AWS Big Data Blog
Category: Amazon EMR
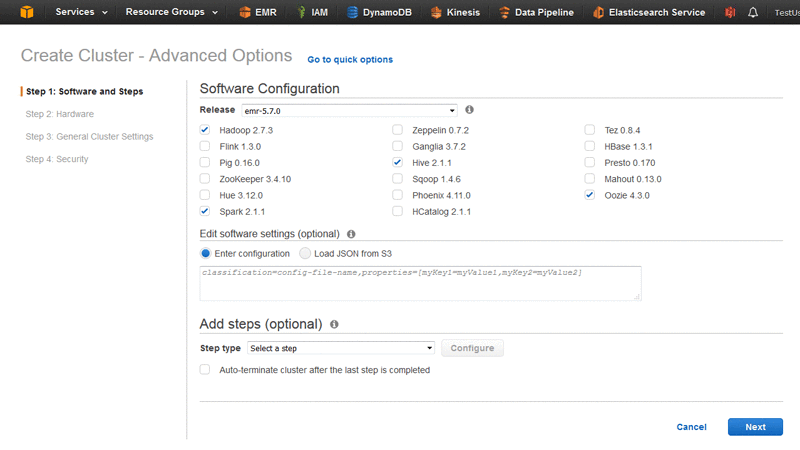
Run Common Data Science Packages on Anaconda and Oozie with Amazon EMR
In the world of data science, users must often sacrifice cluster set-up time to allow for complex usability scenarios. Amazon EMR allows data scientists to spin up complex cluster configurations easily, and to be up and running with complex queries in a matter of minutes. Data scientists often use scheduling applications such as Oozie to […]

Setting up Read Replica Clusters with HBase on Amazon S3
Many customers have taken advantage of the numerous benefits of running Apache HBase on Amazon S3 for data storage, including lower costs, data durability, and easier scalability. Customers such as FINRA have lowered their costs by 60% by moving to an HBase on S3 architecture along with the numerous operational benefits that come with decoupling […]

Seven Tips for Using S3DistCp on Amazon EMR to Move Data Efficiently Between HDFS and Amazon S3
Although it’s common for Amazon EMR customers to process data directly in Amazon S3, there are occasions where you might want to copy data from S3 to the Hadoop Distributed File System (HDFS) on your Amazon EMR cluster. Additionally, you might have a use case that requires moving large amounts of data between buckets or regions. In these use cases, large datasets are too big for a simple copy operation.
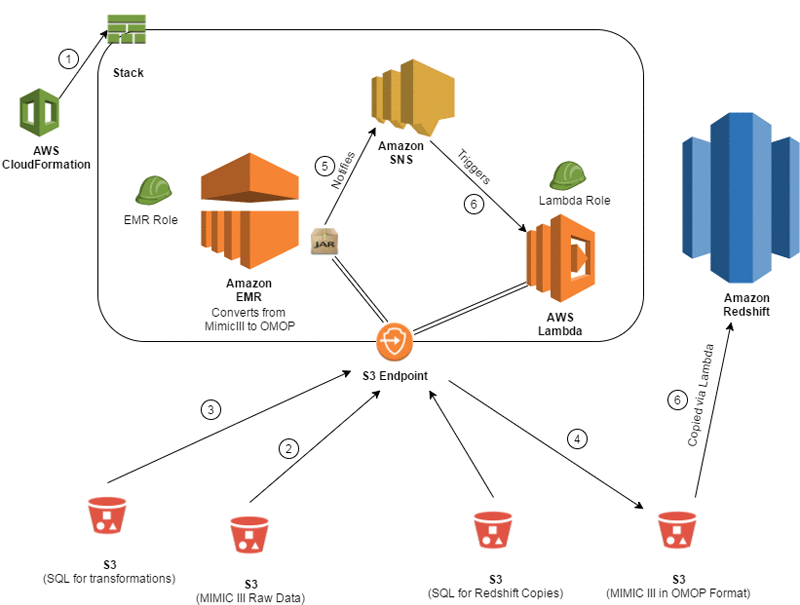
Build a Healthcare Data Warehouse Using Amazon EMR, Amazon Redshift, AWS Lambda, and OMOP
In the healthcare field, data comes in all shapes and sizes. Despite efforts to standardize terminology, some concepts (e.g., blood glucose) are still often depicted in different ways. This post demonstrates how to convert an openly available dataset called MIMIC-III, which consists of de-identified medical data for about 40,000 patients, into an open source data […]

