AWS Big Data Blog
Category: Amazon EMR

Running sparklyr – RStudio’s R Interface to Spark on Amazon EMR
This post was last updated July 7th, 2021 (original version by Tom Zeng). The Sparklyr package by RStudio has made processing big data in R a lot easier. Sparklyr is an R interface to Spark, it allows using Spark as the backend for dplyr – one of the most popular data manipulation packages. Sparklyr also […]

How Eliza Corporation Moved Healthcare Data to the Cloud
In this post, I discuss some of the practical challenges faced during the implementation of the data lake for Eliza and the corresponding details of the ways we solved these issues with AWS. The challenges we faced involved the variety of data and a need for a common view of the data.

Building Event-Driven Batch Analytics on AWS
In this post, I walk you through an architectural approach as well as a sample implementation on how to collect, process, and analyze data for event-driven applications in AWS.
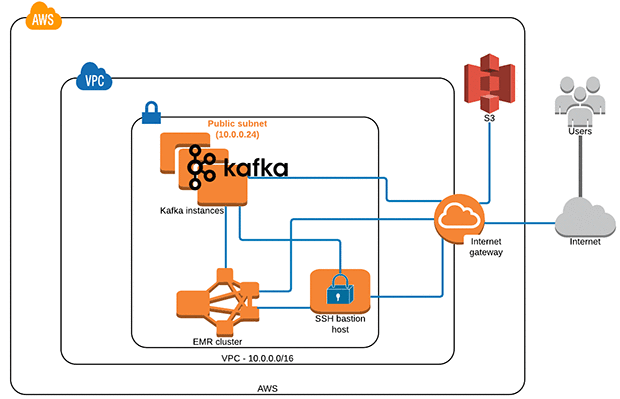
Real-time Stream Processing Using Apache Spark Streaming and Apache Kafka on AWS
This post demonstrates how to set up Apache Kafka on EC2, use Spark Streaming on EMR to process data coming in to Apache Kafka topics, and query streaming data using Spark SQL on EMR.

Amazon EMR-DynamoDB Connector Repository on AWSLabs GitHub
Amazon Web Services is excited to announce that the Amazon EMR-DynamoDB Connector is now open-source. The code you see in the GitHub repository is exactly what is available on your EMR cluster, making it easier to build applications with this component.

Encrypt Data At-Rest and In-Flight on Amazon EMR with Security Configurations
ustomers running analytics, stream processing, machine learning, and ETL workloads on personally identifiable information, health information, and financial data have strict requirements for encryption of data at-rest and in-transit. The Apache Spark and Hadoop ecosystems lend themselves to these big data use cases, and customers have asked us to provide a quick and easy way to encrypt data at-rest and data in-transit between nodes in each execution framework.
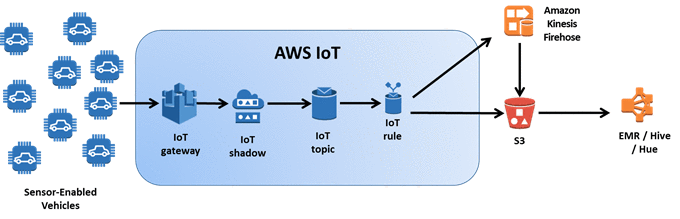
Integrating IoT Events into Your Analytic Platform
AWS IoT makes it easy to integrate and control your devices from other AWS services for even more powerful IoT applications. In particular, IoT provides tight integration with AWS Lambda, Amazon Kinesis, Amazon S3, Amazon Machine Learning, Amazon DynamoDB, Amazon CloudWatch, and Amazon OpenSearch Service.

Processing VPC Flow Logs with Amazon EMR
In this post, I show you how to gain valuable insight into your network by using Amazon EMR and Amazon VPC Flow Logs. The walkthrough implements a pattern often found in network equipment called ‘Top Talkers’, an ordered list of the heaviest network users, but the model can also be used for many other types of network analysis.

Building and Deploying Custom Applications with Apache Bigtop and Amazon EMR
This post shows you how to build a custom application for EMR for Apache Bigtop-based releases 4.x and greater. EMR nodes are based on the Amazon Linux AMI, so I will deploy on RPM packages and use Elasticsearch as the example application.

Use Spark 2.0, Hive 2.1 on Tez, and the latest from the Hadoop ecosystem on Amazon EMR release 5.0
Jonathan Fritz is a Senior Product Manager for Amazon EMR We are excited to launch Amazon EMR release 5.0 today, giving customers the latest versions of 16 supported open-source applications in the big data ecosystem, including new major versions of Spark and Hive. Almost exactly a year ago, we shipped release 4.0, which brought significant […]