehose to merge many small messages into larger messages for delivery to Amazon S3, which results in faster processing with Amazon EMR running Spark. This post also shows how to read the compressed files using Apache Spark that are in Amazon S3, which does not have a proper file name extension and store back in Amazon S3 in parquet format.

Amazon Data Firehose custom prefixes for Amazon S3 objects
July 2024: This post was reviewed and updated for accuracy. In February 2019, Amazon Web Services (AWS) announced a new feature in Amazon Data Firehose called Custom Prefixes for Amazon S3 Objects. It lets customers specify a custom expression for the Amazon S3 prefix where data records are delivered. Previously, Firehose allowed only specifying a […]

Build and run streaming applications with Apache Flink and Amazon Kinesis Data Analytics for Java Applications
In this post, we discuss how you can use Apache Flink and Amazon Kinesis Data Analytics for Java Applications to address these challenges. We explore how to build a reliable, scalable, and highly available streaming architecture based on managed services that substantially reduce the operational overhead compared to a self-managed environment.