Tips for Migrating to Apache HBase on Amazon S3 from HDFS
Starting with Amazon EMR 5.2.0, you have the option to run Apache HBase on Amazon S3. Running HBase on S3 gives you several added benefits, including lower costs, data durability, and easier scalability. HBase provides several options that you can use to migrate and back up HBase tables. The steps to migrate to HBase on […]
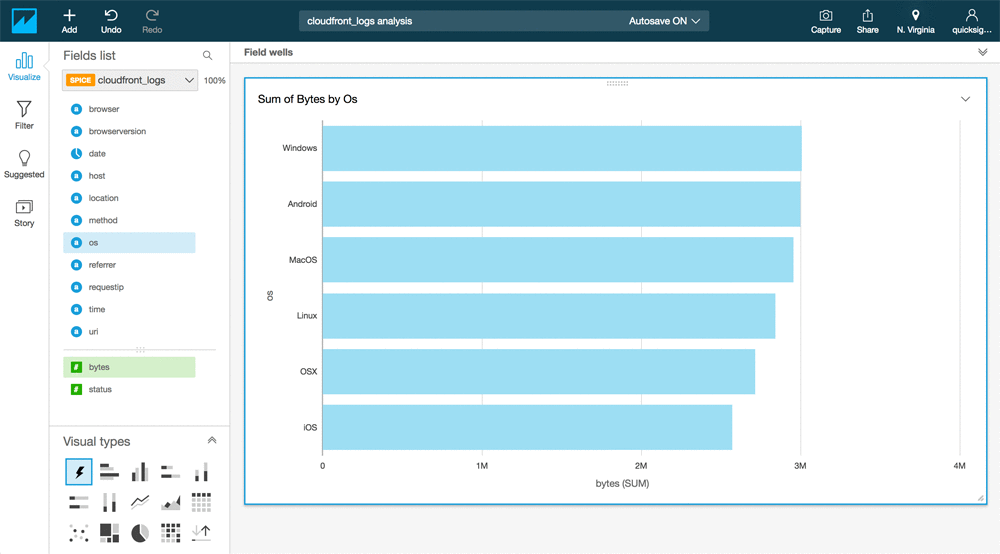
Visualize Big Data with Amazon QuickSight, Presto, and Apache Spark on Amazon EMR
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Last December, we introduced the Amazon Athena connector in Amazon QuickSight, in the Derive Insights from IoT in Minutes using AWS IoT, Amazon Kinesis Firehose, Amazon Athena, and Amazon QuickSight post. The […]

Build a Real-time Stream Processing Pipeline with Apache Flink on AWS
NOTE: As of November 2018, you can run Apache Flink programs with Amazon Kinesis Analytics for Java Applications in a fully managed environment. You can find further details in a new blog post on the AWS Big Data Blog and in this Github repository. ————————– September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. […]

Securely Analyze Data from Another AWS Account with EMRFS
Sometimes, data to be analyzed is spread across buckets owned by different accounts. In order to ensure data security, appropriate credentials management needs to be in place. This is especially true for large enterprises storing data in different Amazon S3 buckets for different departments. For example, a customer service department may need access to data […]

Meet the Amazon EMR Team this Friday at a Tech Talk & Networking Event in Mountain View
Want to change the world with Big Data and Analytics? Come join us on the Amazon EMR team in Amazon Web Services! Meet the Amazon EMR team this Friday April 7th from 5:00 – 7:30 PM at Michael’s at Shoreline in Mountain View. We’ll feature short tech talks by EMR leadership who will talk about the past, […]
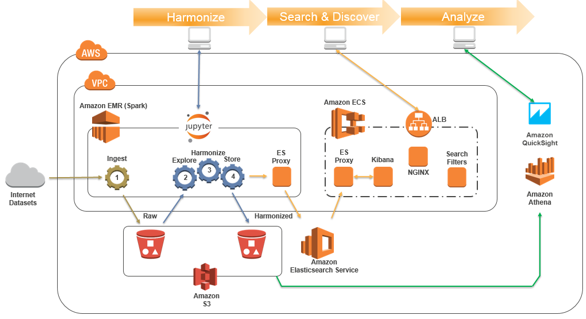
Harmonize, Search, and Analyze Loosely Coupled Datasets on AWS
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. You have come up with an exciting hypothesis, and now you are keen to find and analyze as much data as possible to prove (or refute) it. There are many datasets that might be applicable, but they have been created […]