AWS Big Data Blog
Category: Amazon EMR

Using SaltStack to Run Commands in Parallel on Amazon EMR
Miguel Tormo is a Big Data Support Engineer in AWS Premium Support Amazon EMR provides a managed Hadoop framework that makes it easy, fast, and cost-effective to process vast amounts of data across dynamically scalable Amazon EC2 instances. Amazon EMR defines three types of nodes: master node, core nodes, and task nodes. It’s common to […]
Implementing Authorization and Auditing using Apache Ranger on Amazon EMR
Updated 3/30/2022: Amazon EMR has announced official support of Apache Ranger (link). Open-source plugin support will not be maintained moving forward and compatibility with latest versions will not be tested. We recommend customers to move to the Amazon EMR support for Apache Ranger. Ranger Presto plugin support on EMR has been deprecated. Updated 12/03/2020: Support for […]

Low-Latency Access on Trillions of Records: FINRA’s Architecture Using Apache HBase on Amazon EMR with Amazon S3
John Hitchingham is Director of Performance Engineering at FINRA The Financial Industry Regulatory Authority (FINRA) is a private sector regulator responsible for analyzing 99% of the equities and 65% of the option activity in the US. In order to look for fraud, market manipulation, insider trading, and abuse, FINRA’s technology group has developed a robust […]
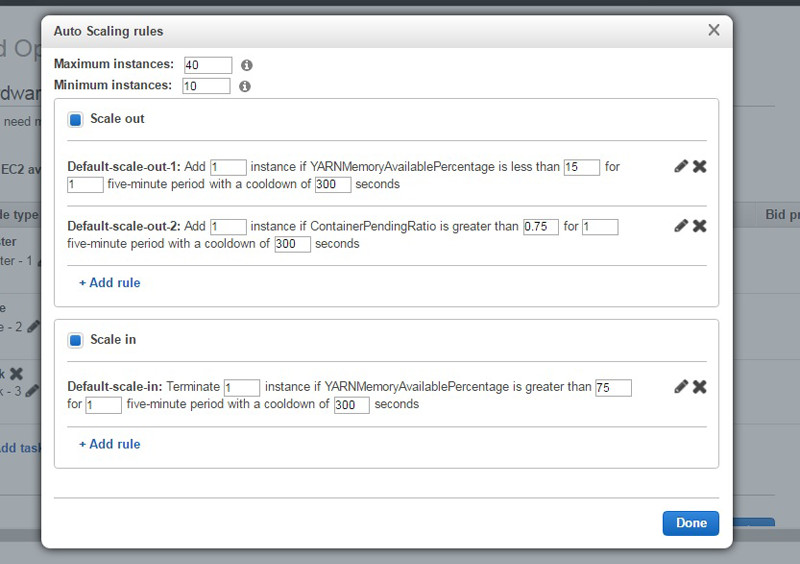
Dynamically Scale Applications on Amazon EMR with Auto Scaling
Jonathan Fritz is a Senior Product Manager for Amazon EMR Customers running Apache Spark, Presto, and the Apache Hadoop ecosystem take advantage of Amazon EMR’s elasticity to save costs by terminating clusters after workflows are complete and resizing clusters with low-cost Amazon EC2 Spot Instances. For instance, customers can create clusters for daily ETL or machine learning […]
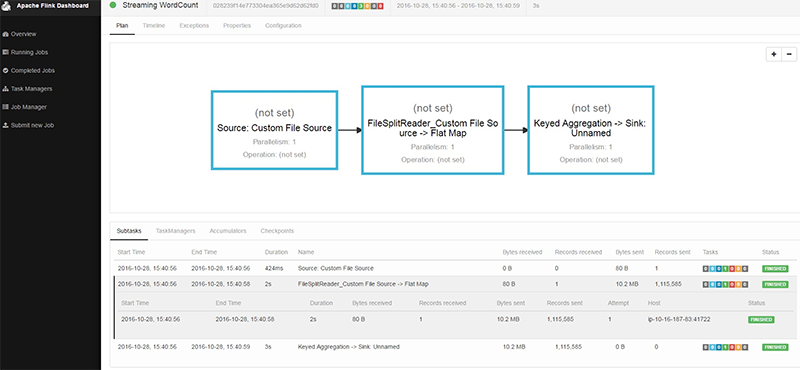
Use Apache Flink on Amazon EMR
Today we are making it even easier to run Flink on AWS as it is now natively supported in Amazon EMR 5.1.0. EMR supports running Flink-on-YARN so you can create either a long-running cluster that accepts multiple jobs or a short-running Flink session in a transient cluster that helps reduce your costs by only charging you for the time that you use.

Running sparklyr – RStudio’s R Interface to Spark on Amazon EMR
This post was last updated July 7th, 2021 (original version by Tom Zeng). The Sparklyr package by RStudio has made processing big data in R a lot easier. Sparklyr is an R interface to Spark, it allows using Spark as the backend for dplyr – one of the most popular data manipulation packages. Sparklyr also […]

How Eliza Corporation Moved Healthcare Data to the Cloud
In this post, I discuss some of the practical challenges faced during the implementation of the data lake for Eliza and the corresponding details of the ways we solved these issues with AWS. The challenges we faced involved the variety of data and a need for a common view of the data.

Building Event-Driven Batch Analytics on AWS
In this post, I walk you through an architectural approach as well as a sample implementation on how to collect, process, and analyze data for event-driven applications in AWS.
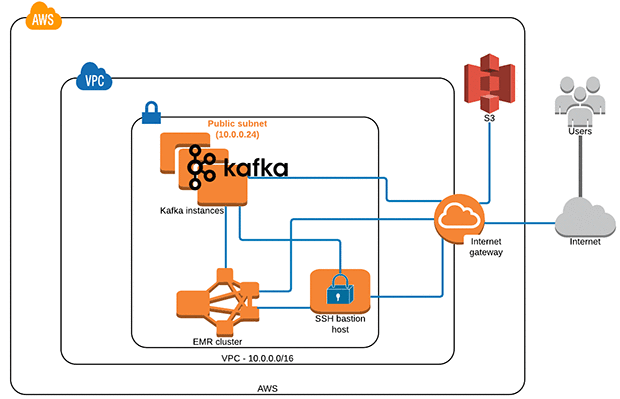
Real-time Stream Processing Using Apache Spark Streaming and Apache Kafka on AWS
This post demonstrates how to set up Apache Kafka on EC2, use Spark Streaming on EMR to process data coming in to Apache Kafka topics, and query streaming data using Spark SQL on EMR.

Amazon EMR-DynamoDB Connector Repository on AWSLabs GitHub
Amazon Web Services is excited to announce that the Amazon EMR-DynamoDB Connector is now open-source. The code you see in the GitHub repository is exactly what is available on your EMR cluster, making it easier to build applications with this component.